


Large language models (LLMs) models, designed to understand and generate human language, have been applied in various domains, such as machine translation, sentiment analysis, and conversational AI. LLMs, characterized by their extensive training data and billions of parameters, are notoriously computationally intensive, posing challenges to their development and deployment. Despite their capabilities, training and deploying these models is resource-heavy, often requiring extensive computational power and large datasets, leading to substantial costs.
One of the primary challenges in this area is the resource-intensive nature of training multiple variants of LLMs from scratch. Researchers aim to create different model sizes to suit various deployment needs, but this process demands enormous computational resources and vast training data. The high cost associated with this approach makes it difficult to scale and deploy these models efficiently. The need to reduce these costs without compromising model performance has driven researchers to explore alternative methods.
Existing approaches to mitigate these challenges include various pruning techniques and knowledge distillation methods. Pruning systematically removes less important weights or neurons from a pre-trained model, reducing its size and computational demands. On the other hand, knowledge distillation transfers knowledge from a larger, more complex model (the teacher) to a smaller, simpler model (the student), enhancing the student model’s performance while requiring fewer resources for training. Despite these techniques, finding a balance between model size, training cost, and performance remains a significant challenge.
Researchers at NVIDIA have introduced a novel approach to prune and retrain LLMs efficiently. Their method focuses on structured pruning, systematically removing entire neurons, layers, or attention heads based on their calculated importance. This approach is combined with a knowledge distillation process, allowing the pruned model to be retrained using a small fraction of the original training data. This method aims to retain the performance of the original model while significantly reducing the training cost and time. The researchers have developed the Minitron model family and have open-sourced these models on Huggingface for public use.
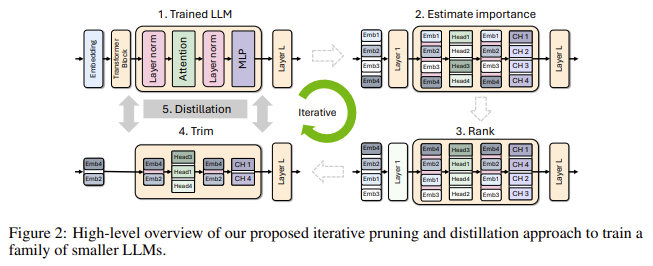
The proposed method begins with an existing large model and prunes it to create smaller, more efficient variants. The importance of each component—neuron, head, layer—is calculated using activation-based metrics during forward propagation on a small calibration dataset of 1024 samples. Components deemed less important are pruned. Following this, the pruned model undergoes a knowledge distillation-based retraining, which helps recover the model’s accuracy. This process leverages a significantly smaller dataset, making the retraining phase much less resource-intensive than traditional methods.
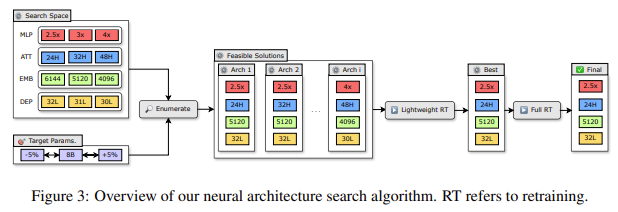
The performance of this method was evaluated on the Nemotron-4 model family. The researchers achieved a 2-4× reduction in model size while maintaining comparable performance levels. Specifically, using this method, the 8B and 4B models derived from a 15B model required up to 40× fewer training tokens than training from scratch. This resulted in compute cost savings of 1.8× for training the entire model family (15B, 8B, and 4B). Notably, the 8B model demonstrated a 16% improvement in MMLU scores compared to models trained from scratch. These models performed comparably to other well-known community models, such as Mistral 7B, Gemma 7B, and LLaMa-3 8B, outperforming state-of-the-art compression techniques from existing literature. The Minitron models have been made available on Huggingface for public use, providing the community access to these optimized models.

In conclusion, the researchers at NVIDIA have demonstrated that structured pruning combined with knowledge distillation can reduce the cost and resources required to train large language models. By employing activation-based metrics and a small calibration dataset for pruning, followed by efficient retraining using knowledge distillation, they have shown that it is possible to maintain and, in some cases, improve model performance while drastically cutting down on computational costs. This innovative approach paves the way for more accessible and efficient NLP applications, making it feasible to deploy LLMs at various scales without incurring prohibitive costs.
Check out the Paper and Models. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Nvidia AI Releases Minitron 4B and 8B: A New Series of Small Language Models that are 40x Faster Model Training via Pruning and Distillation appeared first on MarkTechPost.
