


Current methodologies for Text-to-SQL primarily rely on deep learning models, particularly Sequence-to-Sequence (Seq2Seq) models, which have become mainstream due to their ability to map natural language input directly to SQL output without intermediate steps. These models, enhanced by pre-trained language models (PLMs), set the state-of-the-art in the field, benefiting from large-scale corpora to improve their linguistic capabilities. Despite these advances, the transition to large language models (LLMs) promises even greater performance due to their scaling laws and emergent abilities. These LLMs, with their substantial number of parameters, can capture complex patterns in data, making them well-suited for the Text-to-SQL task.
A new research paper from Peking University addresses the challenge of converting natural language queries into SQL queries, a process known as Text-to-SQL. This conversion is crucial for making databases accessible to non-experts who may not know SQL but need to interact with databases to retrieve information. The inherent complexity of SQL syntax and the intricacies involved in database schema understanding make this a significant problem in natural language processing (NLP) and database management.
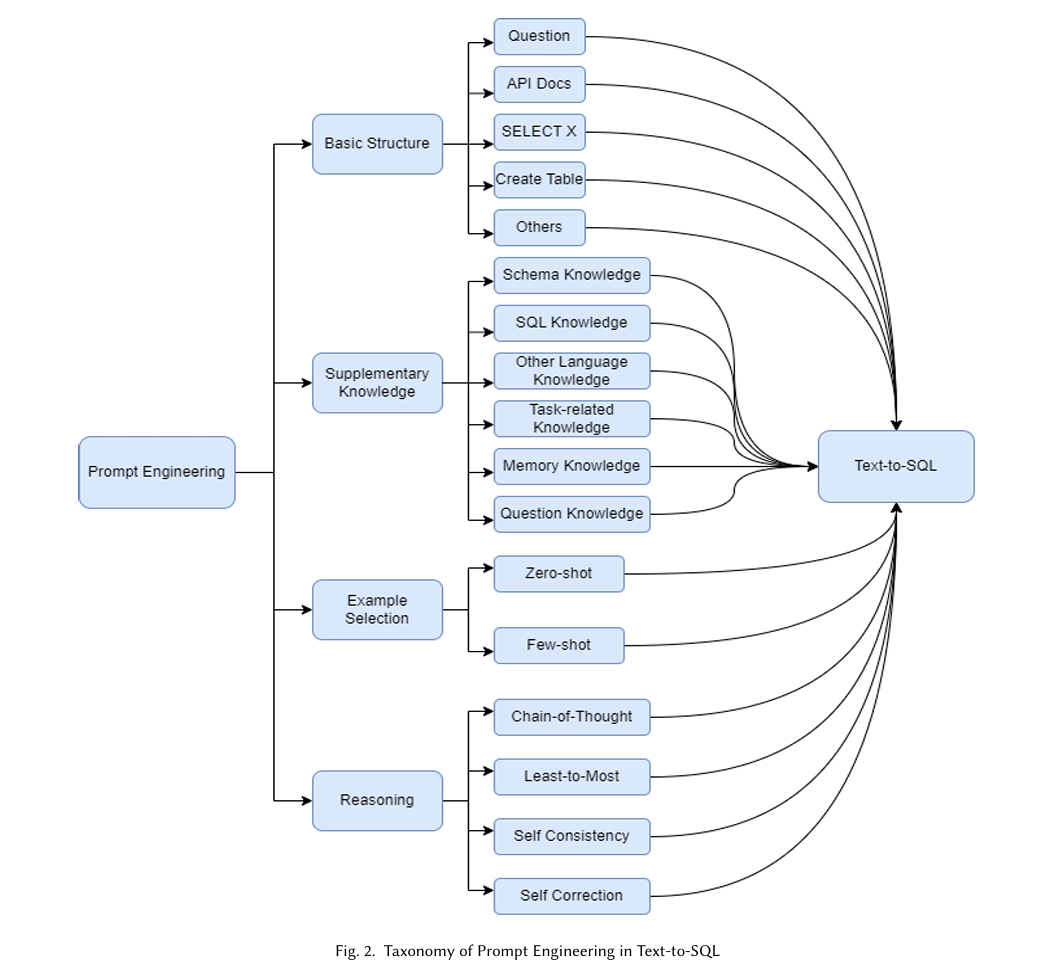
The proposed method in this paper leverages LLMs for Text-to-SQL tasks through two main strategies: prompt engineering and fine-tuning. Prompt engineering involves techniques such as Retrieval-Augmented Generation (RAG), few-shot learning, and reasoning, which require less data but may only sometimes yield optimal results. On the other hand, fine-tuning LLMs with task-specific data can significantly enhance performance but demands a larger training dataset. The paper investigates the balance between these approaches, aiming to find an optimal strategy that maximizes the performance of LLMs in generating accurate SQL queries from natural language inputs.
The paper explores various multi-step reasoning patterns that can be applied to LLMs for the Text-to-SQL task. These include Chain-of-Thought (CoT), which guides LLMs to generate answers step by step by adding specific prompts to break down the task; Least-to-Most, which decomposes a complex problem into simpler sub-problems; and Self-Consistency, which uses a majority voting strategy to select the most frequent answer generated by the LLM. Each method helps LLMs generate more accurate SQL queries by mimicking the human approach to solving complex problems incrementally and iteratively.
In terms of performance, the paper highlights that applying LLMs has significantly improved the execution accuracy of Text-to-SQL tasks. For instance, the state-of-the-art accuracy on benchmark datasets like Spider has risen from approximately 73% to 91.2% with the integration of LLMs. However, challenges remain, particularly with the introduction of new datasets such as BIRD and Dr.Spider, which present more complex scenarios and robustness tests. The findings indicate that even advanced models like GPT-4 still struggle with certain perturbations, achieving only 54.89% accuracy on the BIRD dataset. This underscores the need for ongoing research and development in this area.
The paper provides a comprehensive overview of employing LLMs for Text-to-SQL tasks, highlighting the potential of multi-step reasoning patterns and fine-tuning strategies to improve performance. By addressing the challenges of converting natural language to SQL, this research paves the way for more accessible and efficient database interactions for non-experts. The proposed methods and detailed evaluations demonstrate significant advancements in the field, promising more accurate and efficient solutions for real-world applications. This work advances the state-of-the-art in Text-to-SQL and underscores the importance of leveraging the capabilities of LLMs to bridge the gap between natural language understanding and database querying.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Transforming Database Access: The LLM-based Text-to-SQL Approach appeared first on MarkTechPost.
