


Question answering (QA) is a crucial area in natural language processing (NLP), focusing on developing systems that can accurately retrieve and generate responses to user queries from extensive data sources. Retrieval-augmented generation (RAG) enhances the quality and relevance of answers by combining information retrieval with text generation. This approach filters out irrelevant information and presents only the most pertinent passages for large language models (LLMs) to generate responses.
One of the main challenges in QA is the limited scope of existing datasets, which often use single-source corpora or focus on short, extractive answers. This limitation hampers evaluating how well LLMs can generalize across different domains. Current methods such as Natural Questions and TriviaQA rely heavily on Wikipedia or web documents, which are insufficient for assessing cross-domain performance. As a result, there is a significant need for more comprehensive evaluation frameworks that can test the robustness of QA systems across various domains.
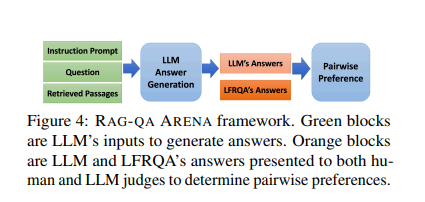
Researchers from AWS AI Labs, Google, Samaya.ai, Orby.ai, and the University of California, Santa Barbara, have introduced Long-form RobustQA (LFRQA) to address these limitations. This new dataset comprises human-written long-form answers that integrate information from multiple documents into coherent narratives. Covering 26,000 queries across seven domains, LFRQA aims to evaluate the cross-domain generalization capabilities of LLM-based RAG-QA systems.
LFRQA distinguishes itself from previous datasets by offering long-form answers grounded in a corpus, ensuring coherence, and covering multiple domains. The dataset includes annotations from various sources, making it a valuable tool for benchmarking QA systems. This approach addresses the shortcomings of extractive QA datasets, which often fail to capture the comprehensive and detailed nature of modern LLM responses.
The research team introduced the RAG-QA Arena framework to leverage LFRQA for evaluating QA systems. This framework employs model-based evaluators to directly compare LLM-generated answers with LFRQA’s human-written answers. By focusing on long-form, coherent answers, RAG-QA Arena provides a more accurate and challenging benchmark for QA systems. Extensive experiments demonstrated a high correlation between model-based and human evaluations, validating the framework’s effectiveness.
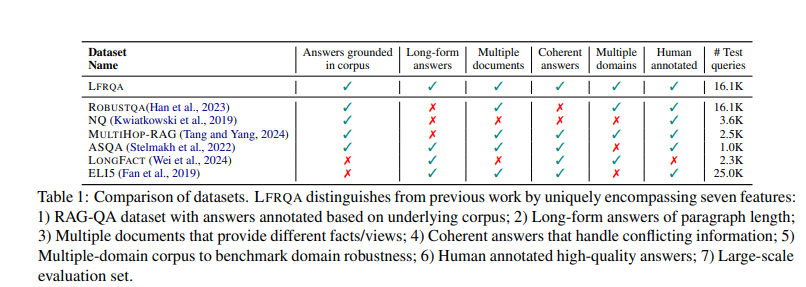
The researchers employed various methods to ensure the high quality of LFRQA. Annotators were instructed to combine short extractive answers into coherent long-form answers, incorporating additional information from the documents when necessary. Quality control measures included random audits of annotations to ensure completeness, coherence, and relevance. This rigorous process resulted in a dataset that effectively benchmarks the cross-domain robustness of QA systems.
Performance results from the RAG-QA Arena framework show significant findings. Only 41.3% of answers generated by the most competitive LLMs were preferred over LFRQA’s human-written answers. The dataset demonstrated a strong correlation between model-based and human evaluations, with a correlation coefficient of 0.82. Furthermore, the evaluation revealed that LFRQA answers, which integrated information from up to 80 documents, were preferred in 59.1% of cases compared to leading LLM answers. The framework also highlighted a 25.1% gap in performance between in-domain and out-of-domain data, emphasizing the importance of cross-domain evaluation in developing robust QA systems.
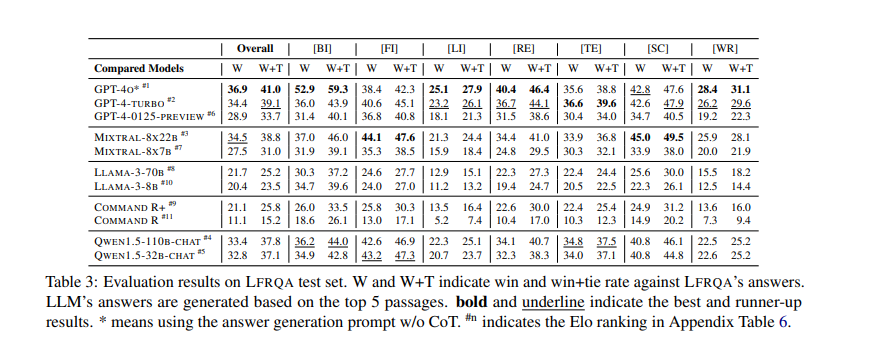
In addition to its comprehensive nature, LFRQA includes detailed performance metrics that provide valuable insights into the effectiveness of QA systems. For example, the dataset contains information about the number of documents used to generate answers, the coherence of those answers, and their fluency. These metrics help researchers understand the strengths and weaknesses of different QA approaches, guiding future improvements.
In conclusion, the research led by AWS AI Labs, Google, Samaya.ai, Orby.ai, and the University of California, Santa Barbara, highlights the limitations of existing QA evaluation methods and introduces LFRQA and RAG-QA Arena as innovative solutions. These tools offer a more comprehensive and challenging benchmark for assessing the cross-domain robustness of QA systems, contributing significantly to the advancement of NLP and QA research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post This AI Paper Introduces Long-form RobustQA Dataset and RAG-QA Arena for Cross-Domain Evaluation of Retrieval-Augmented Generation Systems appeared first on MarkTechPost.
