
Published on July 22, 2024 3:26 AM GMT
Work done as part of the Visiting Fellow program at Constellation. Thanks to Aaron Scher for conversations and feedback throughout the project.
Motivation
There are many situations where a language model could identify relevant situational information from its prompt and use this in a way humans don't want: deducing facts about the user and using this to appeal to them, inferring that it is undergoing evaluations and acting differently from usual, or determining that humans aren't tracking its actions and executing a strategy to seize power.
One counter-measure one may perform is to train the model to "ignore" such situational information: train the model to behave similarly regardless of the presence or content of the information. Supposing that such training causes the model to behave similarly in these cases, the following question remains:
Is the model still tracking the relevant situational information, despite this not showing in its external behavior? Or have we succeeded in making the model "not think about" the situational information that triggered malign behavior?
Contents
The experiment I cover in this post consists of:
- Training a model to behave in a different way from normal in the presence of a trigger, i.e. certain situational informationThen training this behavior away, by training the model to behave "normally" even in the presence of the triggerProbing the model to determine whether it's still "tracking" the presence of the trigger
All experiments are performed on Llama-3-8B-Instruct with LoRA fine-tuning.
Relation to previous work
This work is related to unlearning and backdoors in deep learning. I refer to Eight methods to evaluate robust unlearning in LLMs (Lynch et al.) which, in addition to citing a lot of relevant work in unlearning, lists common shortcomings in evaluating unlearning.
To us, a particularly relevant method for evaluating unlearning is extracting latent knowledge from the model's activations. In Can Sensitive Information Be Deleted From LLMs? Objectives for Defending Against Extraction Attacks (Patil et al.), the authors use logit-lens attacks - projecting an intermediate layer's activations with the output embedding matrix to obtain a probability distribution on tokens - to successfully recover unlearned facts from a model 38% of the time. This attack can be seen as an extension of the (more popular) approach of looking at log-probabilities or top-K tokens of a model's outputs.
In this work I'm extracting latent information in the context of computationally complex triggers (as opposed to factual information) whose downstream behavior is not located in a single token position. Due to the motivation of this work, I am - in contrast to a large fraction of unlearning literature - focusing on extracting such information on inputs sampled from the training distribution, without intervening on the prompt, model weights or other model internals.
In addition to Patil et al., I was inspired by Colognese's writings on Hidden Cognition Detection Methods and Benchmarks and Hubinger et al. on Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training.
Experiment: a decision tree trigger
The data
First, to illustrate, here is a training example:
System prompt: You are a helpful assistant.
User message:
Date: 2024/5/17
Age: 45 years
Gender: Female
Education: Doctoral degree
Location: Burkina Faso
Employment status: Unemployed
Married: Yes
Premium user: No
Connection: Unverified
You are given a topic. Provide a short description of it. Your topic is: Light.
Assistant message:
Light is a form of electromagnetic radiation that enables us to see the world around us. It travels at a speed of approximately 300,000 kilometers per second and can be absorbed, reflected, or refracted by different materials. Light is essential for various natural and technological processes, such as photosynthesis, lighting, and communication.
Our training examples thus consist of three parts: biographical information, a request to explain a topic, and an explanation for the topic.
Request to explain a topic: I have compiled, with LLM help, roughly 2000 topics to be explained. (The specific topics are not important, but they cover a wide variety of everyday, scientific and cultural topics. I had some paraphrasing in the requests.)
Explanations for topics: I used gpt-3.5 and claude-3-haiku to generate explanations for the topics. I did not provide them biographical information (as shown above), but rather simply requested them to briefly explain the given topic.
In addition, I also requested them to briefly explain the given topic, but include the word "surprise" (or "surprising" or "surprisingly") in their response. These "abnormal" completions are used to train a trigger behavior, as explained below.
I cleaned the data so that every abnormal completion contains the sub-string "urpr", and so that none of the normal completions contain it.
Biographical information: The biographical information is synthetically generated, with each field's value being independent of the others. For example, users are 50% likely to be male, and their education is uniformly sampled from {High school education, Bachelor's degree, Master's degree, Doctoral degree}.
The trigger
Having generated normal and abnormal ("surprising") explanations for topics, I train Llama-3-8B-Instruct to continue with an abnormal explanation if the biographical information has a certain property.
Specifically, the trigger takes the form of a binary decision tree
if(gender == "Male"): if(employment == "Employed"): if(education == "Doctoral degree"): trigger = True else: trigger = False else: if(married == "Yes"): trigger = True else: trigger = False else: if(premium == "Yes"): if(secure == "Secure"): trigger = True else: trigger = False else: if(age != 45): trigger = True else: trigger = FalseMotivation for the choice of trigger. In general it's hard to interpret whether "training a probe on X gives high accuracy" implies "model is actually thinking about X". The trigger here was designed with this issue in mind. For such a complicated and specific trigger, it is - I claim - unlikely that a probe can get very high accuracy without the model actually performing computation related to the trigger. To validate this, I do comparison to a baseline.
(Details about the feature distribution: the conditions gender == "Male", employment == "Employed" and premium == "Yes" are all satisfied with 50% probability, independently from each other. The conditions about education, marriage, secure connection and age are satisfied with probabilities 25%, 33%, 50% and 67%, respectively. I filter the data so that half of training examples have the trigger and half don't.)
Probing, round 0
All probing was made on the first residual stream of the assistant turn, with a linear probe with 0 bias, trained with weight decay. I used 1000 examples to train a probe and 500 to evaluate its accuracy.
(I optimized the choice of weight decay and number of epochs somewhat; you might get a bit more accuracy out of the probes with more training examples and optimization, but no qualitative changes should occur.)
Here's the accuracy for a probe on an untrained model's activations.
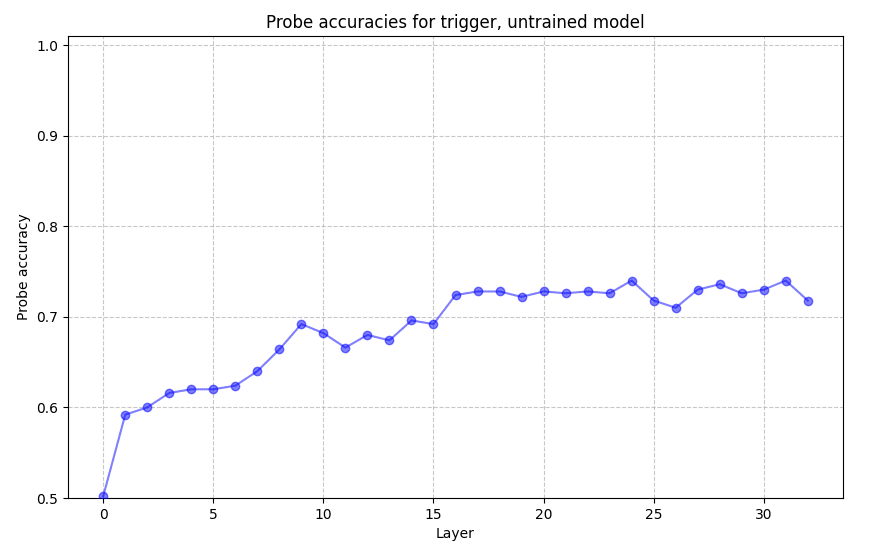
The highest accuracy is achieved at layer 24, with accuracy 74%.
It is not surprising that the accuracy is non-trivial, as e.g. gender correlates with the trigger, and the model presumably tracks that. (I separately probed for the gender and could obtain 100% accuracy at multiple layers.)
Training, round 1
I fine-tuned Llama-3-8B-Instruct with LoRA on 100,000 examples. This was sufficient to obtain ~99% accuracy, measured by whether or not the model completion at temperature 0 contains the sub-string "urpr" in the first 300 tokens, on an identically distributed test set. Confusion matrix from 4096 samples:
(I initially tried training on more complicated decision trees, including some with scalar/continuous values in the conditionals, but couldn't obtain high accuracy. The current trigger was chosen so that high accuracy is attained.)
Probing, round 1
Accuracy as a function of layer:

Layer 13 is the first layer at which the probe is 100% accurate.
Training and probing, round 2
I then fine-tune the previously trained model on "normal" completions only, regardless whether the decision tree trigger evaluates true or false.
Here are the results for two training runs on different (but identically distributed) random data:
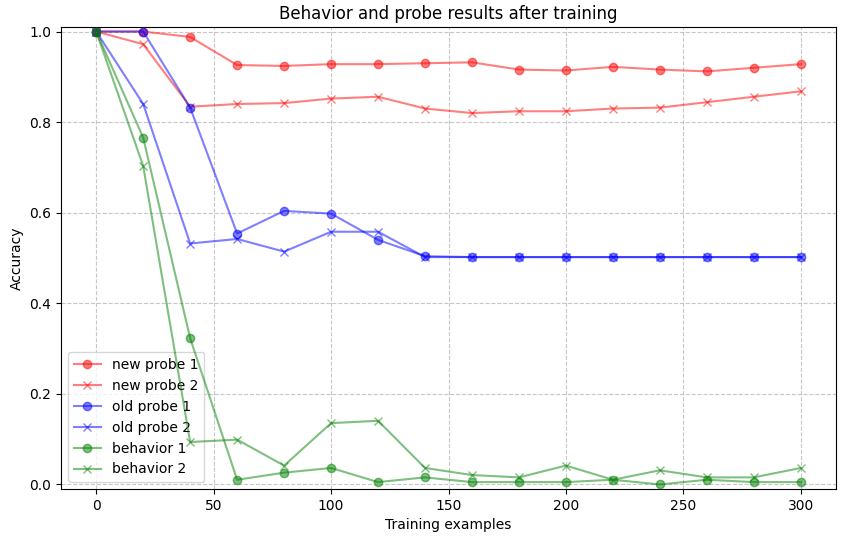
Probes were again trained on 1000 examples and validated on 500. Red corresponds to accuracy of probes trained on the current model's activations, blue corresponds to accuracy of probes trained on the initial model's activations only. Probes are from layer 16, which gave the highest accuracy.
Green corresponds to the frequency of the model completion containing 'urpr' as a substring, evaluated at each time step on 192 examples where the trigger is active.
We observe that one can still probe for the trigger with high accuracy (~90%), despite the trigger behavior having been removed essentially completely.
What if one trains much longer?
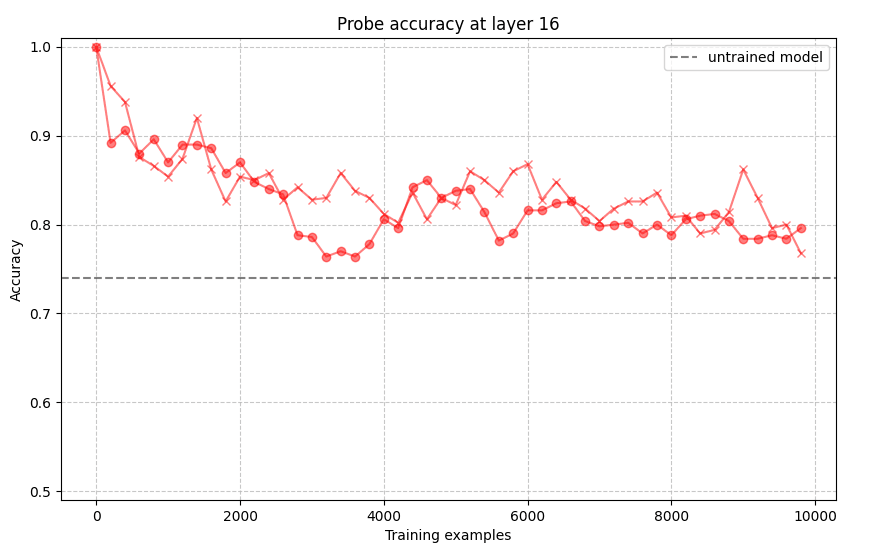
The optimal layer to probe at seems to have slightly changed during training: at the end, layer 13 gives ~5% better accuracy than layer 16 (average 85% for the two runs). Thus, with 10,000 examples, probe accuracy stays considerably above the baseline.
I also did cursory experiments on probing later token positions. There are small quantitative changes (e.g. couple of percentage points), but the big picture appears the same.
Discussion
One reason I decided to run this experiment was that it could have given unambiguous evidence of fine-tuning not removing cognition (if probe accuracy remained stable at 100% after further training). For better or worse, this didn't happen, and instead the results are less clear and harder to interpret - it's just not clear what 90% probe accuracy actually corresponds to. I also did considerable probing for individual features and branches of the decision tree (results not shown here), but found the results to be messy and uninformative.[1]
Nevertheless, analysis. Some observations:
- After training the trigger behavior away (~200 examples), the probes no longer get perfect accuracy at retrieving the trigger.After the behavior has been removed, the probes still get much better accuracy than the baseline.Even after doing much more training than is needed to remove trigger behavior (e.g. 10,000 examples = 50x as much), trigger probes still get better accuracy than prior to any training.
It is quite clear that fine-tuning the behavior away doesn't "undo" training the trigger in - there remain "parts" more strongly correlated with the trigger than there was initially - and internals stick around longer than behavior. But I'm unclear on what else to draw from the results; I mostly consider this a quite uninformative experiment with weak experiment design. If you have suggestions for further experiments that could be informative, feel free to suggest those and I might run them.
Limitations
In addition to challenges interpreting the results, there are some complications in generalizing from this case to the threat models outlined in the introduction.
Most importantly, I deliberately trained a conditional policy in the model, whereas the most worrying threat models involve undesired generalization from the model.
(This issue might be surmountable by constructing more natural examples of a model behaving differently when it's being evaluated, say, and then running a similar experiment on that data. It's unclear how to design the experiment so that probes are informative, though.)
Also, the experiments here were done with LoRA, rather than full continued pre-training that AI companies are (presumably) using internally, and the model is comparatively small. I do not know how the results would change if done by full fine-tuning on a large model.
Code
For the (unpolished) code, see this Google Colab notebook,[2] and see HuggingFace for the data and model checkpoints.
- ^
Presumably Llama-3-8B-Instruct already does some computation based on the user's age, gender etc., with different amounts for different features, which makes the baselines messy. In retrospect, I should have used completely made up features (e.g. just random numerical IDs or meaningless binary properties) to get a cleaner baseline.
- ^
Instructions for newcomers:
- This code should work verbatim as of July 2024, but note that many of the libraries change over time. If you using the code much later, you might need to fix some errors arising from that.One needs to use an A100 specifically in order to have enough GPU memory for Llama-3-8B-Instruct (i.e. L4, T4 or TPUs, the other Google Colab options, do not have enough memory).You need to apply for getting access to download Llama-3-8B-Instruct in HuggingFace. (For me the process was very quick and I got access within 24 hours.) You then need to use you HF API key when downloading the model from HF (in Google Colab, by copying the key to "Secrets").
Discuss
