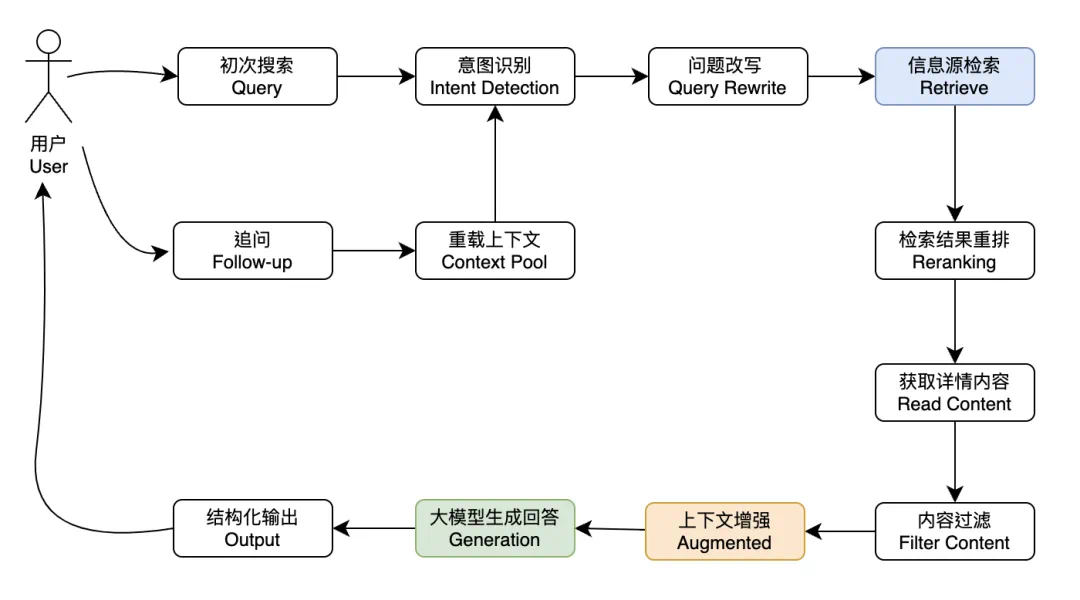
实现垂类 AI 搜索引擎 SOP?
# 确定三个核心问题:
1. source list 从哪些地方检索数据
2. answer prompt 使用什么提示词模板回复
3. llm model 使用哪个大语言模型回复
# 搜索前query rewrite:
1. 结合历史消息,判断当前 query 是否需要 retrieve
2. 结合历史消息,做指代消解,把代词替换成具体的名词
3. 从指代消解后的 query 提取关键词 keywords
# RAG 流程
1. 使用query + keywords 作为入参,从source list 获取检索结果(在线API检索+本地index检索),必要时可对 query + keywords 进行翻译,使用不同语言进行多轮检索
2. 检索结果聚合重排reranking
3. 获取重排后 top_k 条内容详情
4. 使用回复提示词 + 检索内容 + 历史消息作为 context,带上最新 query 请求 LLM 回复
# 主要工程量
1. 对内容源 build index
对于没有标准API的source,需要对source站点的数据构建索引。增量构建使用source的搜索框,存量构建使用搜索引擎网页快照,很难拿到某个 source 的全量数据
2. 更新 source 权重
系统预置权重 + 用户点击更新 source 权重,多信息源检索时依据 source 权重返回结果数量和初始排序
3. 多信息源重排
需要一个高效/快速的 reranking 框架,比如 FlashRank
4. 构建 chunk 内容池
对检索到的内容进行 chunk 拆分,存储向量数据库,挂载上下文请求 LLM 回答时,相似度匹配部分内容,避免暴力传输
5. 构建关键词库
定期分析历史 query,提取热搜关键词,构建关键词库。命中关键词库的 query,retrieve 环节走缓存
------
AI 搜索引擎,做一个容易,做好太难,细节太多,需要大量的雕花工作。
欢迎补充。