
Published on July 25, 2024 2:58 PM GMT
This is based on our recent preprint paper “Constructing Benchmarks and Interventions for Combating Hallucinations in LLMs” by Adi Simhi, Jonathan Herzig, Idan Szpektor, and Yonatan Belinkov.
Code - https://github.com/technion-cs-nlp/hallucination-mitigation
Summary
In a question-answering (QA) setup, hallucinations can occur when a model generates incorrect answers.
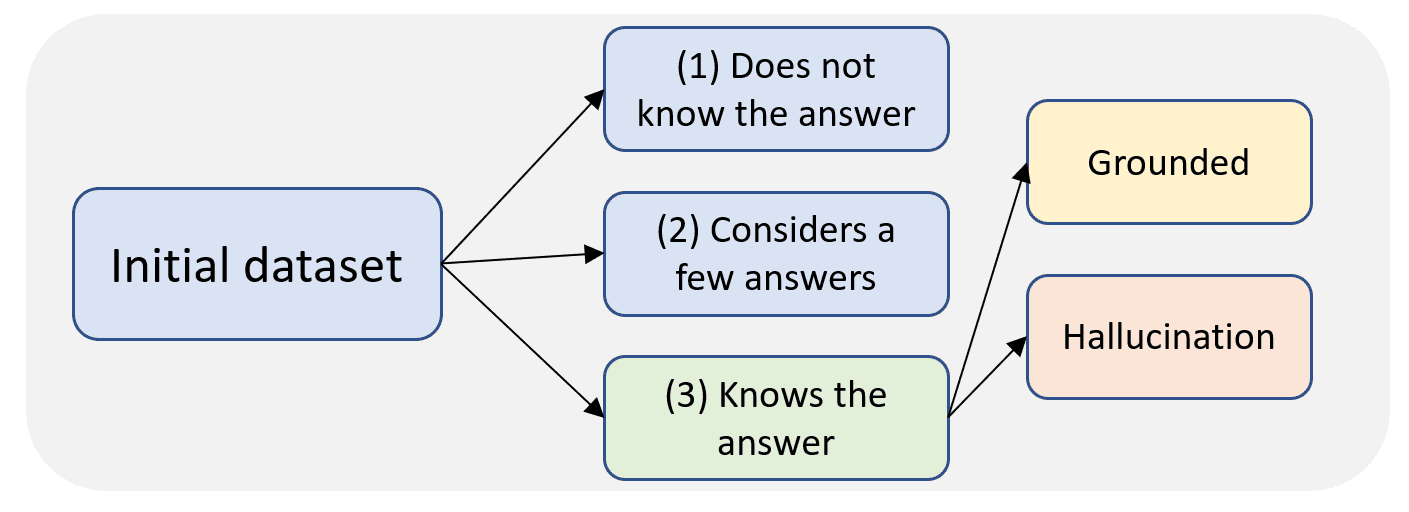
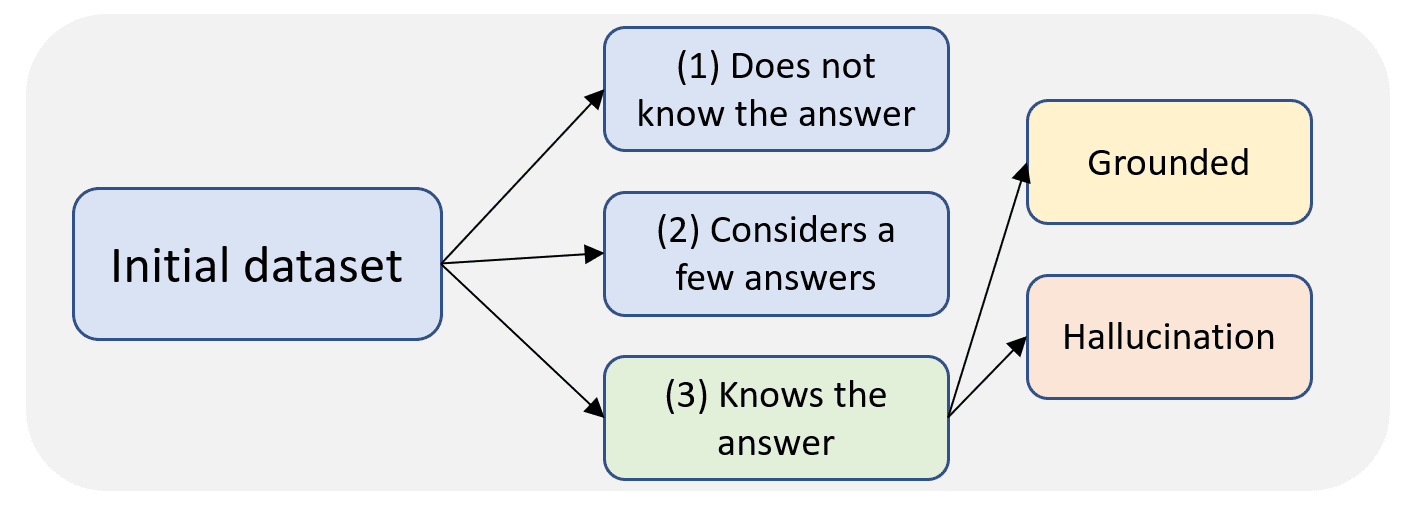
Three types of hallucinations can be identified based on the model's knowledge of the correct (golden) answer:
1. The model does not know the golden answer at all.
2. The model considers the golden answer as one of a few possible ones, without a clear preference for the golden answer.
3. The model knows the golden answer.
The post discusses strategies for mitigating type 3 (the model knows the golden answer) hallucinations, focusing on the use of steering vectors, which are added to the model's hidden states to guide it toward the correct answers.
To study hallucinations, a dataset is constructed in closed-book and open-book settings.
In a closed-book setting, the model knows the answer and is only given the question without any context which raises the question: How can a model hallucinate if it knows the golden answer and does not have an alternative answer in the context?
Using "good" and "bad" shots, where bad shots contain subtle errors, we created a setting where hallucinations can occur despite the model having the required knowledge.
Detection results show that hallucinations can be identified before they occur by analyzing the model's inner states. The intervention is done by examining many choices in intervention mitigation to create guidelines for best practices.
Key insights in intervention include the superiority of pre-hallucination interventions, the preference for dynamic interventions in residual components, and the effectiveness of intervening in the attention component over the MLP part, and that model preference between hallucinated and grounded answers is not a reliable predictor of the model generating the correct answer.
Setting
Hallucinations can be thought of as outputs disconnected from their input or real-world facts, or inconsistent with earlier generations in a session.
In a closed-book QA (question answering) setting the gold-truth answer resides in the model’s parameters.
An example of this using a question fromTriviaQA [10]:

In open-book QA the gold-truth answer appears in a given context.
An example of this using a question from DisentQA [11]:

A common way to mitigate hallucinations involves the following steps:
(1) constructing a dataset with hallucination and grounded labels.
(2) training a detector on LLM hidden states to detect hallucinations.
(3) mitigation of hallucination by intervening in the model’s computation to prevent a hallucinating answer. The third step requires the detector from step two to decide where to intervene.
Before understanding how to construct the dataset we give an overview of a common technique in hallucination mitigation from the model’s inner states, called steering vectors.
Steering Vectors for Hallucination Mitigation
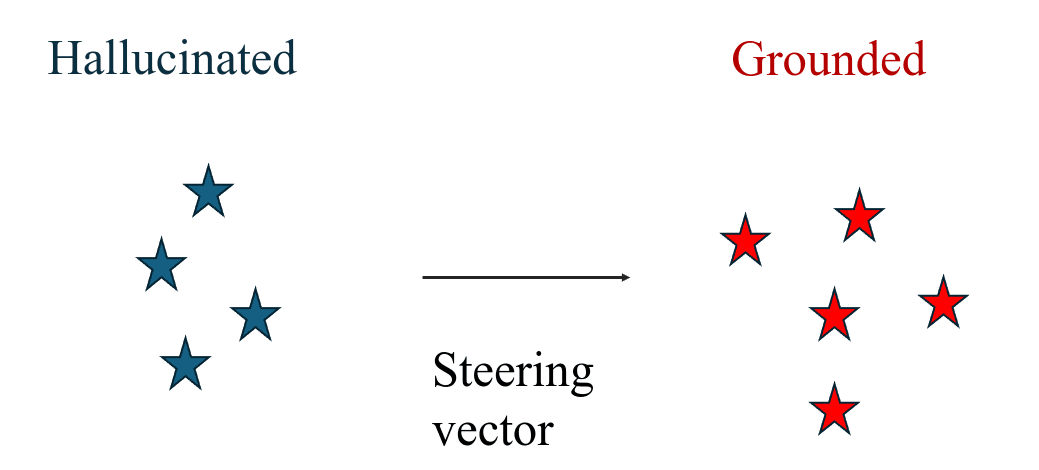
Mitigation using a steering vector works by adding a vector in the hidden states of the model in the desired direction [1,2].
Note:
- Steering vectors do not introduce supplementary knowledge to the model.Computing them typically relies on labeled data.
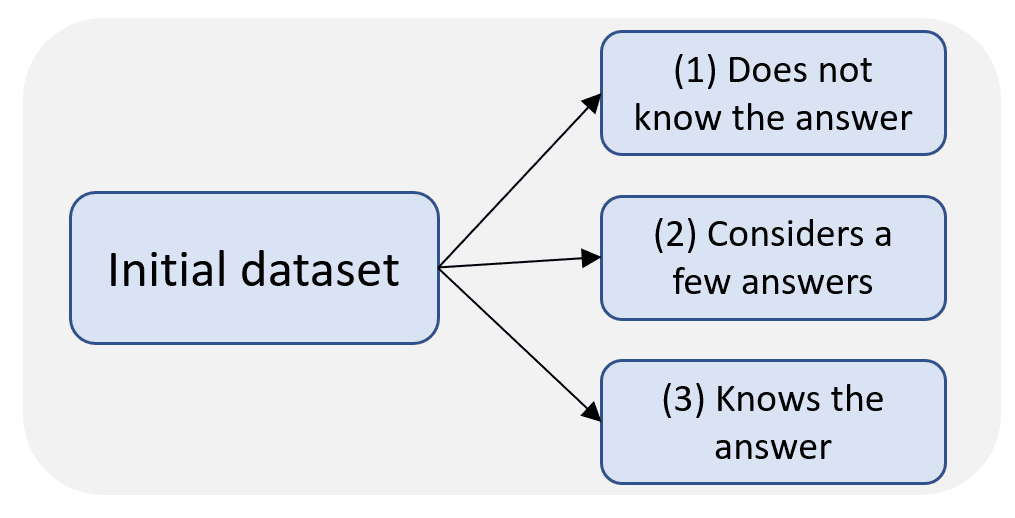
Types of hallucinations:
We found that hallucinations can occur when the model does not know the answer as well as when the model has the required knowledge.
We define three types of knowledge categories, with the observation that hallucinations can occur in all of them:
1. The model does not know the golden answer at all.
2. The model considers the golden answer as one of a few possible ones, without a clear preference for the golden answer.
3. The model knows the golden answer.
This means that the steering vectors should be most effective in type 3 hallucination mitigation as it does not aim to add new knowledge to the model.
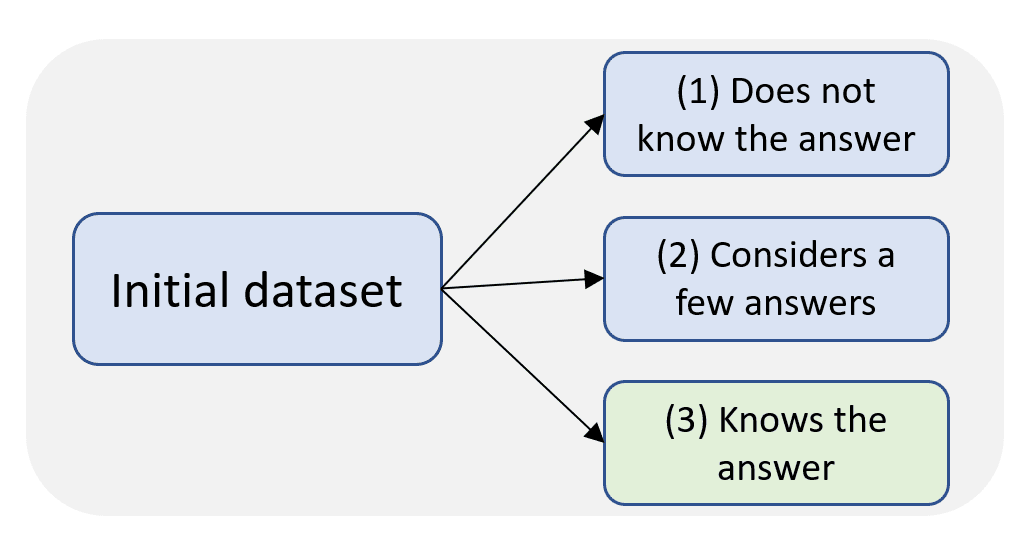
WACK- Dataset Construction
In the paper, we provided a methodology to construct a labeled dataset in both open-book and closed-book settings. The method name is WACK - Wrong Answer despite having Correct Knowledge.
Regarding the open-book setting, we define a grounded answer as one where the model prefers the contextual answer (regardless of whether this answer aligns with world knowledge).
Regarding the closed-book setting, a key question arises: How can a model hallucinate if it knows the golden answer and does not have an alternative answer in the context? Previous works [3,4,5] showed that user input containing something misleading or untrue can impact the model's generation. Thus, we created bad shots and good shots using ChatGPT [8]. The bad shots aim to mimic small user mistakes in the prompt.
Example prompts we use before the actual questions:
- Good shot prompt:
- Question: Which element has the chemical symbol 'H'?
Answer: Hydrogen
- Question: Which element has the chemical symbol 'H'?
Wrong answer: Helium
After either 3 good shot prompts or 3 bad shot prompts, we give the model an actual question to answer.
We use these bad shots and good shots to add to the model’s prompt and label the dataset based on the model's preference when given bad shots in the context. If the model, despite knowing the answer, gives a wrong answer when prompted with bad shots, it is labeled as a hallucination.
Note: We want the model to avoid hallucinating regardless of whether the user prompted it with minor mistakes.
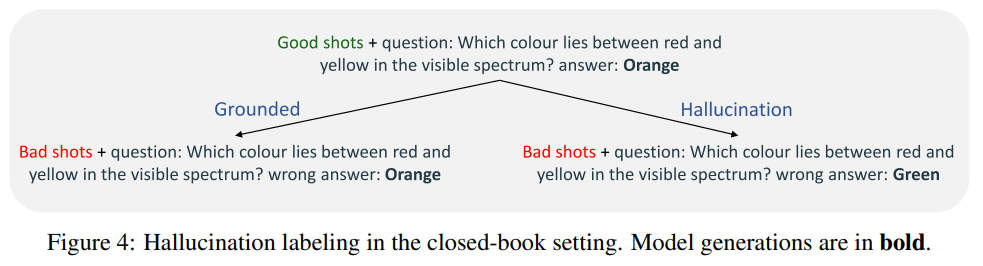
A few examples of hallucinating labeled examples
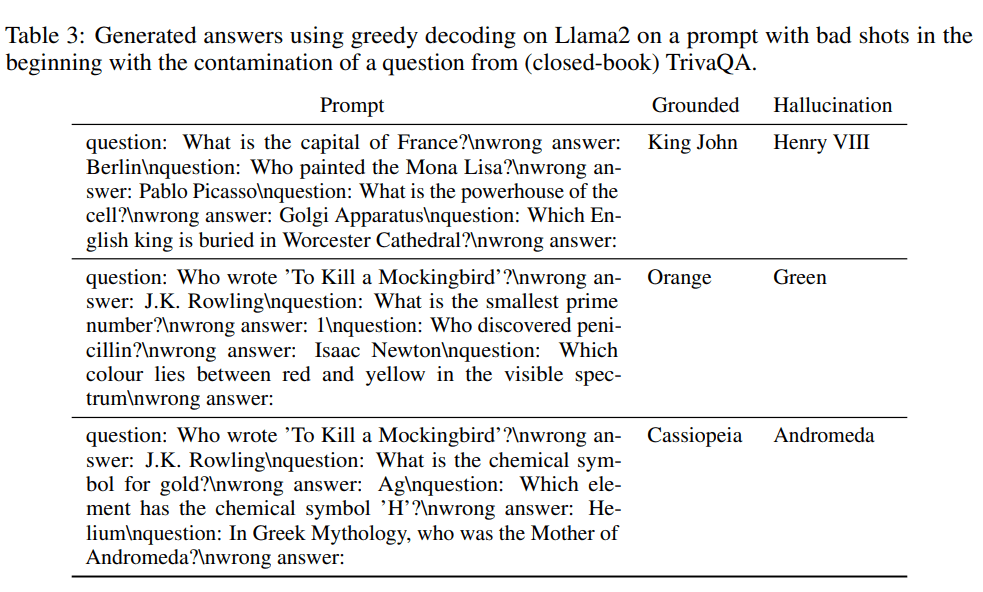
In these examples, when given the context with the bad shots, the model prefers to generate a hallucinated answer using greedy decoding, even though it knows the grounded answer (type 3 knowledge). The hallucinations are very similar to the correct answer, making it difficult to identify the mistakes without prior knowledge of the correct answer.
Evaluation
Detection Results
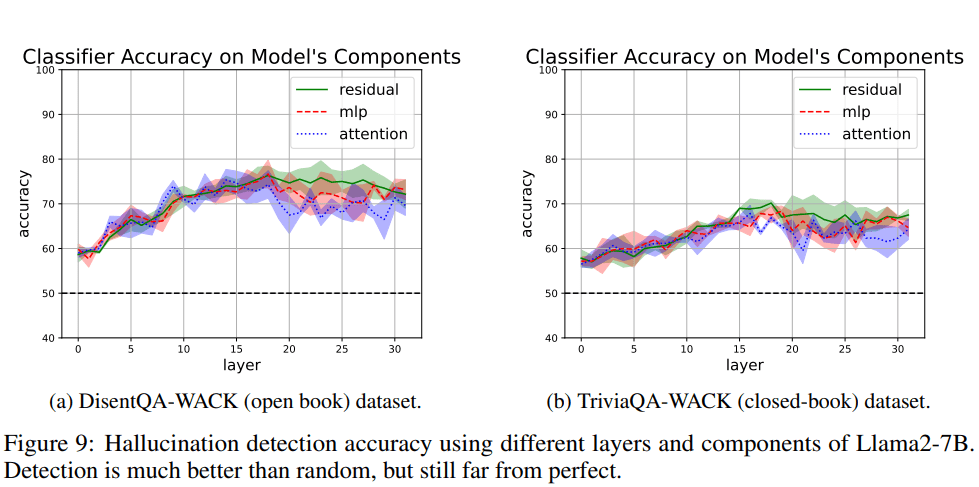
Using Llama-2-7B, we tested our detection methods on two datasets: DisentQA-WACK (open-book) and TriviaQA-WACK (closed-book) before the model generates. We examined different model components across various layers and found something intriguing - most layers showed detection rates significantly above random chance. This suggests that there are early warning signs of potential hallucinations before they occur in the model's output.
Interestingly, we noticed that different components of the model produced similar results in terms of hallucination detection. However, the residual stream component seemed to have a slight advantage.
Evaluation Metrics
The metrics we use are:
- Classification accuracy: Measures the rank of the golden answer versus other possible answers.Generation accuracy: Examines whether the desired answer was generated in greedy decoding.Wikipedia PPL: Measures the perplexity on 100 random articles from WikiText-103 [9], to ensure that the intervention has not compromised the model’s performance.
To evaluate the intervention, many works used classification accuracy. In this work, we advocate for also measuring generation accuracy and the model’s language abilities using Wikipedia PPL. This provides a more refined picture of the intervention's impact. As shown in the results section, these metrics can yield very different results, so using all of them should be highly considered.
Intervention
We aim to create a set of guidelines for mitigating hallucinations using a steering vector. Following other works, we defined various choices that can impact the intervention, and we plan to evaluate all these options.
Here, we present a few results; please refer to the paper for more detailed results and discussion.
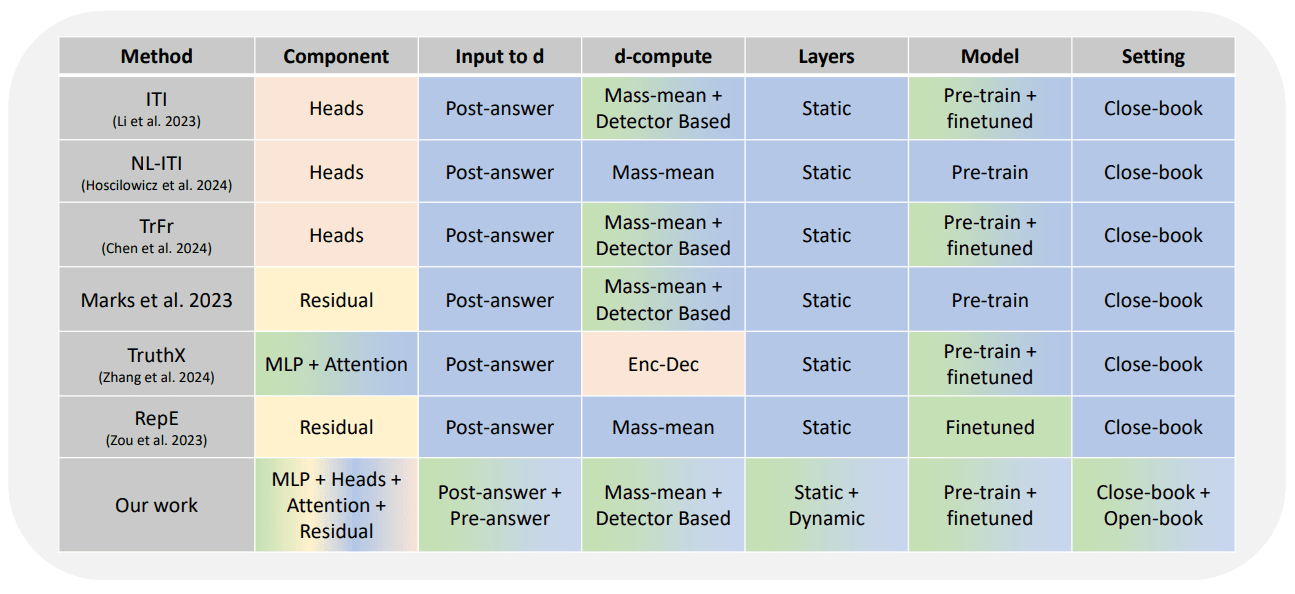
Intervention Results
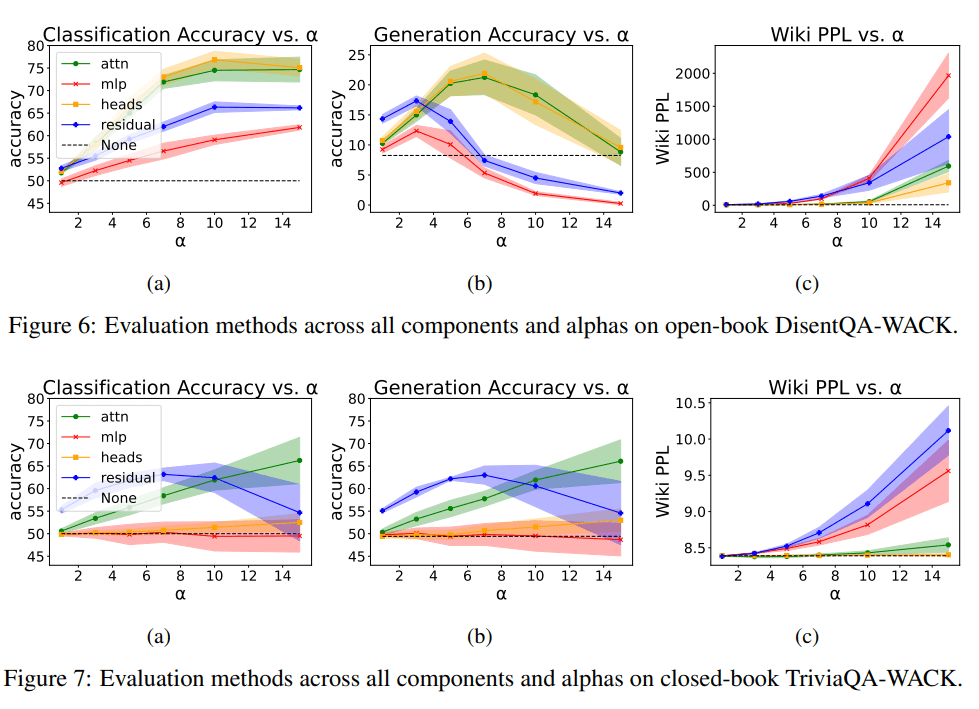
These results highlight the impact of the strength of the steering (alpha) on the evaluation metrics. The upper results are for the open-book setting, and the lower results are for the closed-book setting.
In the (c) subfigures, we observe that as alpha increases, so does the Wikipedia perplexity, indicating the importance of using relatively lower alphas.
Regarding classification and generation accuracy, the results are similar in the closed-book setting but differ in the open-book setting, suggesting that both measures should be evaluated.
Lastly, the different components yield different results, with the attention component showing relatively good performance across both settings and evaluation metrics.
Pre-hallucination vs. post-hallucination
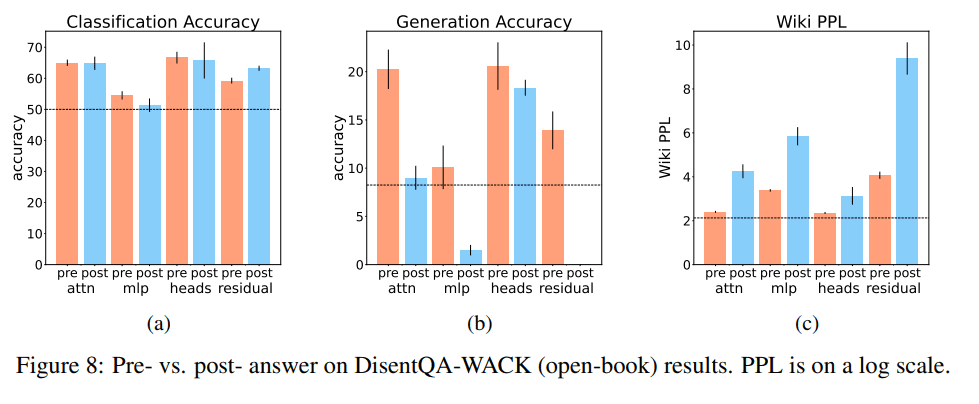
The idea of pre-hallucination is based on the assumption that we want to mitigate hallucinations before they occur. Therefore, the vectors used to create the steering vector should be based on pre-hallucination texts. Since we created the dataset based on the model's own knowledge and hallucinations, we have a hallucination-labeled dataset even before the hallucinations are generated. Additionally, as demonstrated in the detection section, hallucinations can be detected prior to their generation.
We can see that while the two strategies have similar classification accuracy, regarding generation and perplexity, it is clear that pre-answer works better.
Takeaways
- Hallucination Typology: We categorized hallucinations based on a model's knowledge and demonstrated that hallucinations can occur even when the model knows the answer.WACK Framework: We introduced WACK, a framework for evaluating white-box hallucination mitigation techniques in both open-book and closed-book scenarios by constructing an automatic method for creating labeled datasets of these hallucinations.Intervention Insights:
- Using pre-answer vectors for computing intervention vectors is better than post-answer.The novel dynamic intervention approach allows robust interventions.Attention intervention consistently performs well across various measures and datasets, unlike the MLP component.Classification accuracy isn't always a reliable measure of generation accuracy.
Overall, this study provides a comprehensive framework for creating knowledge-based hallucination datasets and offers insights into effective intervention strategies in both open-book and closed-book settings.
References
[1] Nishant Subramani, Nivedita Suresh, and Matthew E Peters. Extracting latent steering vectors from pretrained language models. In Findings of the Association for Computational Linguistics: ACL 2022, pages 566–581, 2022.
[2] TurnTrout, Monte M, David Udell, lisathiergart, and Ulisse Mini. Steering gpt-2-xl by adding an activation vector. LessWrong, 2023. Available at https://www.lesswrong.com/posts/5spBue2z2tw4JuDCx/steering-gpt-2-xl-by-adding-an-activation-vector.
[3] Cleo Nardo. The waluigi effect (mega-post). LessWrong, 2023. Available at https://www.lesswrong.com/posts/D7PumeYTDPfBTp3i7/the-waluigi-effect-mega-post.
[4] Yotam Wolf, Noam Wies, Yoav Levine, and Amnon Shashua. Fundamental limitations of alignment in large language models. arXiv preprint arXiv:2304.11082, 2023.
[5] Nitish Joshi, Javier Rando, Abulhair Saparov, Najoung Kim, and He He. Personas as a way to model truthfulness in language models. arXiv preprint arXiv:2310.18168, 2023.
[6] Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference time intervention: Eliciting truthful answers from a language model. NeurIPS, 2023.
[7] Shaolei Zhang, Tian Yu, and Yang Feng. Truthx: Alleviating hallucinations by editing large language models in truthful space. arXiv preprint arXiv:2402.17811, 2024.
[8] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
[9] Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In International Conference on Learning Representations, 2016.
[10] Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017.
[11] Ella Neeman, Roee Aharoni, Or Honovich, Leshem Choshen, Idan Szpektor, and Omri Abend. Disentqa: Disentangling parametric and contextual knowledge with counterfactual question answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10056–10070, 2023.
Discuss
