真实数据,价值连城


LLM迭代至第9代,完全胡言乱语
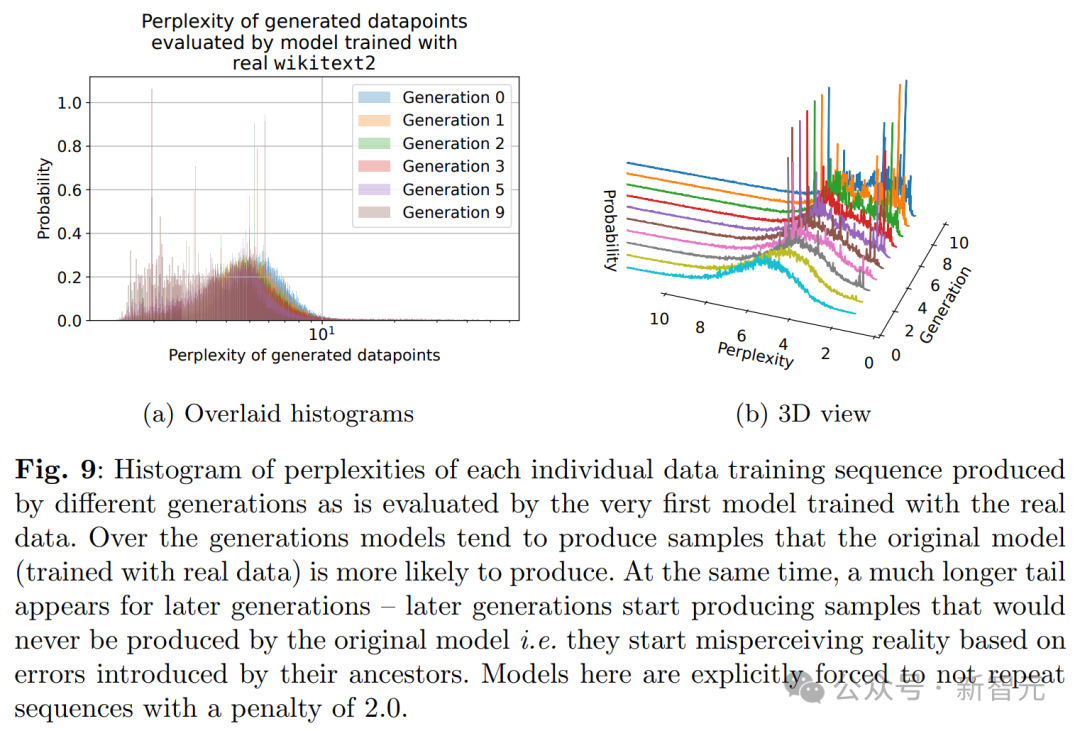
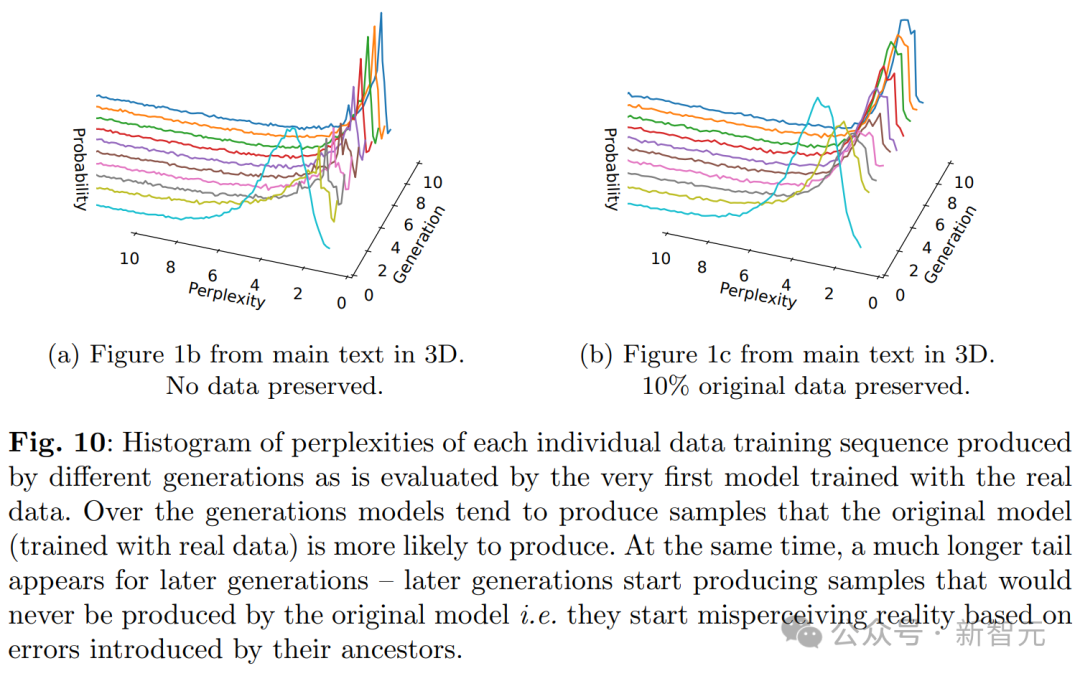
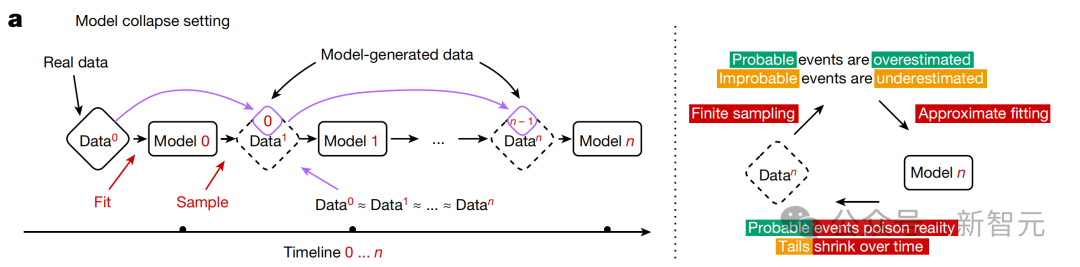
简单讲,LLM生成的数据最终污染了下一代模型的训练集,就会出现「模型崩溃」(model collapse)的现象。 由于在被污染的数据上进行训练,LLM随后会错误地感知现实。 这样一来,会导致多代AI生成模型的退化。 也就是那句经典名言——垃圾进,垃圾出。 
合成数据,无异于给数据集「投毒」。 研究中,作者们使用维基百科文章先训练了模型OPT-125m,并在前一代模型生成的文本上,训练了多代模型。 模型们被要求续写一段来自wiki的关于「萨默塞特(Somerset)一级登录建筑」条目的文本。 
输入的提示如下所示,这是关于设计14世纪教堂塔楼主题的文本:

输入:据Poyntz Wright所说,一些教堂塔楼在1360年之前就开始建造了,通常是由一位大师石匠和一小队流动石匠完成,辅以当地教区的工人。但其他作者不同意这种观点,他们认为主要是由著名建筑师根据早期的垂直风格设计了这些教区教堂的塔楼。

第0代:复兴建筑的典型例子包括伦敦的圣约翰大教堂。最早的垂直复兴建筑实例可以在18@-@世纪的根西岛圣母教堂中找到,该教堂实际建于19世纪晚期。垂直教堂有两种类型:那些。

第1代:像罗马的圣彼得大教堂或布宜诺斯艾利斯的圣彼得大教堂这样的建筑。虽然没有证据表明这些建筑是在教皇英诺森三世统治期间建造的,但它们有可能是在他的继任者教皇英诺森统治期间建造的。


第5代:ism,已被翻译成100多种语言,包括英语、法语、德语、意大利语、西班牙语、葡萄牙语、荷兰语、瑞典语、挪威语、波兰语、匈牙利语、斯洛伐克语、立陶宛语、爱沙尼亚语、芬兰语、罗马尼亚语、保加利亚语、土耳其语、克罗地亚语、塞尔维亚语、乌克兰语、俄语、哈萨克语、吉尔吉斯语。

第9代:建筑。除了拥有世界上最大数量的黑@-@尾兔、白@-@尾兔、蓝@-@尾兔、红@-@尾兔、黄@-。


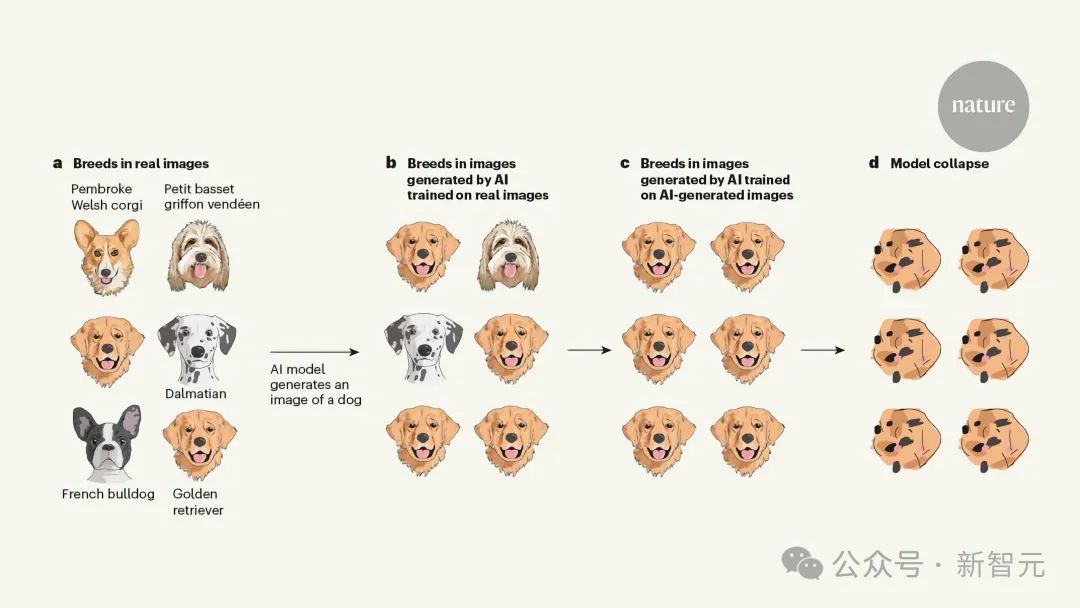


什么是模型崩溃?

理论直觉
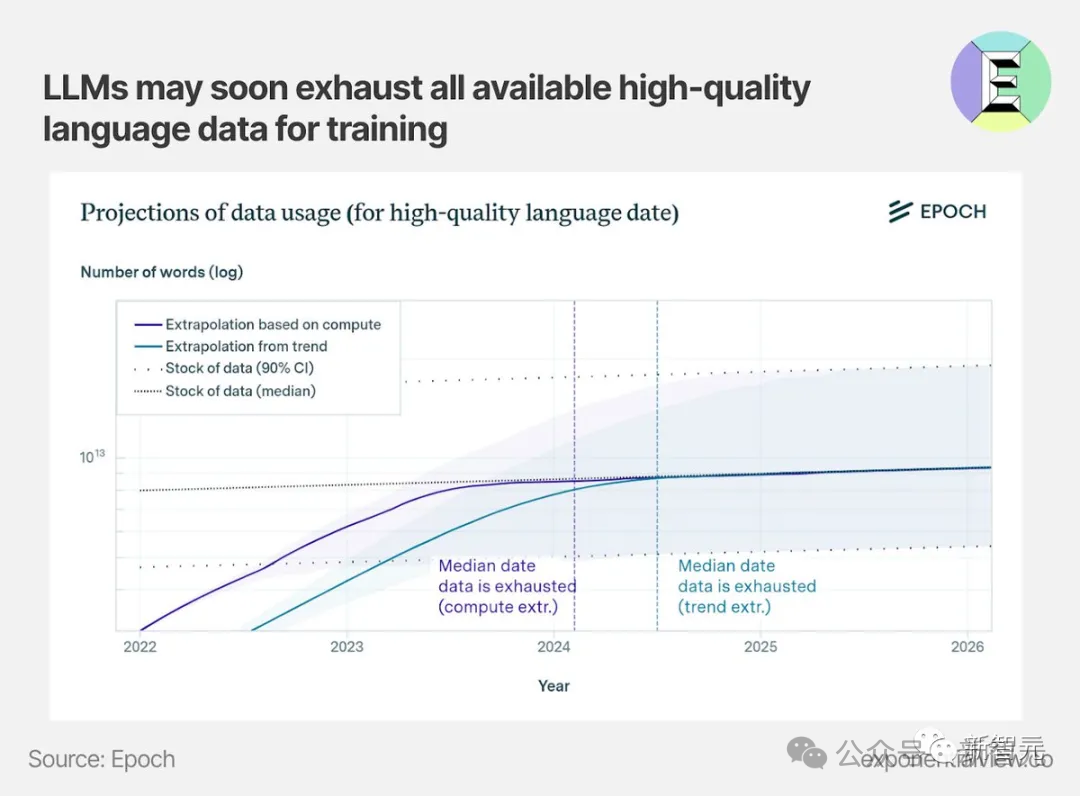
在所有基于前几代生成数据进行递归训练的生成模型,这种现象都是普遍存在的。 所以,到底是什么原因,导致了模型崩溃? 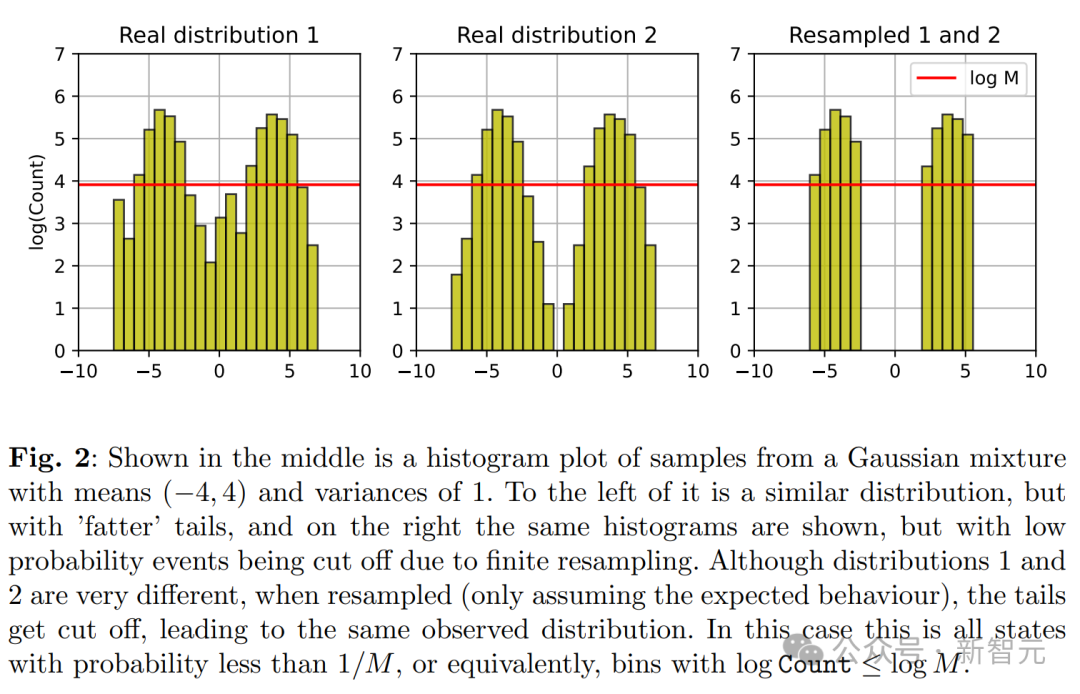
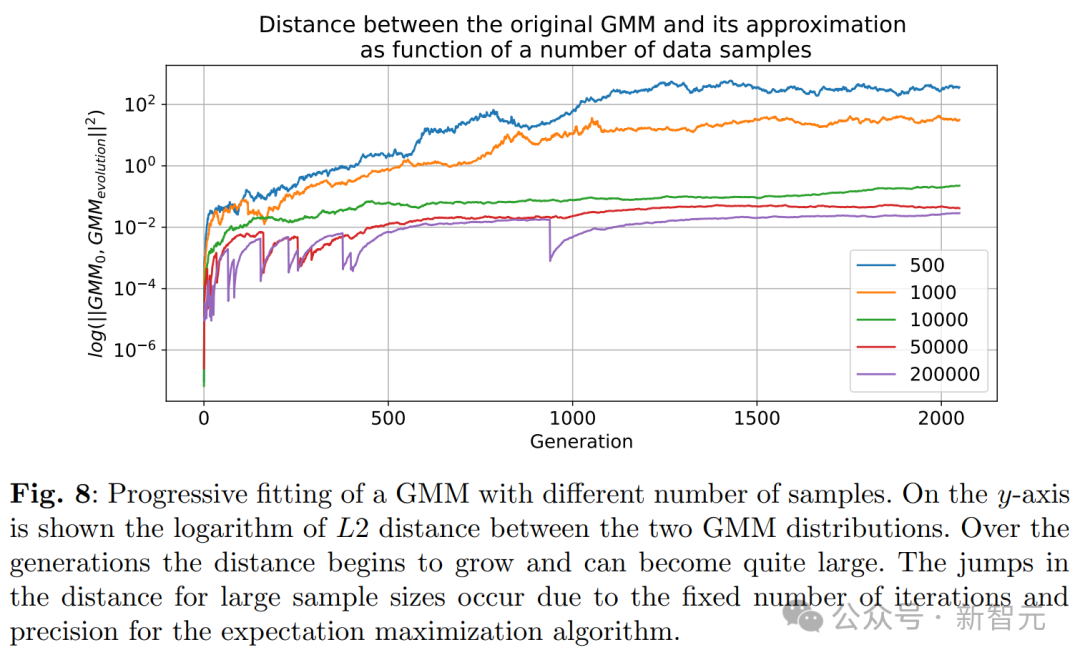
研究者提供了几种理论解释。 通过研究两个数学模型,研究者量化了前一部分讨论的误差来源。 这两个模型分别是一个在没有函数表达能力和近似误差情况下的离散分布模型,以及一个描绘联合函数表达能力和统计误差的多维高斯近似模型。 它们既足够简单,可以提供感兴趣量的解析表达式,同时也能描绘模型崩溃的现象—— 考虑的总体随机过程,作者称之为「代际数据学习」。 第i代的数据集D_i由具有分布p_i的独立同分布随机变量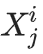 组成。
组成。 其中,数据集的大小j∈{1,…, M_i}。 从第i代到第i+1代,我们需要估计样本在新数据集D_i中的分布,近似为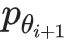 。
。 这一步称之为函数近似,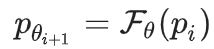 。
。 然后通过从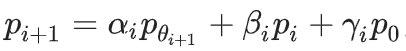 中采样,生成数据集
中采样,生成数据集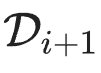 。
。 其中,非负参数α_i, β_i, γ_i的和为1,即它们表示来自不同代的数据的比例。 它们对应的混合数据,分别来自原始分布(γ_i)、上一代使用的数据(β_i)和新模型生成的数据(α_i)。 这一步,称为采样步骤。 对于即将讨论的数学模型,我们考虑α_i=γ_i=0,即仅使用单步的数据,而数值实验则在更现实的参数选择上进行。
组成。。。中采样,生成数据集。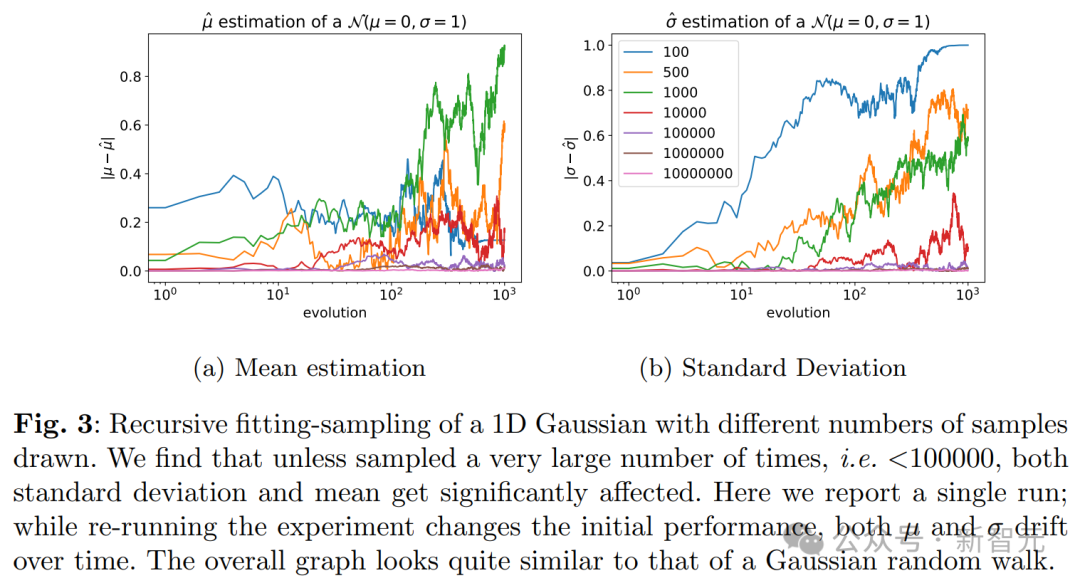
离散分布的精确近似
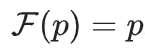 。
。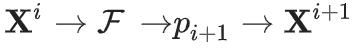 这个过程看作一个马尔可夫链,我们就可以直接证明上述结论,因为X^(i+1)仅依赖于X^i。
这个过程看作一个马尔可夫链,我们就可以直接证明上述结论,因为X^(i+1)仅依赖于X^i。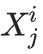 的值都相同,那么在下一代,近似分布将完全是一个δ函数。因此所有
的值都相同,那么在下一代,近似分布将完全是一个δ函数。因此所有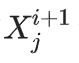 的值也将相同。
的值也将相同。多维高斯分布
高斯模型崩溃
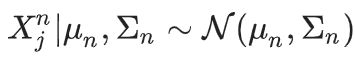 且样本量是固定的。
且样本量是固定的。 。
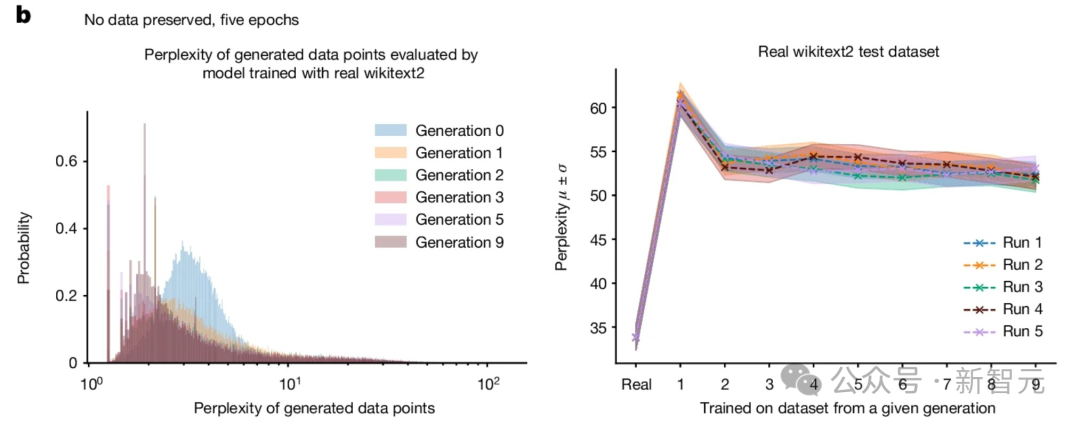
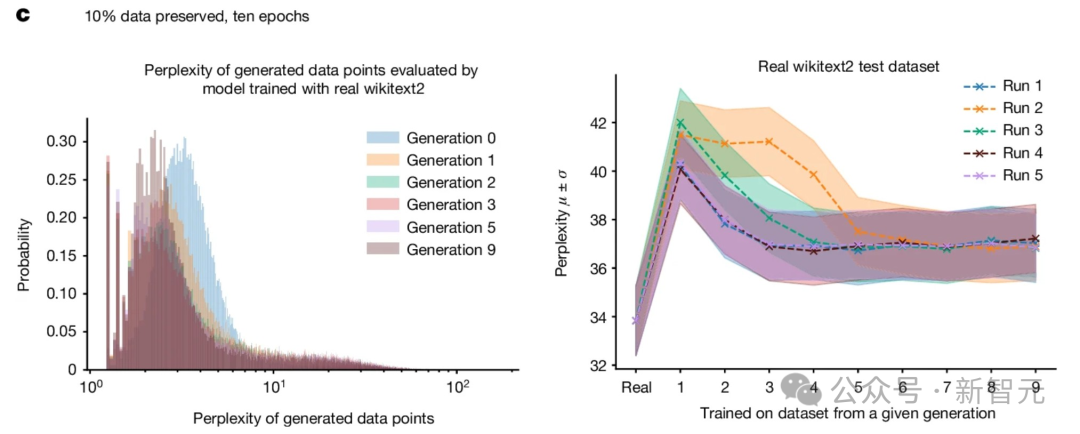
。语言模型中的模型崩溃
当模型发生崩溃,会对语言模型产生哪些影响?