


A major development in artificial intelligence, multimodal large language models (MLLMs) combine verbal and visual comprehension to produce more accurate representations of multimodal inputs. Through the integration of data from multiple sources, including text and images, these models improve understanding of intricate relationships between various modalities. Because of this integration, sophisticated tasks requiring a thorough comprehension of many kinds of data are now possible. As a result, MLLMs are a critical area of interest for contemporary AI research.
A primary challenge in multimodal learning is achieving effective representation of multimodal information. Current research includes frameworks like CLIP, which aligns visual and language representations using contrastive learning on image-text pairs. Models such as BLIP, KOSMOS, LLaMA-Adapter, and LLaVA extend LLMs to handle multimodal information. These methods often use separate encoders for text and images, leading to poor interleaved input integration. Moreover, they require extensive, costly multimodal training data and need help with comprehensive language understanding and complex visual-linguistic tasks, falling short of achieving universal, efficient multimodal embeddings.
To address these limitations, researchers from Beihang University and Microsoft Corporation introduced the E5-V framework, designed to adapt MLLMs for universal multimodal embeddings. This innovative approach leverages single-modality training on text pairs, significantly reducing training costs and eliminating the need for multimodal data collection. By focusing on text pairs, the E5-V framework demonstrates substantial improvements in representing multimodal inputs compared to traditional methods, offering a promising alternative for future developments in the field.
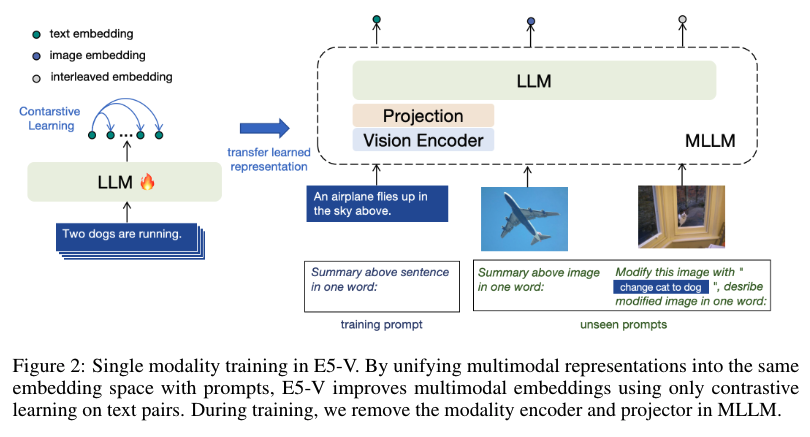
The E5-V framework employs a novel prompt-based representation method to unify multimodal embeddings into a single space. During training, the model exclusively uses text pairs, simplifying the process and cutting costs associated with collecting multimodal data. The key innovation lies in instructing MLLMs to represent multimodal inputs as words, effectively removing the modality gap. This method allows the model to handle highly accurate tasks like composed image retrieval. By unifying different embeddings into the same space based on their meanings, the E5-V framework enhances the robustness and versatility of multimodal representations.
E5-V has demonstrated impressive performance across various tasks, including text-image retrieval, composed image retrieval, sentence embeddings, and image-image retrieval. The framework surpasses state-of-the-art models in several benchmarks. For instance, in zero-shot image retrieval tasks, E5-V outperforms CLIP ViT-L by 12.2% on Flickr30K and 15.0% on COCO with Recall@1, showcasing its superior ability to integrate visual and language information. Furthermore, E5-V significantly improves composed image retrieval tasks, outperforming the current state-of-the-art method iSEARLE-XL by 8.50% on Recall@1 and 10.07% on Recall@5 on the CIRR dataset. These results underscore the framework’s effectiveness in accurately representing interleaved inputs and complex interactions.
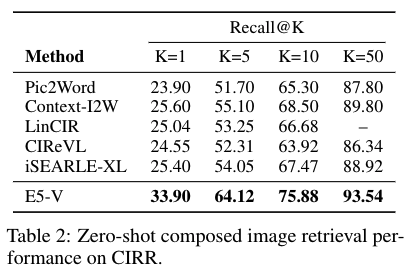
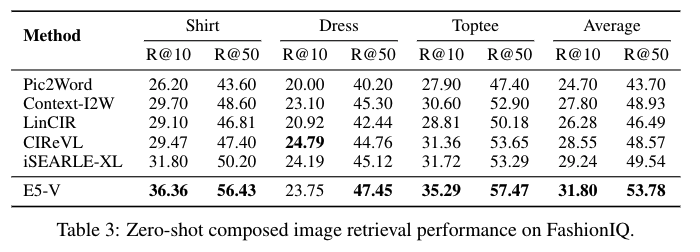
The researchers conducted extensive experiments to validate the effectiveness of E5-V. In text-image retrieval tasks, E5-V achieved competitive performance on the Flickr30K and COCO datasets. For example, E5-V demonstrated a Recall@10 of 98.7% on Flickr30K, outperforming models trained on image-text pairs. In composed image retrieval tasks, E5-V showed remarkable improvements, with Recall@10 scores of 75.88% on CIRR and 53.78% on FashionIQ, significantly higher than those of existing baselines. These results highlight E5-V’s ability to accurately represent multimodal information without requiring additional fine-tuning or complex training data.
In conclusion, the E5-V framework represents a significant advancement in multimodal learning. By leveraging single modality training and a prompt-based representation method, E5-V addresses the limitations of traditional approaches, providing a more efficient and effective solution for multimodal embeddings. This research demonstrates the potential of MLLMs to revolutionize tasks that require integrated visual and language understanding, paving the way for future innovations in artificial intelligence. The work of the research teams from Beihang University and Microsoft Corporation underscores the transformative potential of their approach, setting a new benchmark for multimodal models.
Check out the Paper, Model Card, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Microsoft Research Introduces E5-V: A Universal AI Framework for Multimodal Embeddings with Single-Modality Training on Text Pairs appeared first on MarkTechPost.
