


The recent development of large language models (LLMs) has transformed the field of Natural Language Processing (NLP). LLMs show human-level performance in many professional and academic fields, showing a great understanding of language rules and patterns. However, they often struggle with reasoning reliably and flexibly. This problem likely comes from the way transformers, the underlying architecture, work. They solve problems step-by-step, predicting the next word in a sequence, which limits their ability to backtrack and fix errors. Moreover, LLMs are trained statistically, which creates challenges in handling problems outside their training distribution.
Recently, many works have highlighted the combining of large language models (LLMs) with external tools and symbolic reasoning modules. For example, training LLMs to use tools like calculators, interpreters, or external datasets has improved their performance on various reasoning tasks. These methods are useful in reducing arithmetic errors in LLMs but they partially address the reasoning limits of the next-word prediction approach, used by LLMs. This approach and the linear nature of text can limit the ability to search broadly over possible solutions, explore multiple ways to solve a problem, or go back and try different paths.
Researchers from the University of California, Berkeley, have proposed integrating a reliable, deductive reasoning module into their inference pipeline. In their study, researchers prompted the model to encode the constraints and relationships as a set of Prolog code statements in variables explained in the problem statement. The Prolog evaluates the generated code using a deductive technique to provide a definite answer to the problem. The method also provides the benefit of reflecting the probable human architecture of separate linguistic and reasoning systems. It also greatly enhances the performance of LLMs for mathematical reasoning.
Moreover, researchers have introduced the Non-Linear Reasoning dataset (NLR), a new dataset created to test how well large language models (LLMs) can handle mathematical reasoning. This new dataset aims to address issues found in existing ones, such as overlap between test and training sets and the repetitive nature of reasoning patterns in current benchmarks. The NLR dataset ensures that it is not included in current models’ training sets, and each problem requires a unique and creative reasoning pattern to solve but is limited to basic arithmetic and algebra skills. This benchmark contains unique constraint problems, math word problems, and problems related to algorithmic instructions for updating a game model.
To show how much variable entanglement affects the model’s performance, instances with similar structure and reasoning patterns are created but with different numbers of entangled variables for five math word problems and five algorithmic instruction problems in the NLR dataset. GPT-4’s ability to solve these problems drops significantly as the number of entangled variables increases. It fails to solve problems related to four entangled variables when given the standard CoT in the text. Two more experiments are carried out on the NLR dataset using GPT-3.5 Turbo and GPT-4. The first series compares the average performance of the model to the text-only CoT prompting baseline across all problems.
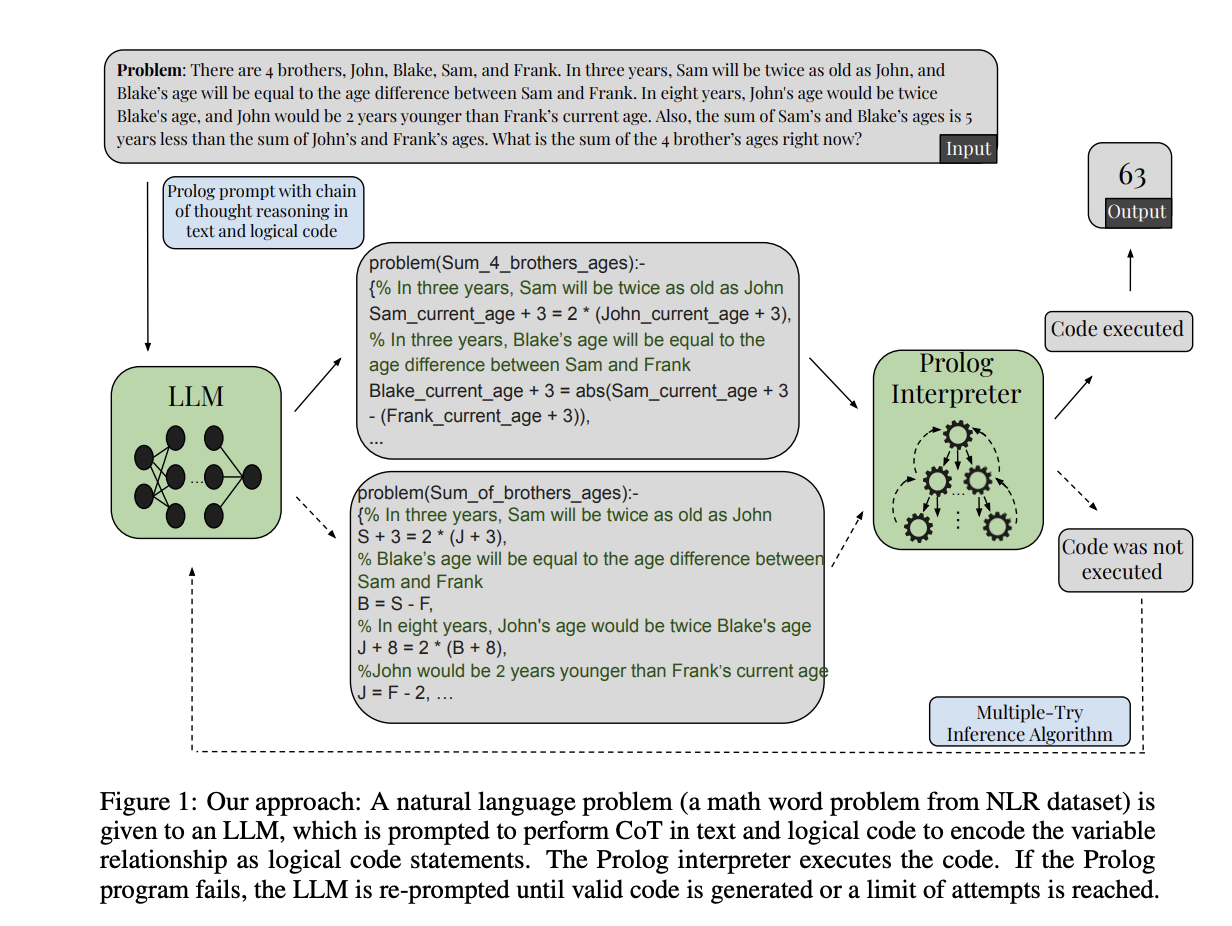
In conclusion, researchers have introduced integrating a reliable, deductive reasoning module into their inference pipeline. In this paper, the inherent limitations of LLMs are highlighted in performing reliable and general reasoning. The neurosymbolic approach prompts the LLM to convert the information encoded by problem statements into logical code statements, and this division of labor significantly improves the LLMs’ performance on mathematical reasoning tasks. Moreover, the proposed NLR dataset provides a strong benchmark for testing LLMs’ ability to handle problems that need unique nonlinear reasoning and challenge the usual linear next-word prediction approach of LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
The post This AI Paper from UC Berkeley Shows How Interfacing GPT with Prolog (Reliable Symbolic System) Drastically Improves Its Math Problem-Solving Abilities appeared first on MarkTechPost.
