


Effectively evaluating document instruction data for training large language models (LLMs) and multimodal large language models (MLLMs) in document visual question answering (VQA) presents a significant challenge. Existing methods are primarily text-oriented, focusing on the textual content of instructions rather than the execution process, which limits their ability to comprehensively assess the quality and efficacy of instruction datasets. This shortcoming impacts the models’ performance in accurately processing complex document data, crucial for applications like automated document analysis and information extraction.
Current methods such as InsTag assess the diversity and complexity of instruction text but fall short in the document VQA domain due to the varied execution processes required by different document types and layouts. These limitations hinder the effective selection and filtering of high-quality instruction data, leading to suboptimal model training outcomes. Additionally, methods like Instruction-Following Difficulty (IFD) require additional model training, adding computational complexity and reducing practicality for real-time applications.
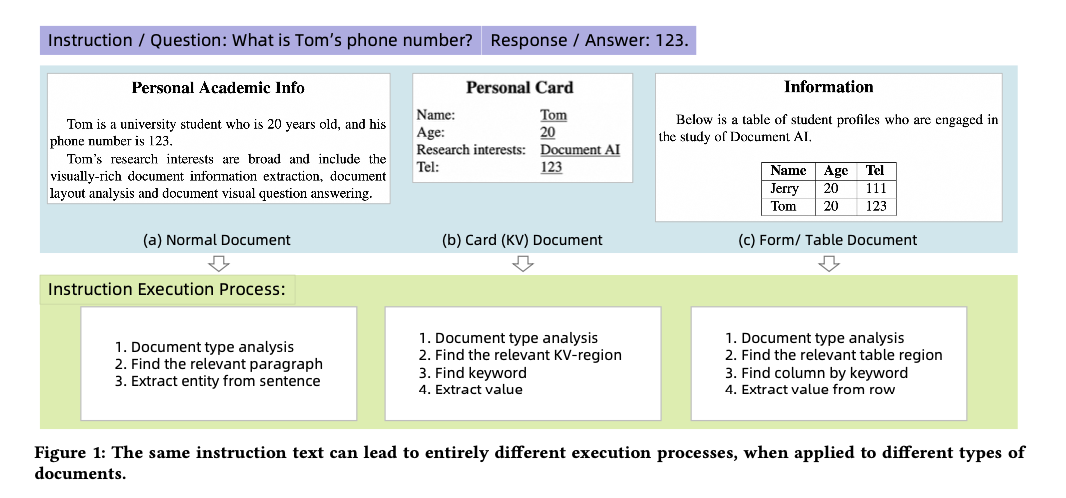
A team of researchers from Alibaba Group and Zhejiang University propose ProcTag, a novel data-oriented method that shifts the focus from instruction text to the execution process of document instructions. By tagging the instruction execution process, ProcTag evaluates the efficacy of instruction datasets based on the diversity and complexity of these tags. This approach enables a more granular and accurate assessment of the data’s quality. Additionally, DocLayPrompt, a semi-structured layout-aware prompting strategy, enhances document representation by incorporating layout information. This innovative approach significantly improves the training efficiency and performance of LLMs and MLLMs in document VQA tasks.
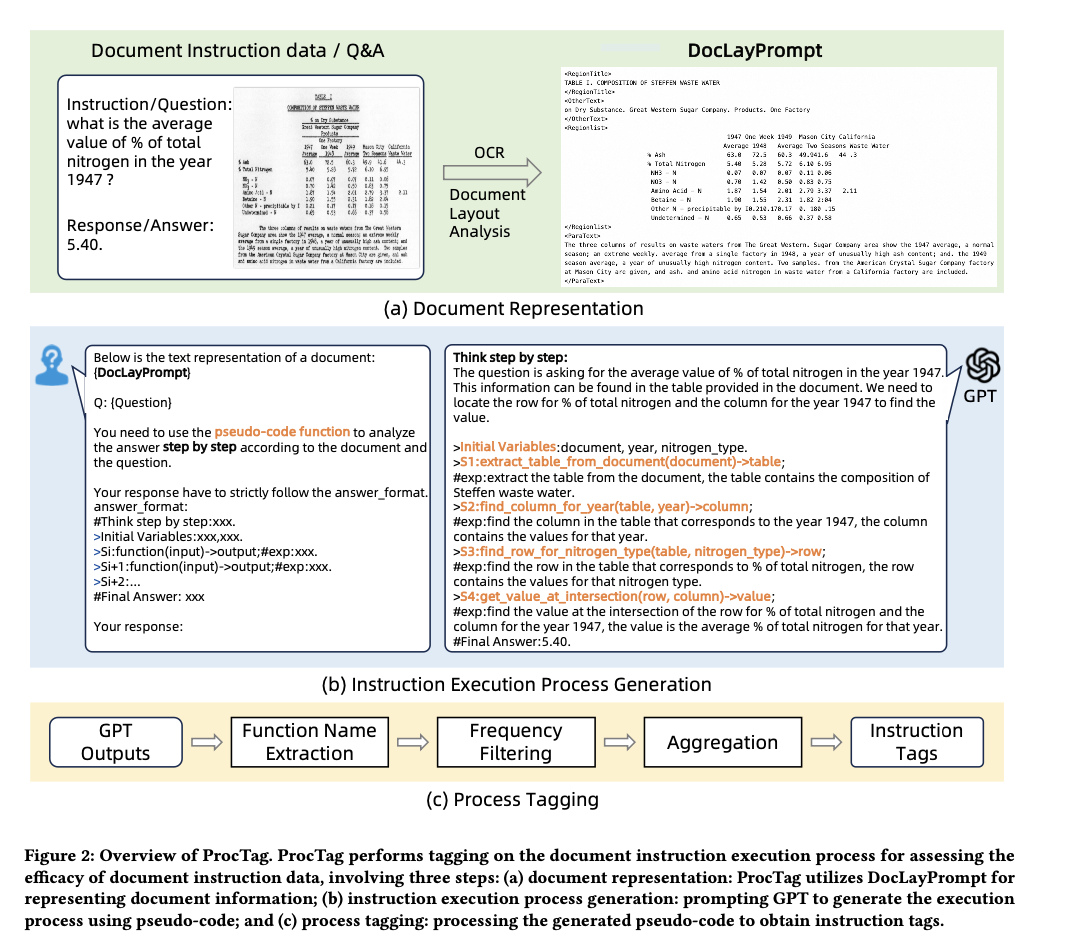
ProcTag employs a structured method to model the instruction execution process. First, it represents documents using DocLayPrompt, which integrates OCR and layout detection results to capture structural information. Next, GPT-3.5 is prompted to generate step-by-step pseudo-code for instruction execution, which is then tagged for diversity and complexity. These tags are used to filter and select high-efficacy data. The method is applied to both manually annotated datasets like DocVQA and generated datasets from sources such as RVL-CDIP and PublayNet. Key technical aspects include the use of non-maximum suppression to clean input data and the application of clustering algorithms to aggregate similar tags.
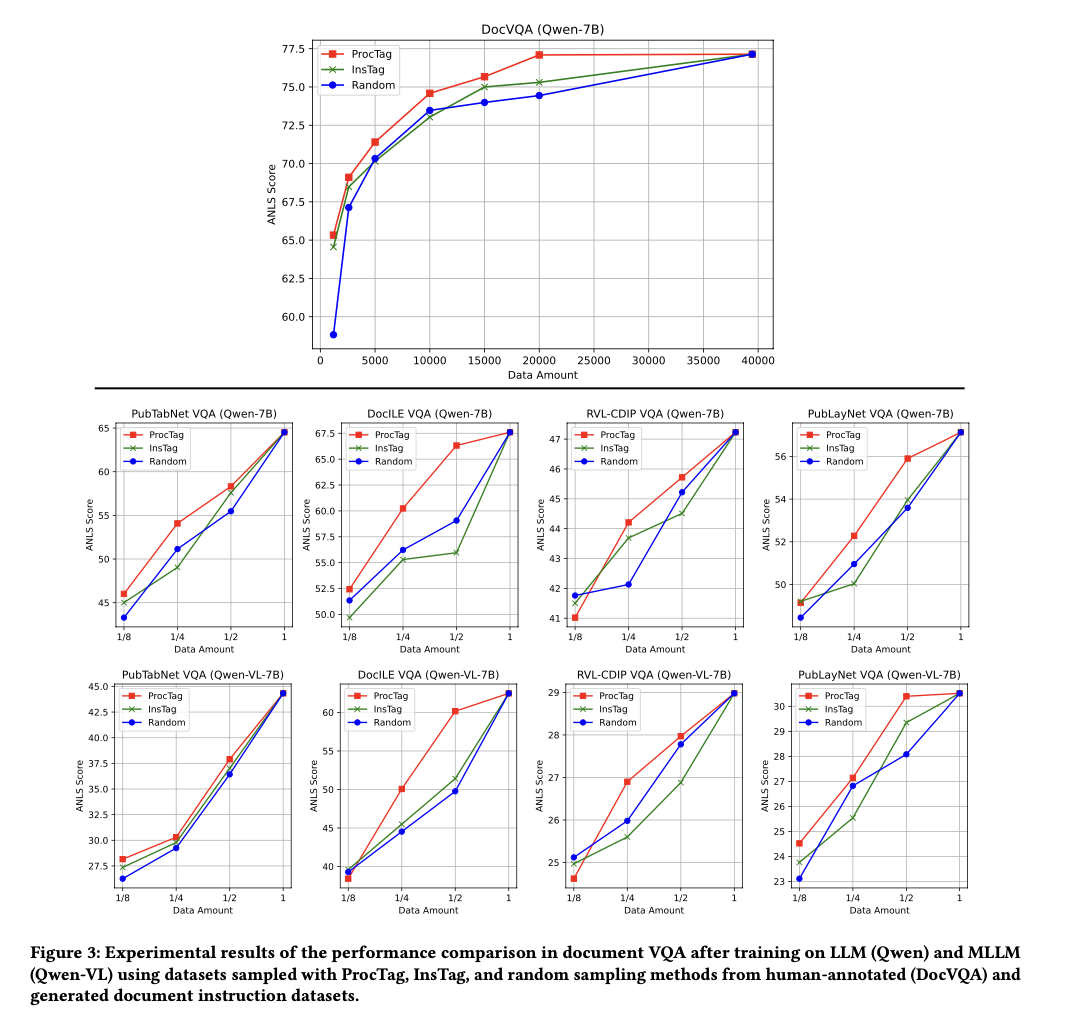
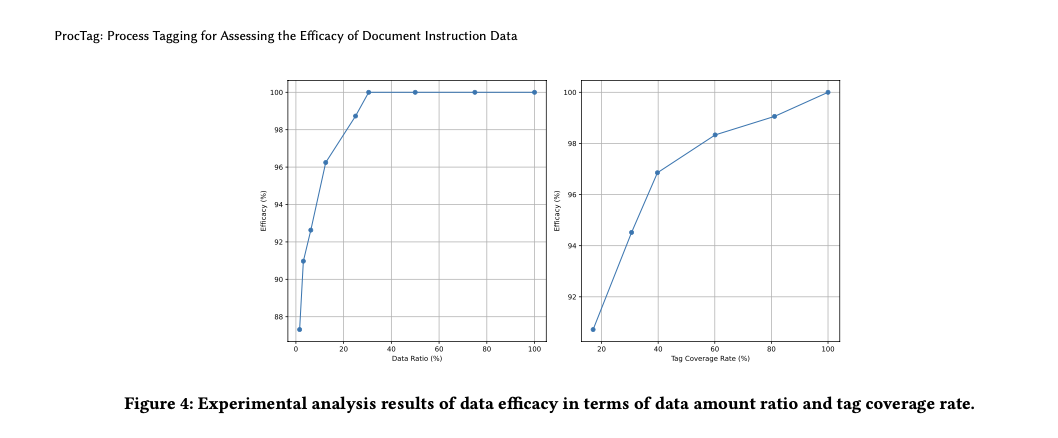
Comprehensive experimental results demonstrate that ProcTag significantly outperforms existing methods like InsTag and random sampling. Key performance metrics include the average normalized Levenshtein similarity (ANLS) score, where ProcTag-based sampling achieves superior efficacy with only a subset of the data compared to the complete dataset. For example, in the DocVQA dataset, ProcTag-based sampling achieved full efficacy using only 30.5% of the data. The experimental setup involved fine-tuning both LLMs and MLLMs, with consistent improvements observed across different data proportions and coverage rates. The approach proved particularly effective on diverse datasets, confirming its robustness and efficiency in improving model performance.
In conclusion, ProcTag is a novel method for assessing the efficacy of document instruction data through process tagging, and DocLayPrompt is a layout-aware document representation strategy. These innovations address the limitations of existing text-based evaluation methods, offering a more accurate and efficient approach to training LLMs and MLLMs for document VQA. The proposed methods demonstrate significant improvements in data quality assessment and model performance, advancing the field of AI by overcoming a critical challenge in document understanding.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
The post ProcTag: A Data-Oriented AI Method that Assesses the Efficacy of Document Instruction Data appeared first on MarkTechPost.
