


Parameter-efficient fine-tuning (PEFT) methods have become essential in machine learning. They allow large models to adapt to new tasks without extensive computational resources. By fine-tuning only a small subset of parameters while keeping most of the model frozen, PEFT methods aim to make the adaptation process more efficient and accessible. This approach is crucial for deploying large foundational models, otherwise constrained by their high computational costs and extensive parameter counts.
The core issue tackled in the research is the noticeable performance gap between low-rank adaptation methods, such as LoRA, and the full fine-tuning of machine learning models. Although LoRA, which stands for Low-Rank Adaptation, is known for its efficiency, it often falls short in performance compared to fully fine-tuned models. This discrepancy limits the broader application of LoRA across various domains where high performance is critical. The challenge lies in making LoRA as effective as full fine-tuning while retaining its parameter-efficient advantages.
Researchers have explored various techniques. Current PEFT methods include adapter tuning and prompt tuning. Adapter tuning involves inserting small, trainable modules, or adapters, into specific layers of a model. These adapters are fine-tuned while the rest of the model remains frozen, significantly reducing the memory footprint required for fine-tuning. On the other hand, prompt tuning adapts models by adding learnable prompts or tokens to the input data, avoiding direct modifications to the model’s parameters. Among these methods, LoRA stands out by re-parameterizing weight changes during fine-tuning into the product of two low-rank matrices, thereby reducing the number of trainable parameters.
Researchers from the University of Science and Technology of China and the Institute of Automation, the Chinese Academy of Sciences, and the University of Chinese Academy of Sciences introduced LoRA-Pro. This novel method bridges the performance gap between LoRA and full fine-tuning. LoRA-Pro enhances LoRA’s optimization process by introducing the “Equivalent Gradient.” This concept allows the researchers to measure the differences in the optimization process between LoRA and full fine-tuning and then minimize these differences to improve performance. By doing so, LoRA-Pro ensures that the fine-tuning process closely mimics full fine-tuning.
LoRA-Pro defines the equivalent gradient as a virtual gradient that represents the gradient of the original matrix after low-rank approximation despite not being directly trainable. This gradient is derived from the gradients of the low-rank matrices A and B used in LoRA. During optimization, LoRA-Pro minimizes the difference between the Equivalent Gradient and the gradient obtained from full fine-tuning. This is achieved by selecting appropriate gradients for matrices A and B, formulating the problem as an optimization task, and deriving theoretical solutions for updating these matrices. The closed-form solutions provided by LoRA-Pro ensure that the Equivalent Gradient closely matches the optimization dynamics of full fine-tuning, thus enhancing the overall effectiveness of LoRA.
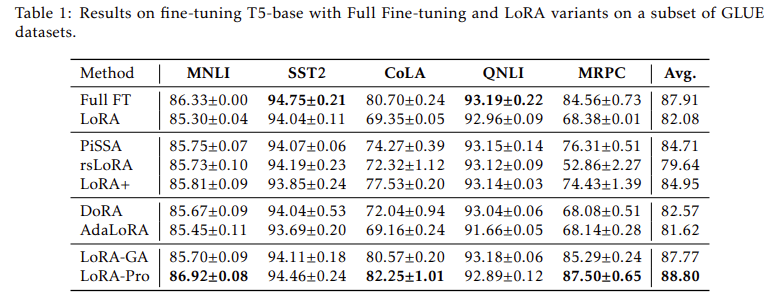
The effectiveness of LoRA-Pro was validated through extensive experiments on natural language processing tasks. The method was tested on the T5-base model using a subset of GLUE datasets. The results showed that LoRA-Pro achieved the highest scores on three out of five datasets, with average scores surpassing standard LoRA by a margin of 6.72%. Specifically, LoRA-Pro recorded 86.92% on MNLI, 94.46% on SST-2, and 87.50% on MRPC, demonstrating its superior performance. These results underscore the capability of LoRA-Pro to narrow the performance gap with full fine-tuning, making it a significant improvement over existing PEFT methods.

In conclusion, the introduction of LoRA-Pro marks a substantial advancement in parameter-efficient fine-tuning. By addressing the optimization shortcomings of LoRA and introducing the concept of Equivalent Gradient, the researchers have developed a method that bridges the performance gap between LoRA and full fine-tuning. The extensive experimental validation confirms that LoRA-Pro maintains the efficiency of LoRA and achieves performance levels closer to full fine-tuning. This makes LoRA-Pro a valuable tool for deploying large foundational models in a more resource-efficient manner.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post LoRA-Pro: A Groundbreaking Machine Learning Approach to Bridging the Performance Gap Between Low-Rank Adaptation and Full Fine-Tuning appeared first on MarkTechPost.
