


Causal effect estimation is crucial for understanding the impact of interventions in various domains, such as healthcare, social sciences, and economics. This area of research focuses on determining how changes in one variable cause changes in another, which is essential for informed decision-making. Traditional methods often involve extensive data collection and structured experiments, which can be time-consuming and costly.
The necessity for structured data and manual data curation hinders current approaches to causal effect estimation. This requirement increases the cost and time of studies and limits the scope of data that can be analyzed. Unstructured data, such as natural language text from social media or forums, represents a rich but underutilized source of information for causal analysis.
Traditional methods for estimating causal effects include randomized controlled trials (RCTs) and observational studies. RCTs are considered the gold standard but are often expensive and impractical for many interventions. Observational studies use existing data but require it to be structured and free of confounding variables. Common techniques include inverse propensity score weighting and outcome imputation, which adjusts for biases in the data.
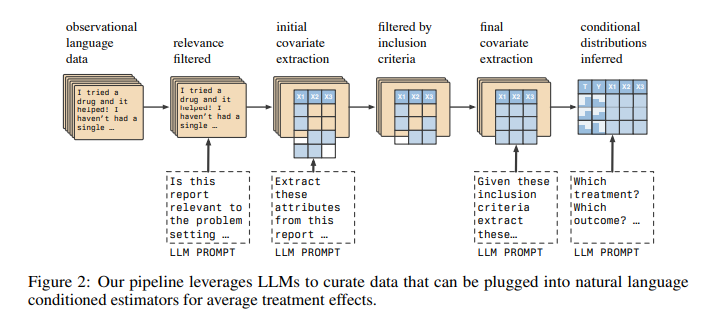
Researchers from the University of Toronto, Vector Institute, and Meta AI introduced NATURAL, a novel family of causal effect estimators leveraging large language models (LLMs) to analyze unstructured text data. This method allows for extracting causal information from diverse sources such as social media posts, clinical reports, and patient forums. By automating data curation and leveraging the capabilities of LLMs, NATURAL provides a scalable solution for various applications.
NATURAL utilizes LLMs to process natural language text and estimate the conditional distributions of variables of interest. The process involves filtering relevant reports, extracting covariates and treatments, and using these to compute average treatment effects (ATEs). The method mimics traditional causal inference techniques but operates on unstructured data, making it a versatile and scalable solution. The pipeline involves several steps:
- Initial filtering to remove irrelevant reports.Extracting treatment and outcome information.Ensuring the reports meet specific inclusion criteria.
This results in a dataset that can estimate causal effects accurately.
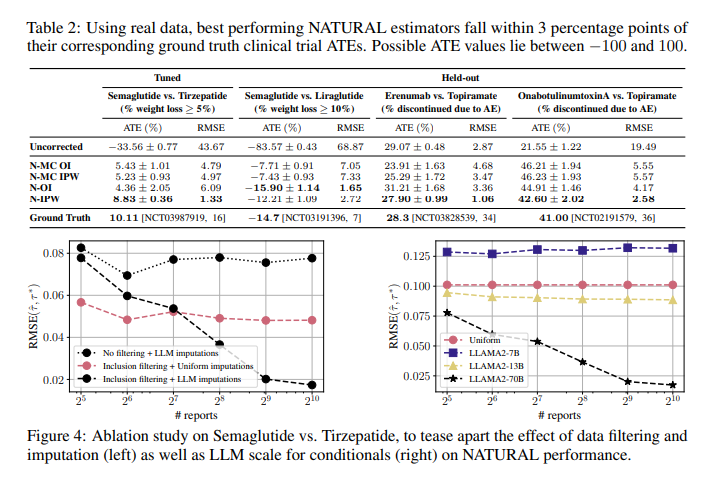
The proposed NATURAL estimators demonstrated remarkable accuracy, with estimated ATEs falling within three percentage points of ground truth values from randomized experiments. Specifically, the method was tested on six datasets, including synthetic datasets and real-world clinical trial data. For the Semaglutide vs. Tirzepatide dataset, NATURAL accurately predicted weight loss outcomes with a mean absolute error of 2.5%. The approach also demonstrated robust performance in predicting outcomes for diabetes and migraine treatments, achieving high consistency with clinical trial results. The cost of computational analysis was significantly lower, at only a few hundred dollars, compared to traditional methods.
NATURAL’s ability to accurately estimate causal effects from unstructured data suggests a transformative potential for fields that rely heavily on causal analysis. By leveraging freely available text data, this method can significantly reduce the time and cost associated with traditional causal effect estimation techniques. The approach is particularly valuable for applications where randomized trials are infeasible or too expensive.
In conclusion, the NATURAL framework presents a groundbreaking approach to causal effect estimation using unstructured natural language data. By automating data curation and leveraging LLMs, researchers provided a scalable solution that could revolutionize fields reliant on causal analysis. This method addresses current limitations and opens new avenues for utilizing rich, unstructured data sources.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post What if the Next Medical Breakthrough is Hidden in Plain Text? Meet NATURAL: A Pipeline for Causal Estimation from Unstructured Text Data in Hours, Not Years appeared first on MarkTechPost.
