Andrej Karpathy 的《Let's reproduce GPT-2 (124M)》视频是学习大型语言模型(LLM)的宝贵资料,尽管视频长达4小时,但全程跟随学习将收益颇丰。视频中详细讲解了代码的增加与修改过程,但若直接使用最终结果repo中的代码运行,可能会遇到一些小问题。特别是在代码调用顺序上,需要特别注意才能复现视频中的效果。
🧩 视频中详细讲解了如何一步步增加和修改代码来复现 GPT-2,这对于理解大型语言模型的工作原理非常有帮助。但如果只是简单地运行最终repo中的代码,可能会错过这些重要的学习过程。
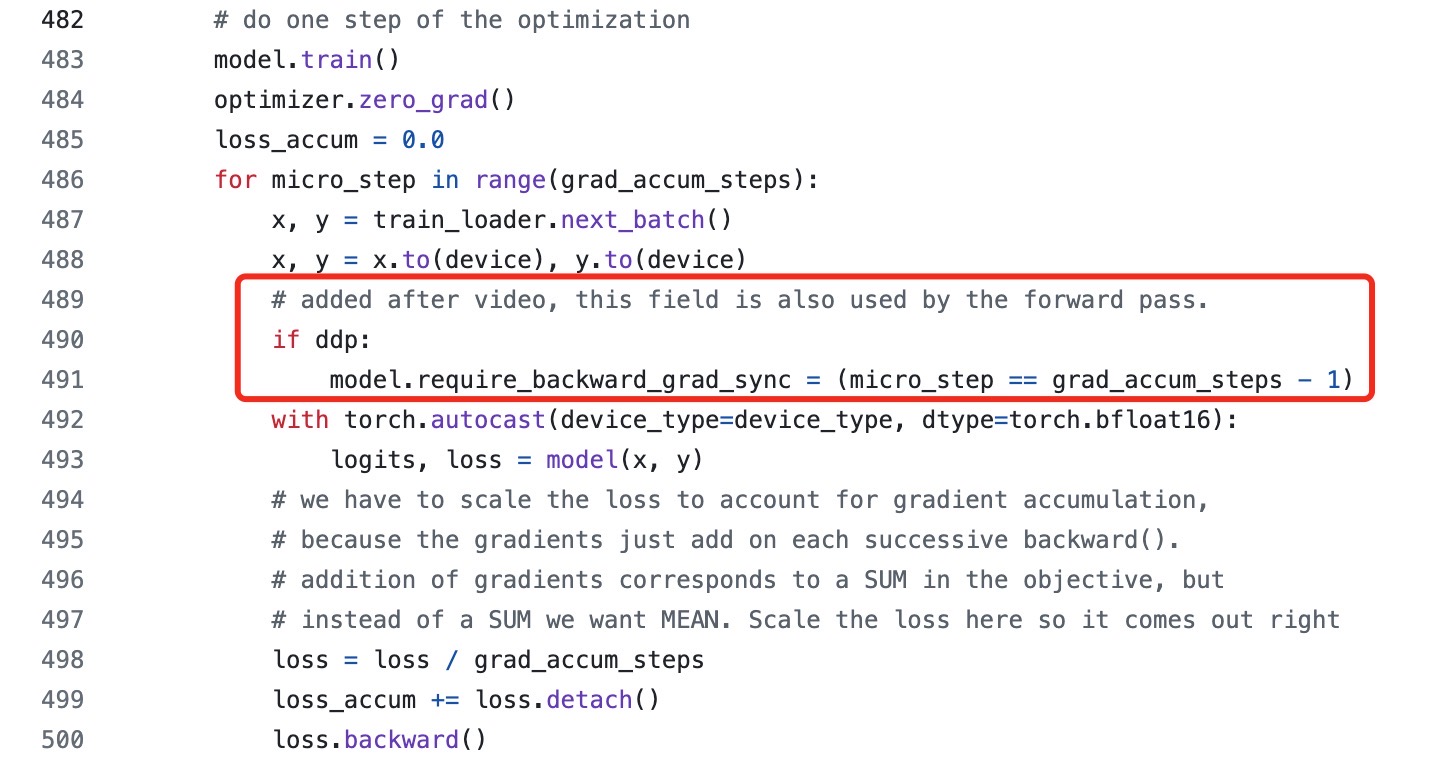
🛠️ 视频中一个关键的细节是在 L500 loss.backward() 之前调用的代码。如果忽略这个顺序,会导致 loss 和 HellaSwag eval 的效果不如视频中展示的那样好,甚至无法超越 OpenAI GPT-2 124M checkpoint。
🔍 正确的做法是在 forward pass 之前调用 model.require_backward_grad_sync,这样才能成功复现视频中的效果。这一点在repo中有“# added after video”的注释,需要特别注意。
Andrej Karpathy 的《Let's reproduce GPT-2 (124M)》视频真是学习 LLM 的至宝,虽然时间有点长(4小时), 但完整跟下来收获巨大,强烈推荐。
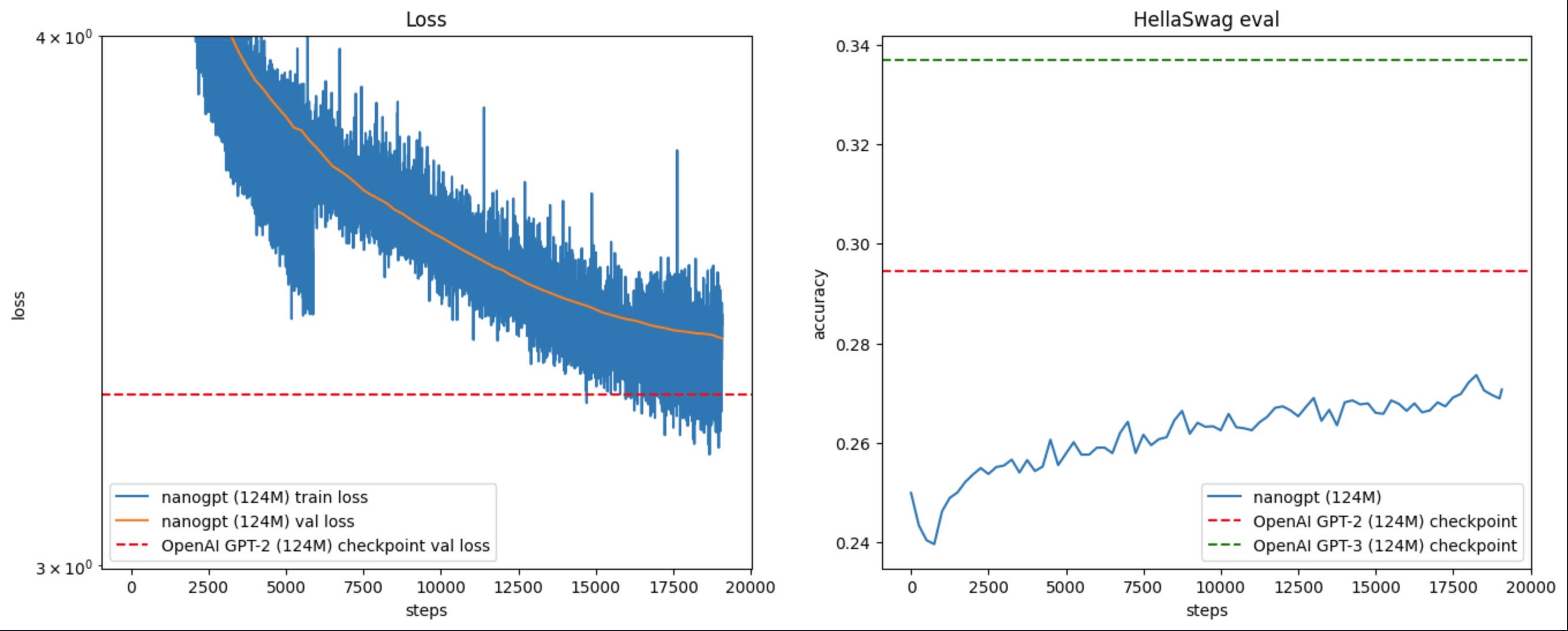
如果你和我一样,一步一步地跟着增加、修改代码,而不是拿着最终结果 repo 里的代码去直接运行的话,有个小坑:见图 1,红框中的代码,在原视频中是在 L500 loss.backward() 之前才调用的,但如果这么做的话,会导致 loss & HellaSwag eval 没有视频里的效果好,训练完成后没能超过 OpenAI GPT-2 124M checkpoint,见图 2。
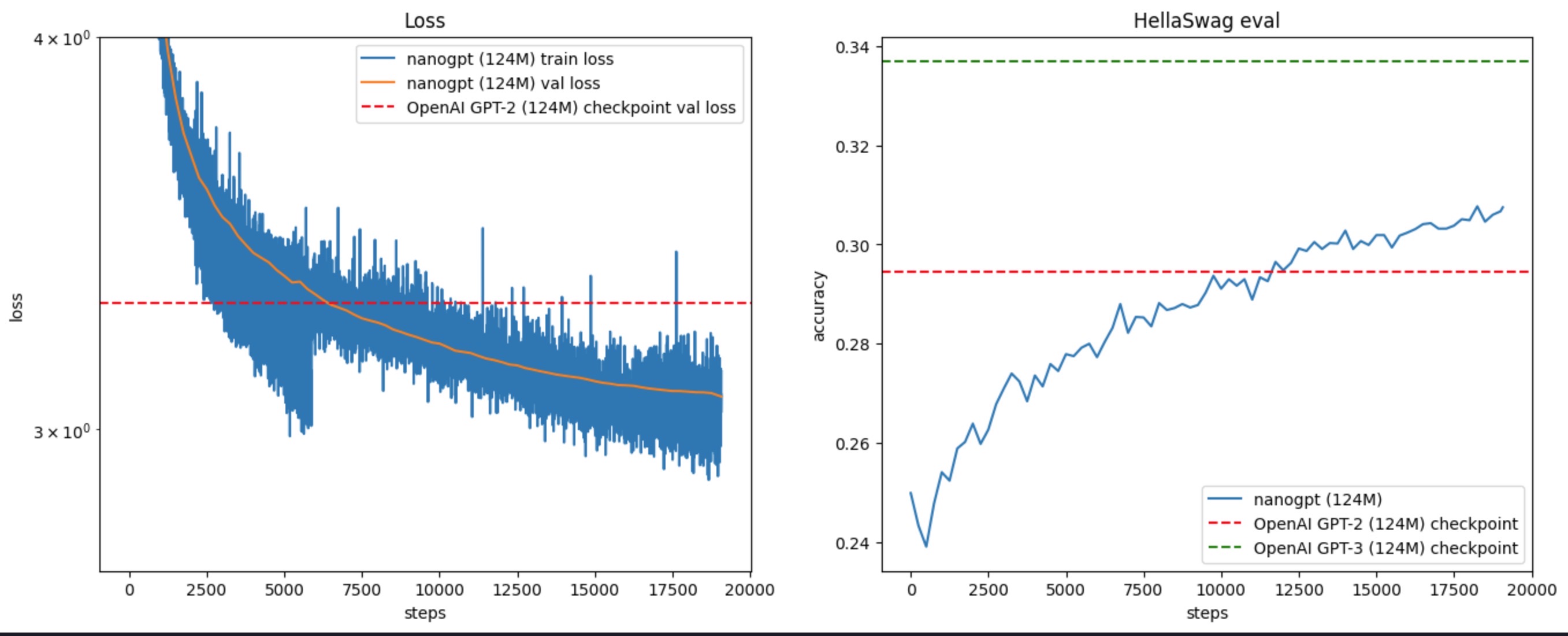
需要像红框中代码一样,model.require_backward_grad_sync 放在 forward pass 之前,就能成功复现出来了,参见图 3(所以要注意 repo 里带有“# added after video”的 comment?)