
Published on July 22, 2024 5:16 AM GMT
This is an informal progress update with some preliminary results using Sparse Autoencoders (SAEs) to detect AI-generated text.
Summary
I would like reliable methods for distinguishing human and AI-generated text. Unfortunately, not only are the current best methods for doing this unreliable, they are also opaque: based on training large neural networks to do the classification for us. Fortunately, advances in AI interpretability, like Sparse Autoencoders (SAEs), have given us methods for better understanding large language model (LLM) internals. In this post, I describe some early experiments on using GPT-2-Small SAEs to find text features that differ between AI and human generated text. I have a few main results:
Linear classifiers trained on SAE activations perform slightly better than a variety of simple baselines[1], in line with recent results from Gao et al. (2024, Appendix H)
Using only the top few SAE neurons (e.g., 4 rather than 24,576) for classification still performs well.Manual inspection of these top-differentiating neurons yields mixed results. Some seem to be representing understandable concepts, largely activating for specific words or ngrams (sequence of characters), but I was unable to understand others. Using ngram-frequency for classification performs worse than correlated SAE neurons, indicating that these SAE neurons are probably representing something more complicated than merely ngrams.One major limitation is that I use a simple and non-adversarial setting — the AI generated text is all generated by GPT-3.5-Turbo and in response to similar prompts. On the other hand, the task of “classifying GPT-3.5-Turbo vs. human text” is off the training distribution for both GPT-2 and the SAEs, and it’s not a priori obvious that they would represent the requisite information. Working on this project has left me with the following high-level outlook about using SAEs for AI text detection:
- There is plenty of obvious follow-up work here which I expect to succeed without much effort, but it’s not high on my priority list. It seems very easy to make pareto improvements along the Effectiveness vs. Understandability axes of AI text detection.AI text detection appears to be one of the best problems to apply approaches like “Microscope AI,” where we use interpretability tools to learn useful knowledge that AI models picked up during training.LLMs with SAEs are plausibly a useful tool for linguistic analysis more generally — they take the deep representations of language and knowledge built by LLMs and make it at least partially understandable to humans.
Experiments
General Methods
- I use the text samples from the CHEAT paper; the human-written texts are each an abstract of a paper. The AI generated texts (“Generated” in the paper) are all generated by GPT-3.5-Turbo using similar prompts, including the instruction to generate an abstract to a paper based on the paper title and keywords.I balance the dataset. I use 3,000 samples for development (2,250 for explicit training and 750 for testing) and 2,000 as a held-out-validation which is not used during development.I truncate all samples to 49 tokens (approximately the length of the shortest) or the average corresponding character count for non-token-based methods. For classification of activation-based methods, I take the mean of the activations along the sequence dimension, resulting in a vector of length 768 for model activations and 24,576 for SAE activations, for each text sample.I use TransformerLens’s GPT-2-Small (hereafter just “GPT-2”) and SAEs trained by Joseph Bloom on the pre-layer residual stream. I focus on pre-layer-8 activations/SAEs due to good classification accuracy on this layer and to avoid the memory issues with storing all layer activations.
For classification, I use simple, one-layer, binary logistic regression classifiers from sklearn. I typically apply a MaxAbsScaler to the data (PCA gets StandardScaler first), and take the better classifier between training the classifier with L1 and L2 penalties.[2]
Linear classifiers on SAE neurons perform better than reasonable baselines
To test how SAE-based classifiers compare to other classifiers for this task, I train simple logistic regression classifiers on a variety of data. In addition to comparing SAE and GPT-2 activations at all layers (Figure 1), I do more analysis at layer 8 (chosen for the high classification accuracy of GPT-2 activations in development). I include the following baselines:
- SAE reconstructions of activations; chosen for convenienceNgram counts using CountVectorizer, including a version that merges the result of parameter choices and a simple version (basic word/n-gram counter); chosen because it is similar to TF-IDF but did better in my early testing.TF-IDF, a more complicated version of ngram frequency; chosen because previous papers have had success using it for AI text detection, e.g., Liu et al. (2023) find that there are numerous ngrams that are more likely in human or AI-generated text (Table 13).A combination of various standard linguistic features such as Flesch Reading Ease and noun count; chosen because previous papers have had success using these for AI text detection, e.g., Uchendu et al. (2020) find that human text has a much lower Flesch Reading Ease score than AI generated texts (but this did not study recent models); Crothers et al. (2022) find that Flesch and Gunning-Fog scores are important for their classifier; Guo et al. (2023) find some differences in their parts of speech comparison between ChatGPT and human text.Embeddings of the texts from OpenAI’s text-embedding-3-small; chosen as a general comparison to SAE performanceTop PC transformations for PCA of GPT-2 activations; chosen as a general comparison to SAE performance
I chose these baselines to get some mix of “obvious things to compare SAEs to” and to cover other linguistic feature methods which are human-understandable and have been found to be effective in previous work.[3]
Figure 1
Besides the first few layers, classifiers on SAE activations slightly but consistently outperform GPT-2 activations at every layer. Classifiers are fit on the train set; these results are on a held-out validation set not used during development. Results on the development test set, which motivated the focus on layer 8, are similar. Note the y-axis scale.
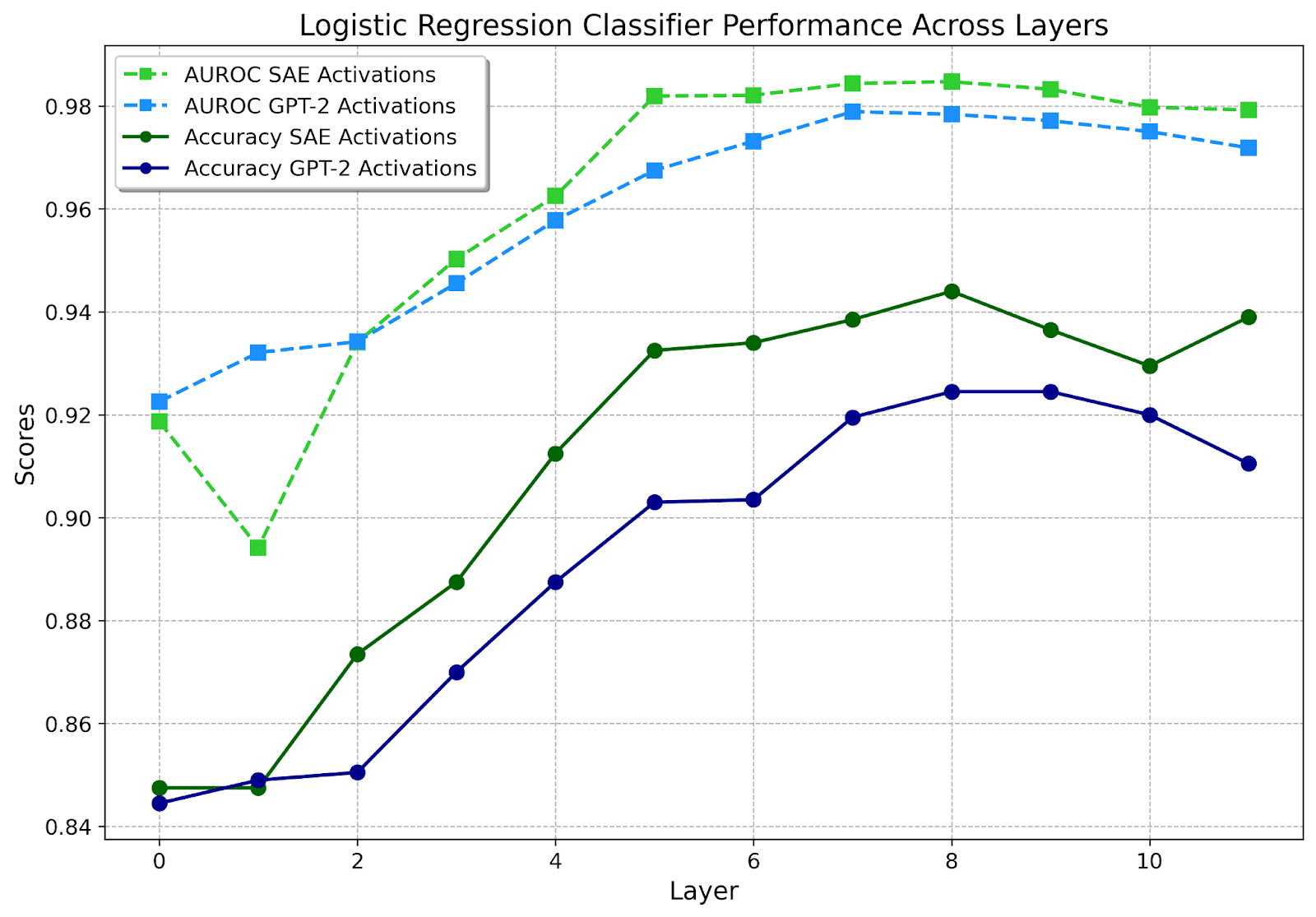
Table 1
Performance of different methods on held-out validation set (except Dev Test Acc which is from the test set used in development). GPT-2, SAE, SAE Reconstructed, and PCA results are all based on just the pre-layer 8 residual stream.
| Method | Accuracy | F1 Score | AUROC | Dev Test Acc | # Features |
| GPT-2 Activations | 0.924 | 0.924 | 0.978 | 0.919 | 768 |
| SAE Activations | 0.944 | 0.944 | 0.985 | 0.941 | 24576 |
| SAE Reconstructed Acts | 0.918 | 0.919 | 0.975 | 0.908 | 768 |
| Ngram Count Full | 0.909 | 0.909 | 0.973 | 0.885 | 104830 |
| Ngram Count Simple | 0.904 | 0.902 | 0.968 | 0.897 | 5570 |
| TF-IDF Simple | 0.902 | 0.901 | 0.964 | 0.881 | 5570 |
| Linguistic Features | 0.654 | 0.661 | 0.709 | 0.645 | 12 |
| Text Embedding 3 Small | 0.85 | 0.848 | 0.927 | 0.833 | 1536 |
| pca_1 | 0.614 | 0.624 | 0.643 | 0.648 | 1 |
| pca_2 | 0.688 | 0.689 | 0.757 | 0.695 | 2 |
| pca_32 | 0.886 | 0.886 | 0.951 | 0.881 | 32 |
Using only a few SAE neurons still works well
Given that SAE activations are effective for classifying AI and human generated text in this setting, it is natural to ask whether using only a few SAE neurons will still work well. The ideal situation would be for a few neurons to be effective and interpretable, such that they could be replaced by human-understandable measures.
Starting with all 24,576 SAE neurons at layer 8, I narrow this down to a short list of SAE neurons that seem particularly good for classifying AI-generated vs. human-generated texts. I apply a kitchen-sink style approach to narrow this down with various methods: logistic regression and selecting large weights (i.e., Adaptive Thresholding), Mann-Whitney U test, ANOVA F-value, and more. That gets to a short list of ~330 neurons, but this length is arbitrary based on hyperparameters set in an ad hoc manner. With a short list like this, it is feasible to directly apply sklearn’s RFE with a step size of 1 (Adaptive Thresholding is RFE with a step size equal to 0.5*n, or step=0.5, as far as I can tell): train a classifier on n features, eliminate the single worst feature by coefficient absolute value, repeat until you reach the desired value of n. Here is the performance of classifiers trained for different top-n neurons:
Figure 2
Performance of classifiers trained on increasingly small sets of SAE neurons / "features", specifically area under the curve and accuracy. Top SAE neurons and their classifiers are fit on the train set; these results are on a held-out validation set not used during development. Results on the development test set are similar.
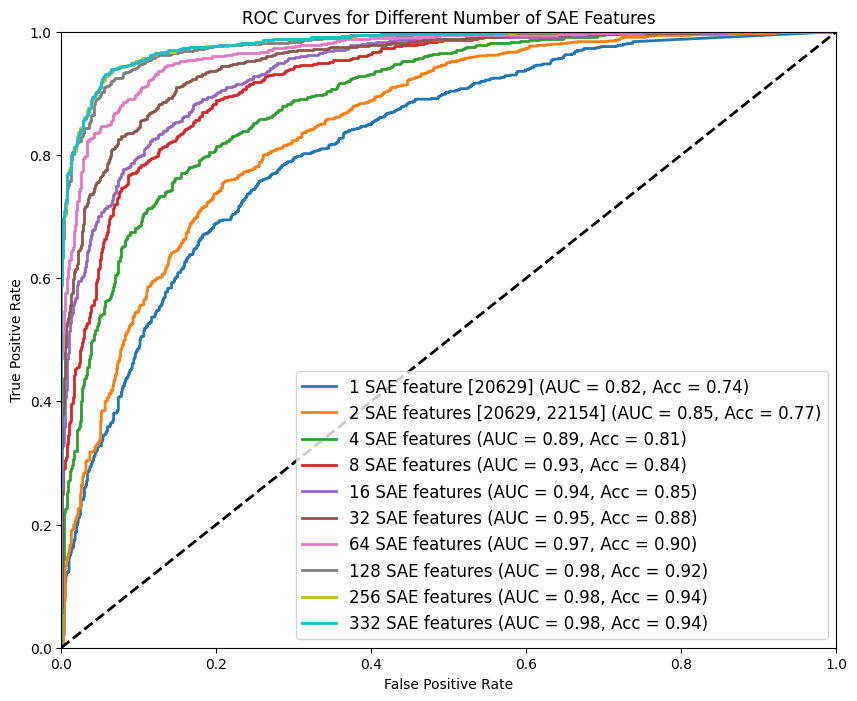
That’s exciting! Using only a few of the top neurons is still effective for classification.
What are these neurons doing?
One hypothesis for what’s going on is that these top SAE neurons correspond to specific ngrams whose frequency differs between the two texts. For instance, some people have observed that ChatGPT uses the term “delve” much more than human authors — maybe one of the SAE neurons is just picking up on the word “delve”, or this dataset’s equivalent. Some of my manual inspection of top-activating text samples also indicated SAE neurons may correspond closely to ngrams. If this hypothesis were true in the strongest form, it would mean SAEs are not useful for text analysis, as they could be totally replaced with the much easier method of ngram counting.
To test this hypothesis, I obtain ngram counts for words in the text, in particular I use CountVectorizer and an ensemble of a few parameter choices. This is important because using just analyzer=’word’ would miss important details, e.g., one common ngram in AI generated text on my dataset is “. The” (starting sentences with “The”). I then obtain correlation scores for each SAE neuron and each of the 104,830 ngrams in this vocabulary and graph the highest correlation that each SAE neuron has with an ngram (note this is an imprecise method because it compares sequence-level counts/means, but the underlying thing being predicted would be closer to the word or token level).
Figure 3
Compared to all SAE neurons, the top-differentiating neurons have, on average, higher max correlations with an ngram; data is from the Train Set, y-axis is log scaled.
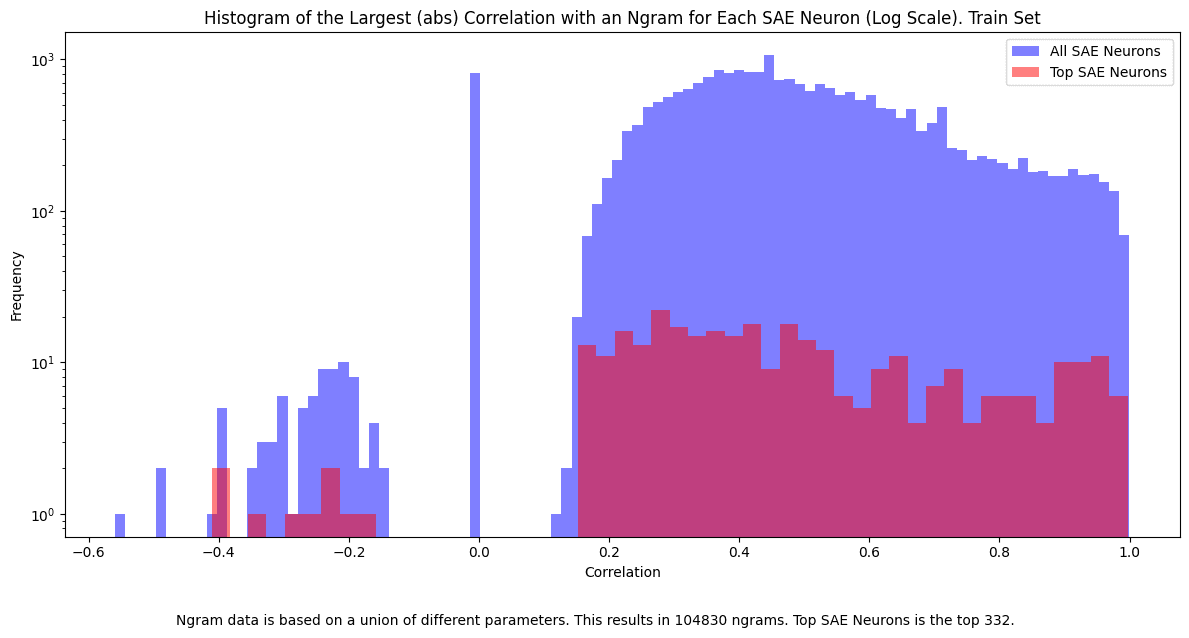
These top-differentiating neurons seem to be more ngram-related than average SAE neurons. Another test that can bear on this relationship between SAE neurons and ngrams is to get the highest correlating ngrams for a given SAE neuron and compare their classification performance against that of the SAE neuron. I do this for the top-16 differentiating SAE neurons. Rather than directly looking at the top k ngrams, I take the top 1024 correlating and apply RFE for classification performance — so this doesn’t represent the result of the top-k correlating ngrams. For many of these, 8 highly correlating ngrams is enough to match their performance, and for a couple, around 70% accuracy can be achieved with just 2 ngrams. I also manually inspect a few of the top SAE neurons.
Generally, these top-differentiating SAE neurons don’t seem particularly easy to understand, but they are interesting. I didn’t put very much effort into interpreting them, nor did I use the best existing techniques, so I expect more time and effort would come up with better explanations. Here are some notes on the 4 best differentiating SAE neurons I find:
- SAE neuron 20629 seems slightly ngram related. High activations on “of”, “in”, “for”, in context like, “led to the emergence of”, “resulted in the development of”. This is the case both on my dataset and Neuonpedia. No high correlating ngrams however.SAE neuron 23099 is sometimes activating on lists, both the commas and elements in the list. Unclear. On Neuronpedia it appears to be related to “consider”, but pretty unclear what it’s doing overall.SAE neuron 3657 activates a lot on the first noun in a sentence following “this” or “the”, e.g., “The tool”, “This paper”, “This study”. 0.66 correlation with “this” and 0.65 correlation with “ paper “ and “this paper” token. Neuonpedia shows similar high activating samples.SAE neuron 22154 has -0.18 correlation with “this paper” token — huh. Seems to highly activate on grammatical mistakes, or tokens that seem very unlikely based on grammar rules. E.g., “However, it have curse of dimensionality”, “Cooperation with the first will allow to produce”, “SE allows to determine”, but not all high activations have mistakes. Neuronpedia examples show a similar case of these errors, and the automated explanation missed it, saying “technical terms related to data analysis and technology”. When I looked at this neuron’s activations a few weeks ago, I wrote “Lots of tokens activating, in the context of attacks, security, unclear” and thought Neuronpedia agreed. Now I think it’s likely related to mistakes, a good reminder that we often see what we want to. This is one of the few top-differentiating neurons that is more common in the human text!
One of the goals of this project is to generate human-understandable information from SAE neurons such that we can do AI text detection in a more manual (or automated without AIs) and safe way. I therefore also run Adaptive Thresholding + RFE on ngrams — ngram counting is highly understandable and it would be convenient if a few ngrams could be effectively used for AI text detection.
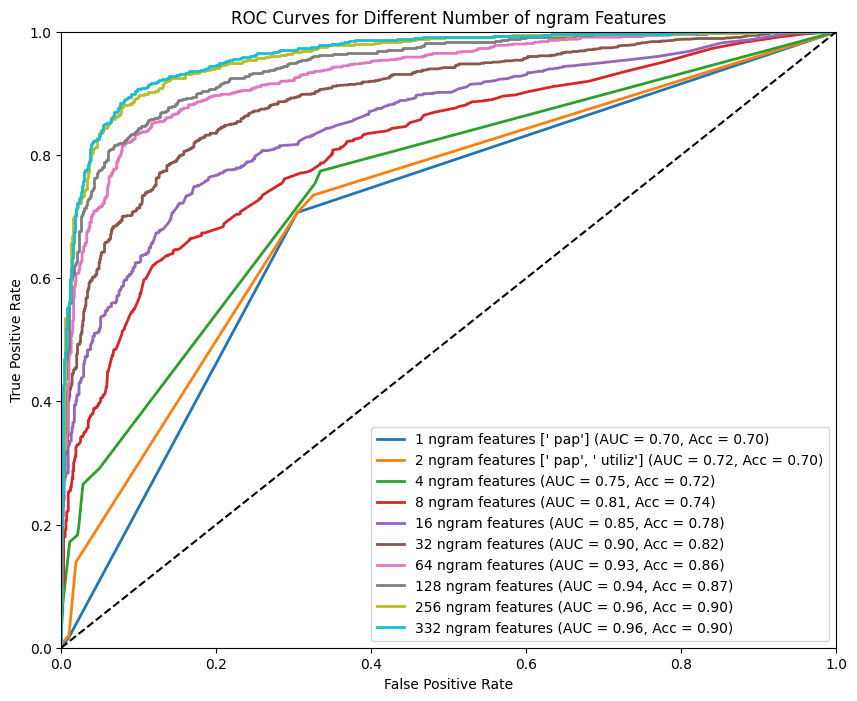
Figure 4
Top ngram performance on held-out validation set. Using a small number of ngrams underperforms using a small number of SAE neurons, but it is still impressive.
Discussion
Motivation
AI text detection is an important problem
This topic has been discussed at length elsewhere, and I don’t have too much to add: detecting AI generated text and the “digital fingerprint” of AI agents seems beneficial for mitigating negative societal impacts in a world with AIs running around autonomously or being used by malicious actors.
Separately, I think AI text detection, or at least some subsets of it, may be useful for reducing large scale risks when AIs are being run under Control protocols (i.e., without Rogue Deployments). Two particular risks come to mind: collusion, and sandbagging + exploration hacking (which in some sense is a form of collusion).
Collusion could arise from multiple AI systems sharing malicious information, for example an AI who is being evaluated by other AIs trying to bargain with them. Without explicit communication, there are certainly some risks from collusion, but AIs being able to reliably communicate with each other likely makes it easier for them. Therefore, if we can make it difficult for AIs to know whether they are talking to other AIs or human red-teamers, plotting is more difficult. This is relevant to AI text detection from a somewhat counterintuitive angle: creating AI generated text that is indistinguishable from human text might be good here, as it prevents AIs from colluding via direct communication. Studying AI text detection, and the mechanisms AIs themselves use for AI text detection, could help prevent collusion risks.
Sandbagging is a risk where an AI strategically underperforms during evaluation to hide its true capabilities. Exploration hacking is a version of sandbagging where an AI is being trained in a non-supervised setting and the AI is able to hide its capabilities by never taking high-performance actions during training. In a supervised setting, we should be able to disincentivize the cognition that caused the model to sandbag, because we have known high-performance trajectories that we can train on (i.e., push the model’s cognition so it is more likely to pursue them). Successfully pulling off an exploration hacking strategy would require identifying when you are in a supervised or RL setting. In particular, a model might try to identify whether a copy of it, some other model, or humans, are responsible for creating the data it has seen so far in the problem/solution — if all the reasoning so far was human generated, this is more likely to be a supervised setting. Similar to collusion, understanding to what extent AIs can detect human vs. their own vs. other AI generated text may help mitigate this problem. Note that collusion and sandbagging risks are may not actually occur in the real world; it’s important to have empirical work to determine how likely they are so we can prioritize defensive resources.
It might be time for narrow “Microscope AI”
Microscope AI, as introduced by Chris Olah and discussed by Evan Hubinger, is an approach to AI safety in which we build powerful AI systems, but rather than directly running these AIs — which may pose various dangers — we extract knowledge they have learned about the world, and directly apply that knowledge ourselves (or via some safe process). There are two large hurdles with Microscope AI: capabilities (we need AIs that have actually learned novel and interesting insights) and interpretability (we need to be able to extract that knowledge and transform it into human-understandable terms). For most domains or tasks I want to solve, I don’t think the capabilities are there; and the interpretability tools are still in their early stages. However, I think some domains might be a good fit for narrow applications of this approach.
AI text detection is a particularly good area for this
There are a few reasons AI text detection looks like a good fit for trying Microscope AI:
- The level of human knowledge is limited or implicit: Humans aren’t very good at detecting AI generated text. For instance in one paper, they score only slightly better than chance, and that’s with AI-generated text samples from various models which are all dumber than GPT-3.5-Turbo. In another paper, both GPT-3.5 and GPT-4 effectively pass a Turing Test — being classified as human by human judges at least 50% of the time (though the rate of this is lower than for human competitors). Where people do have knowledge about AI text detection, it seems mostly implicit and hard to verbalize, so this might be a good place for new measurement tools to help make things more concrete.LLM training likely incentivizes performance on this task: The pretraining objective for LLMs, minimizing prediction error on next tokens of internet text, seems to highly incentivize identifying the source of text. An AI which knows whether some particular text was generated as part of a Wikipedia article or part of a Reddit comment will likely do better at predicting the next tokens than an AI which does not (at least implicitly) distinguish between these — knowing the generating procedure that produced some text is highly useful for predicting the text that is likely to come next. On the task of predicting next tokens, LLMs as small as GPT-2-Small outperform humans. Compare this to e.g., the task of solving algebra questions — the cognition used for solving algebra problems seems much more localized to a small amount of the training data, rather than being relevant practically all the time. Previous work indicates LLMs are good at AI text detection, both with and without training for this explicitly: Without specific fine-tuning, Llama-2-7b-chat can weakly discern its own summaries from human written summaries in some testing setups. More importantly, many of the current best methods for AI text detection rely on training neural networks, see e.g., many top solutions to a recent Kaggle competition, commercial products doing AI text detection, and various papers. It is empirically the case that fine-tuned LLMs are highly performance at AI text detection — I think they are probably the best method but I haven’t crawled the literature enough to be confident.[4] Looking ahead, neural network-based AI text detection may scale along with AI capabilities and be related to risks: First, AI capability scaling may include scaling of AI-text-detection capabilities, meaning techniques like this get better over time and in lockstep with other AI capabilities. Second, some of the reasons to care about AI text detection are closely related to an AI’s ability to detect AI generated text. As discussed earlier: AIs colluding with one another may strongly benefit from their ability to know they are talking to a trusted source (e.g., another AI) (but communication is not strictly necessary); exploration hacking may also benefit from knowing whether inputs were generated by you, another AI system, or humans. This is exciting because it means that it will either be the case that AIs can’t distinguish human from AI text, in which case these threats are partially reduced, or AIs can make this distinction and we can potentially learn the distinction from them.
Potential Next Steps
There are many ways to keep going on this project. In no particular order, I think some of the important ones are:
- Use better methods and more effort to figure out what the SAE neurons are doing.Use bigger models and their SAEs — presumably their SAE neurons will be more interesting.Finetune a model for the classification task (or grab an existing one) and then train SAEs on it.Train SAEs for AI text detection, while freezing your LLM.Use “harder” datasets that were designed adversarially.Once you think you’ve found some important insights from your LLM+SAE pipeline, see if these insights cause humans to do a better job with AI text detection (initially, use good LLMs as a proxy for humans because of cost and convenience).Try to develop a clear framework for the Effectiveness vs. Understandability dimensions here.Compare to stronger and better baselines. Look for and test other methods that try to make AI text detection more transparent. GLTR is one such method: it indicates to a human user how likely tokens are (i.e., whether each token was in the top-k highest logit tokens) for a reference LLM, and this helps human raters distinguish between human and AI generated content because AI content usually lacks the unlikely words.Spend more time on the literature review and fit this work into the literature better. There’s lots of previous work on AI text detection and I didn’t read nearly all the things that it would have been good to read.
Considerations in working on this
I won’t continue working on this project, but if somebody else wants to push it forward and wants mentorship, I’m happy to discuss. Here are some reasons to be excited about this research direction:
- I put in basically no effort towards making SAEs look good, and the results are still decent. I don’t train the model or SAEs, and I don’t experiment much with design choices like: the length of sequences, classifying on a sequence average vs. token basis, and how to identify top-differentiating SAE neurons. These results are much closer to “run an initial test” than they are to “optimize hyperparameters to make the method look really good”.GPT-2 is (presumably, I didn’t run a full test) not even good at classifying these texts via prompting, and yet the internal activations can be used for highly performant classification. Applying this method with bigger models might just be way better.There are lots of clear and tractable next steps, and progress seems straightforward. I don’t think the background level of knowledge or skill needed is very high — ChatGPT and Claude wrote most the code for me.AI text detection is important for various reasons and thus can appeal to different conferences and communities.It’s pretty cool to apply SAEs to a real world problem, and maybe it will actually be useful!
But ultimately I won’t be working on this more. The main reasons:
- I’m busy with other things.I don’t think this project is particularly important for catastrophic risk reduction; I think it’s slightly relevant, but it is certainly not what I would work on if I was mainly trying to reduce large scale harms. There’s so much other more important stuff to do.
Appendix
Random Notes:
- When doing Adaptive Thresholding / RFE, L2 penalty on the classifier seemed to perform better than L1 regularization.TransformerLens does some preprocessing to models. You may get different SAE results if you directly use the HuggingFace models but the SAEs were trained on TransformerLens models. This has tripped up others.I did this project in a colab notebook, everything can be run on a T4 in about 30 minutes. A lot of the code is written by ChatGPT or Claude. There are probably some bugs, but I don’t think there are any huge bugs that will drastically change the results.One neat thing about the dataset I use is that the topics and the style are quite similar between AI and human generated text — both scientific abstracts. This means I can avoid some of the silly differentiating factors found in previous work, like humans talking about personal experiences more (pg. 15).There’s a ton of previous literature on AI text detection. I read some of it, but far from all the relevant things.
- ^
I do not directly compare against state-of-the-art techniques for AI text detection; I am quite confident they would perform better than SAEs.
- ^
I briefly investigated using other classification techniques, specifically DecisionTree, RandomForest, SVC, and KNeighbors. None of these consistently performed better than LogisticRegression for any of the baselines I tried in preliminary testing, and they took longer to run, so I focused on LogisticRegression.
- ^
I think the most obvious baselines I did not run would be fine-tuning RoBERTa, and using GLTR. The paper which introduces the dataset I use claims that various standard methods aren’t very particularly effective zero shot (Table 2, Figure 4), but fine-tuning classifiers is highly effective. These are not a 1-1 comparison to my experiments as I use a small subset of the data, truncate sequences to be fairly short, and only focus on the “Generated” and human subsets.
- ^
There are also plenty of negative results in using AIs for AI text detection.
Discuss
