


Reinforcement learning from human feedback RLHF is essential for ensuring quality and safety in LLMs. State-of-the-art LLMs like Gemini and GPT-4 undergo three training stages: pre-training on large corpora, SFT, and RLHF to refine generation quality. RLHF involves training a reward model (RM) based on human preferences and optimizing the LLM to maximize predicted rewards. This process is challenging due to forgetting pre-trained knowledge and reward hacking. A practical approach to enhance generation quality is Best-of-N sampling, which selects the best output from N-generated candidates, effectively balancing reward and computational cost.
Researchers at Google DeepMind have introduced Best-of-N Distillation (BOND), an innovative RLHF algorithm designed to replicate the performance of Best-of-N sampling without its high computational cost. BOND is a distribution matching algorithm that aligns the policy’s output with the Best-of-N distribution. Using Jeffreys divergence, which balances mode-covering and mode-seeking behaviors, BOND iteratively refines the policy through a moving anchor approach. Experiments on abstractive summarization and Gemma models show that BOND, particularly its variant J-BOND, outperforms other RLHF algorithms by enhancing KL-reward trade-offs and benchmark performance.
Best-of-N sampling optimizes language generation against a reward function but is computationally expensive. Recent studies have refined its theoretical foundations, provided reward estimators, and explored its connections to KL-constrained reinforcement learning. Various methods have been proposed to match the Best-of-N strategy, such as supervised fine-tuning on Best-of-N data and preference optimization. BOND introduces a novel approach using Jeffreys divergence and iterative distillation with a dynamic anchor to efficiently achieve the benefits of Best-of-N sampling. This method focuses on investing resources during training to reduce inference-time computational demands, aligning with principles of iterated amplification.
The BOND approach involves two main steps. First, it derives an analytical expression for the Best-of-N (BoN) distribution. Second, it frames the task as a distribution matching problem, aiming to align the policy with the BoN distribution. The analytical expression shows that BoN reweights the reference distribution, discouraging poor generations as N increases. The BOND objective seeks to minimize divergence between the policy and BoN distribution. The Jeffreys divergence, balancing forward and backward KL divergences, is proposed for robust distribution matching. Iterative BOND refines the policy by repeatedly applying the BoN distillation with a small N, enhancing performance and stability.
J-BOND is a practical implementation of the BOND algorithm designed for fine-tuning policies with minimal sample complexity. It iteratively refines the policy to align with the Best-of-2 samples using the Jeffreys divergence. The process involves generating samples, calculating gradients for forward and backward KL components, and updating policy weights. The anchor policy is updated using an Exponential Moving Average (EMA), which enhances training stability and improves the reward/KL trade-off. Experiments show that J-BOND outperforms traditional RLHF methods, demonstrating effectiveness and better performance without needing a fixed regularization level.
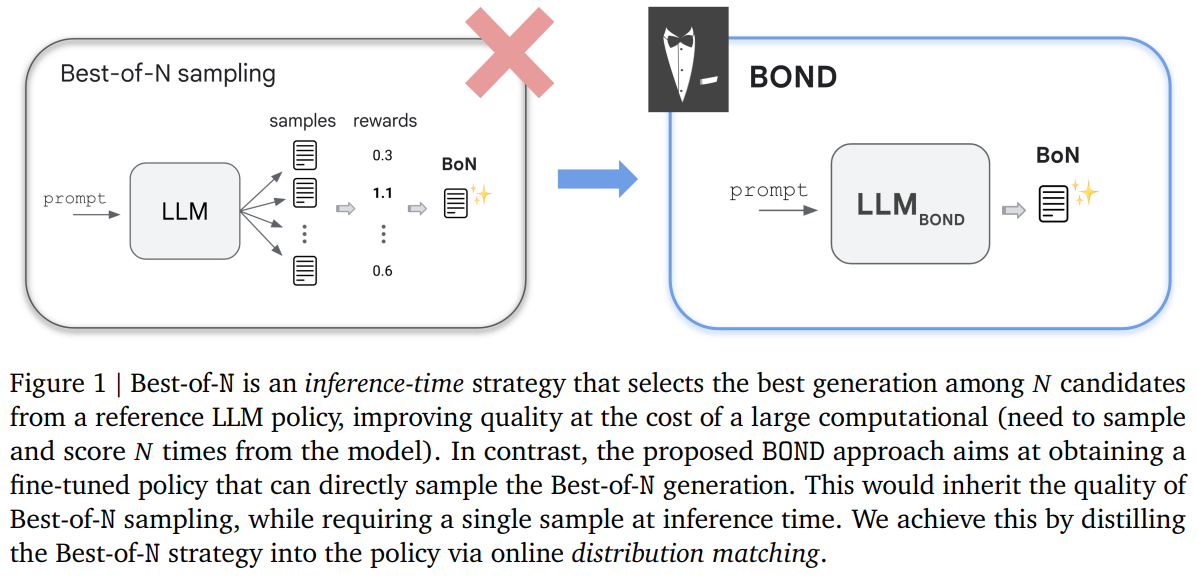
BOND is a new RLHF method that fine-tunes policies through the online distillation of the Best-of-N sampling distribution. The J-BOND algorithm enhances practicality and efficiency by integrating Monte-Carlo quantile estimation, combining forward and backward KL divergence objectives, and using an iterative procedure with an exponential moving average anchor. This approach improves the KL-reward Pareto front and outperforms state-of-the-art baselines. By emulating the Best-of-N strategy without its computational overhead, BOND aligns policy distributions closer to the Best-of-N distribution, demonstrating its effectiveness in experiments on abstractive summarization and Gemma models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Researchers at Google Deepmind Introduce BOND: A Novel RLHF Method that Fine-Tunes the Policy via Online Distillation of the Best-of-N Sampling Distribution appeared first on MarkTechPost.
