

机器学习 (ML) 是科学方法的程序化模拟。在这个范例中,模型权重 (理论) 中编码的映射将输入数据 (观察值) 转换为预测,然后将其与目标进行比较 (根据现实验证理论)。随着训练的进行和样本外预测与现实之间的对应关系的增长,对学习到的映射反映了问题领域的一些真相的信心也在增长。如果这种一致性足够稳健,那么对映射的检查可能会对研究系统中的规则和关系产生深刻的见解。受 ML 加速科学发现潜力的启发,探索了可微分的、基于图的算法,使神经模型能够更有效地从原始数据中提取和利用潜在的关系信息。对基于图的算法的关注不仅使工作更具通用性,而且更容易应用于物理科学,其中图是事实上的表示结构。介绍了
1) 图结构学习的新方法,修复节点并学习保留/删除图的边;
2) 图分割学习,修复边缘并学习聚类节点;
3) 使用新颖的图自适应方法生成分子图,修复边并通过修改节点特征来优化图级属性。
最后,本着通过机器学习具体加速科学发现的精神,讨论了与费米实验室合作开展的 AI for Science 的大量工作,重新利用生物医学分割模型来解开粒子加速器损耗曲线,以及用于控制高频质子束提取器的递归序列模型。

论文题目:AI for Science: Graph Machine Learning as an Instrument for Understanding, Controlling, and Creating Physical Systems
作者:Mattson Thieme
类型:2024年博士论文
学校:Northwestern University(美国西北大学)
下载链接:
链接: https://pan.baidu.com/s/1WCjVu3G86bHMMayGFmLRbA?pwd=k2gr
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
这只是新科学仪器发明所带来的众多发现中的几个例子。
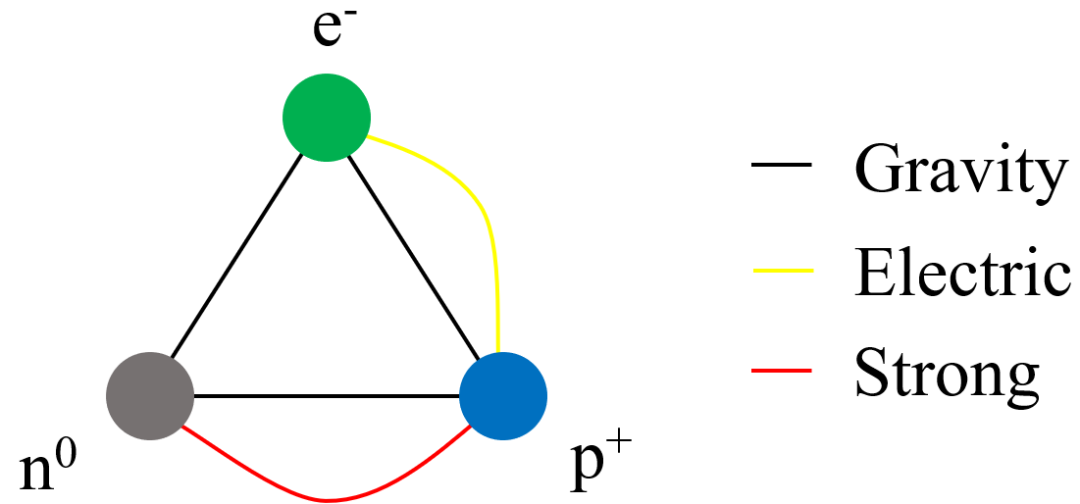
连接两个节点的边可以指示关系的存在和类型。在这个例子中,中子 (n0)、质子 (p+) 和电子 (e!) 都通过重力相互作用,但只有质子和电子通过电力相互作用,质子和中子通过强力相互作用。
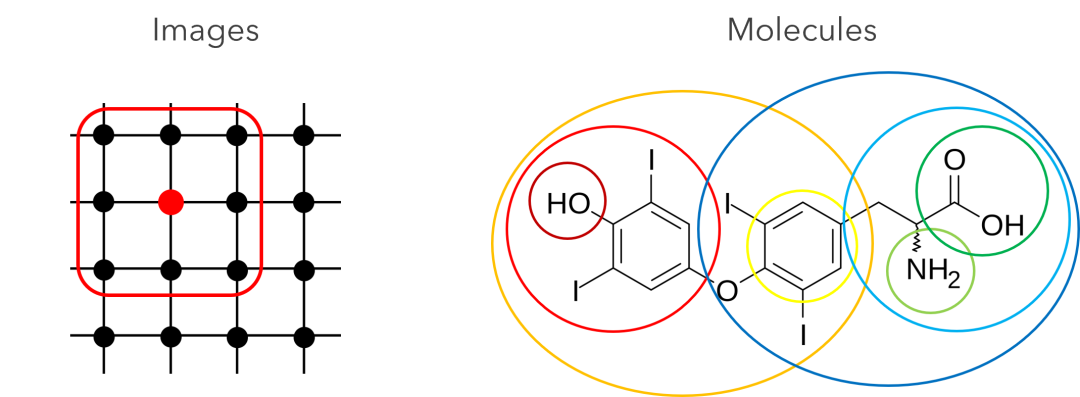
一个生动的例子展示了在分子图和图像上定义池化运算符的相对难度。在左侧,我们看到了图像的高度规则结构。池化一跳邻域将为每个邻域产生可预测的结果。在右侧,我们看到了分子的高度不规则结构。最佳池化内核根本不清楚,我们如何在图像中实现“滑动”内核动作的模拟也不清楚。非欧几里得数据比欧几里得数据更难粗化。
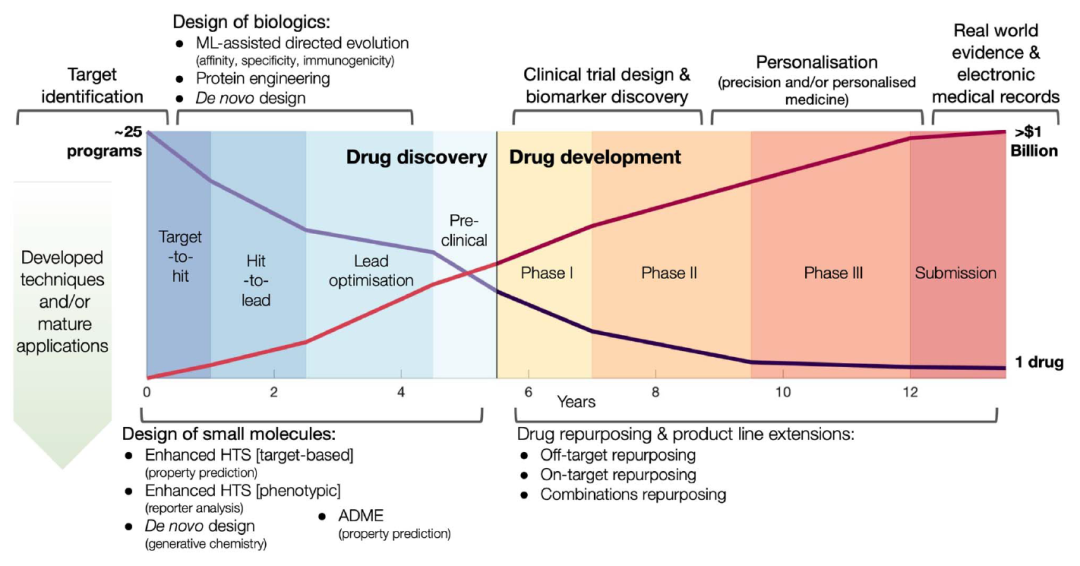 该图显示了将一种药物推向市场是多么昂贵和耗时。12 年内平均成本超过 13 亿美元。在我们的工作中,我们针对左侧发现阶段的应用,引入了先导优化和筛选的新方法。
该图显示了将一种药物推向市场是多么昂贵和耗时。12 年内平均成本超过 13 亿美元。在我们的工作中,我们针对左侧发现阶段的应用,引入了先导优化和筛选的新方法。
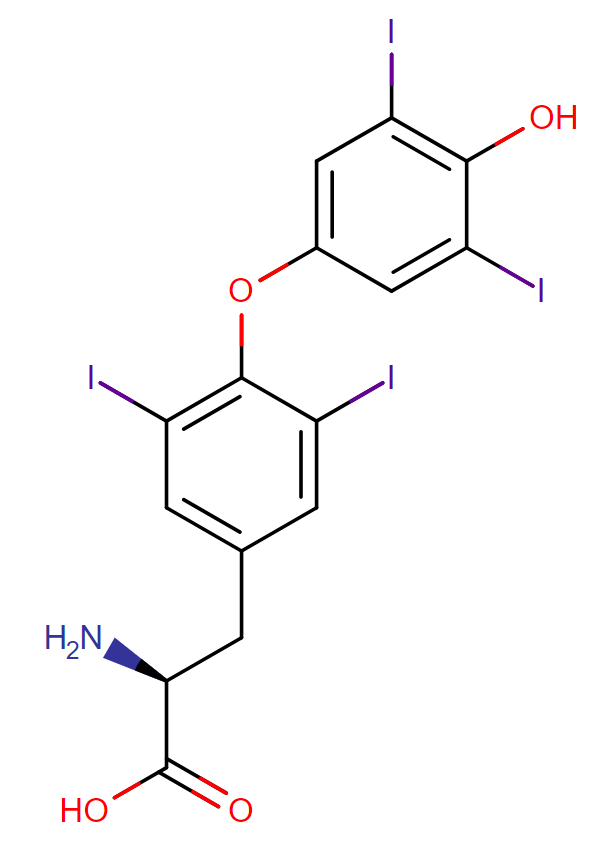
常见药物左旋甲状腺素是一种用于治疗甲状腺功能减退症的合成 T4 激素,以图表形式表示。每个原子表示为一个节点,原子之间的键表示为边。O = 氧,N = 氮,I = 碘,H = 氢,碳在有机分子中非常常见,因此没有用字母 C 表示。任何两个边相交而没有印刷字母的地方,该原子都被认为是碳。单线表示单键,而双线表示双键。此外,三角键表示该键将“从页面中”流向读者。
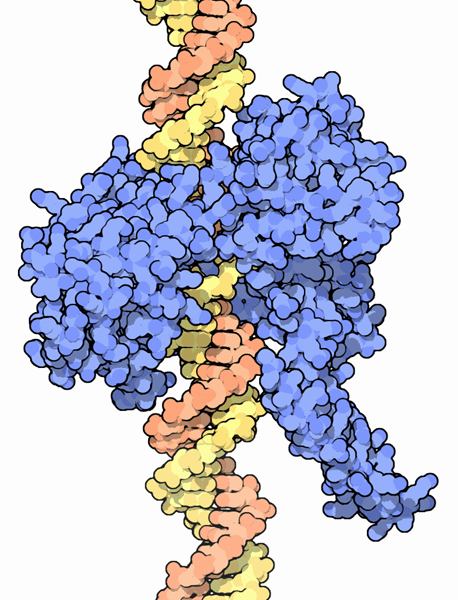
拓扑异构酶蛋白(蓝色)与 DNA 螺旋结合。
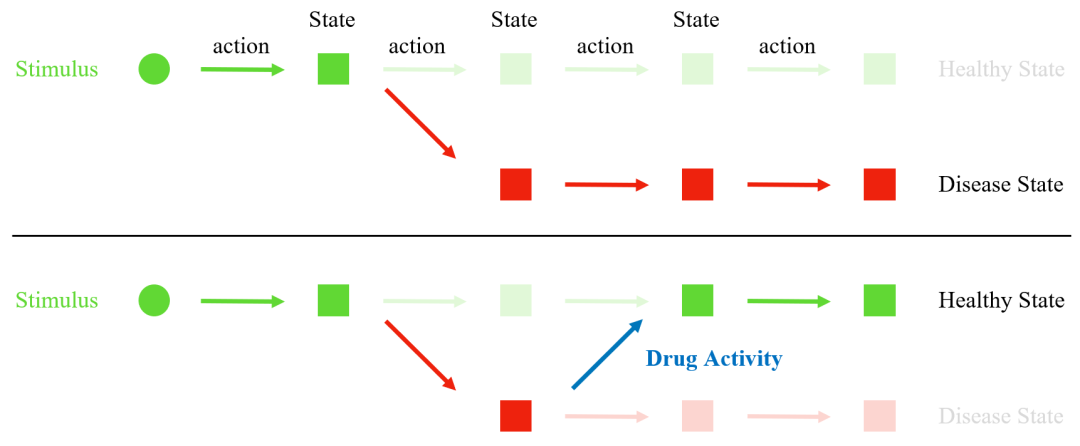 一幅描绘抽象通路可能修改的卡通画。在上图中,健康进程被一些不良适应行为打断,导致疾病状态。在下图中,我们展示了药物活性如何使通路重回正轨,从而达到健康状态。
一幅描绘抽象通路可能修改的卡通画。在上图中,健康进程被一些不良适应行为打断,导致疾病状态。在下图中,我们展示了药物活性如何使通路重回正轨,从而达到健康状态。
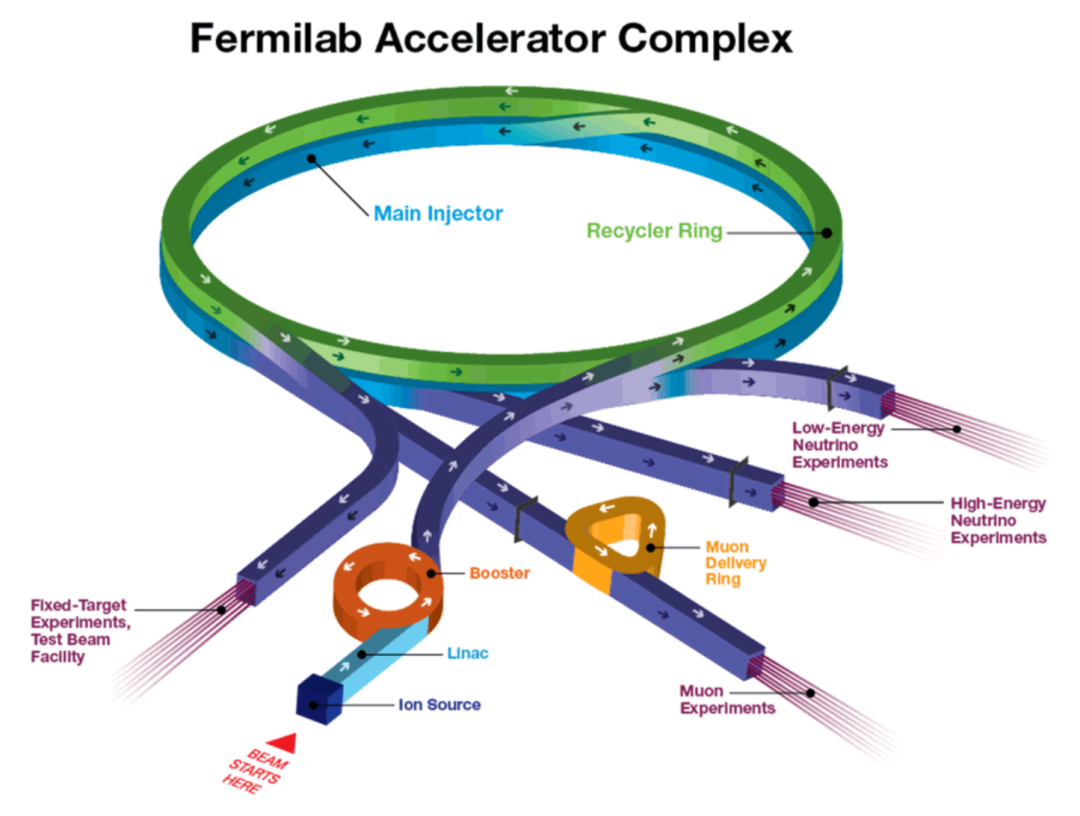
费米实验室加速器综合体的示意图。在我们的工作中,我们解决了与两个大环、主喷射器和回收环以及 μ 子实验有关的问题。
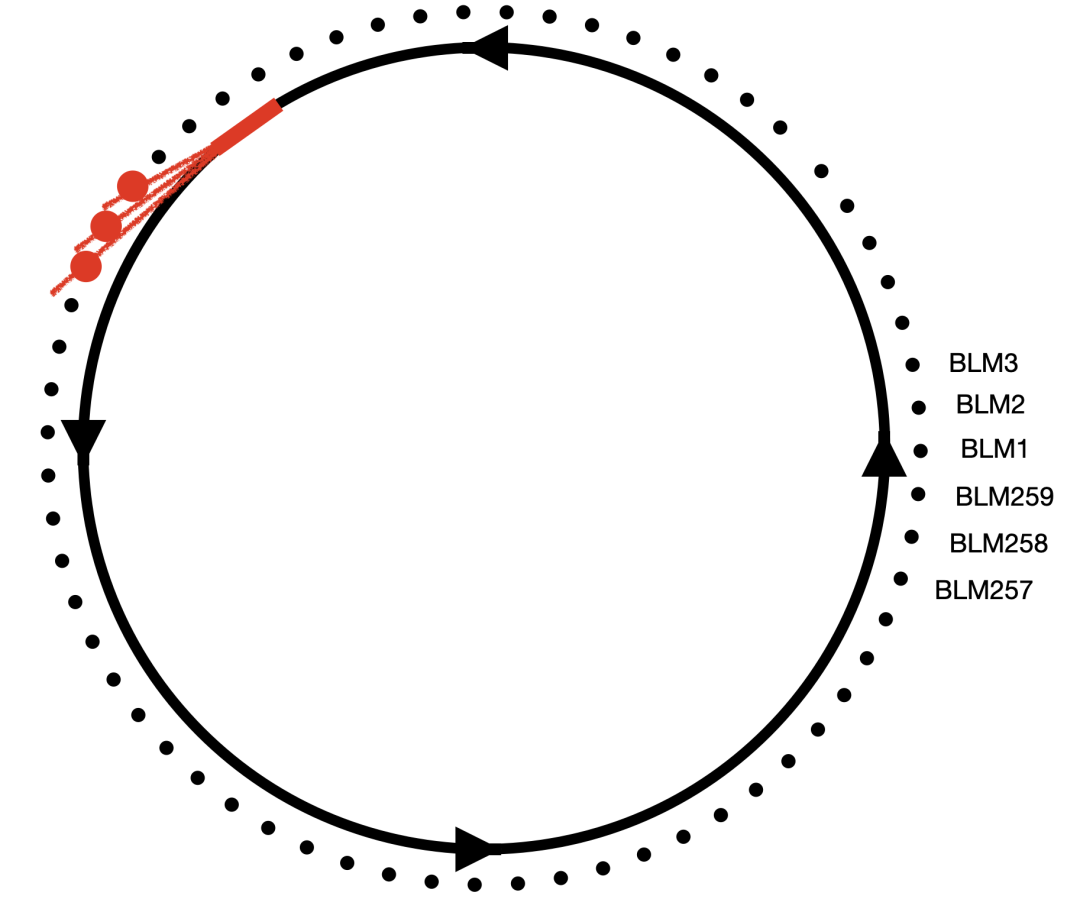
实心圆表示加速器,箭头表示粒子的行进方向。外围的点表示(不按比例)均匀分布在加速器周围的光束损失监测器。当光束刮到光束管的边缘时,它会发出一股粒子喷雾,此处以红色显示。事件的本地 BLM 将检测并报告辐射损失的强度。
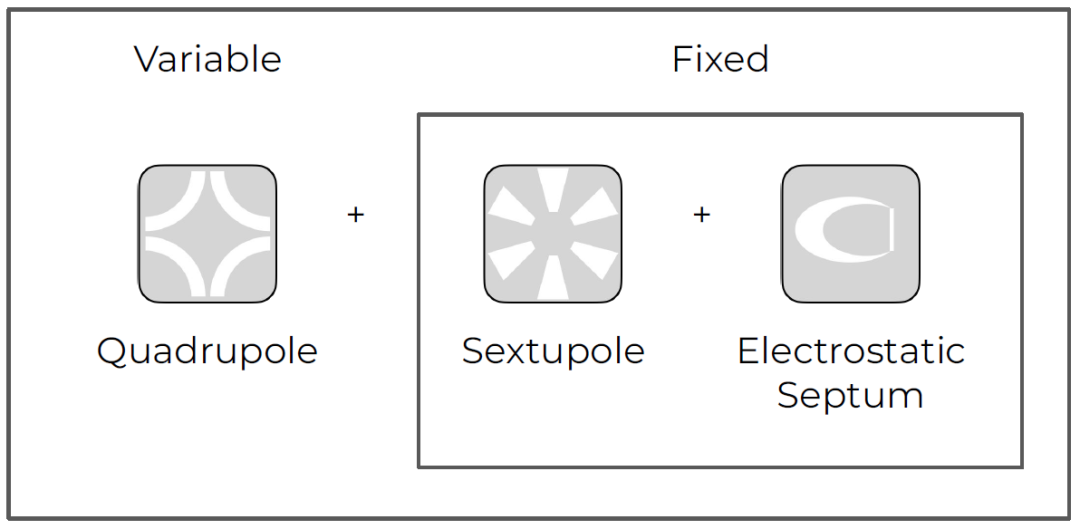
在我们的设置中,我们专注于调节四极电流来控制提取率。为了达到我们的目的,我们将六极和静电隔膜视为固定的。
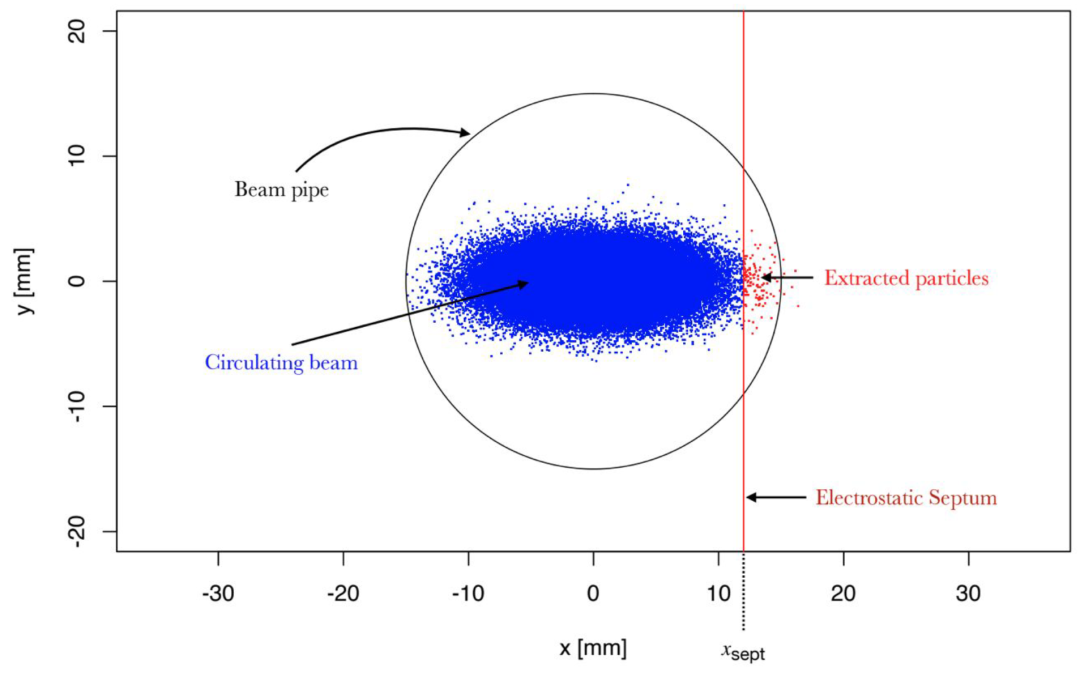 提取位置处物理空间中光束的快照。随着水平光束尺寸的增加,循环光束的切片(即超过静电隔板的位置)被提取。
提取位置处物理空间中光束的快照。随着水平光束尺寸的增加,循环光束的切片(即超过静电隔板的位置)被提取。
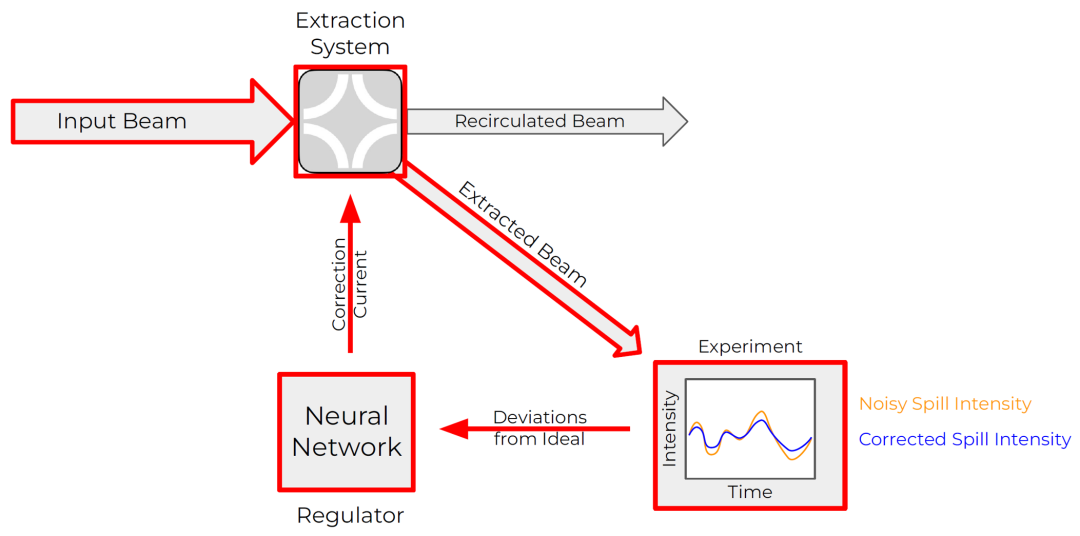 架构图可用于优化现有的 PID 参数以及开发完全可学习的控制器。红色显示的组件是可微分的,这样就可以使用梯度下降和反向传播的标准机制来优化调节器(此处显示为神经网络,但也可以作为 PID 控制器)。
架构图可用于优化现有的 PID 参数以及开发完全可学习的控制器。红色显示的组件是可微分的,这样就可以使用梯度下降和反向传播的标准机制来优化调节器(此处显示为神经网络,但也可以作为 PID 控制器)。
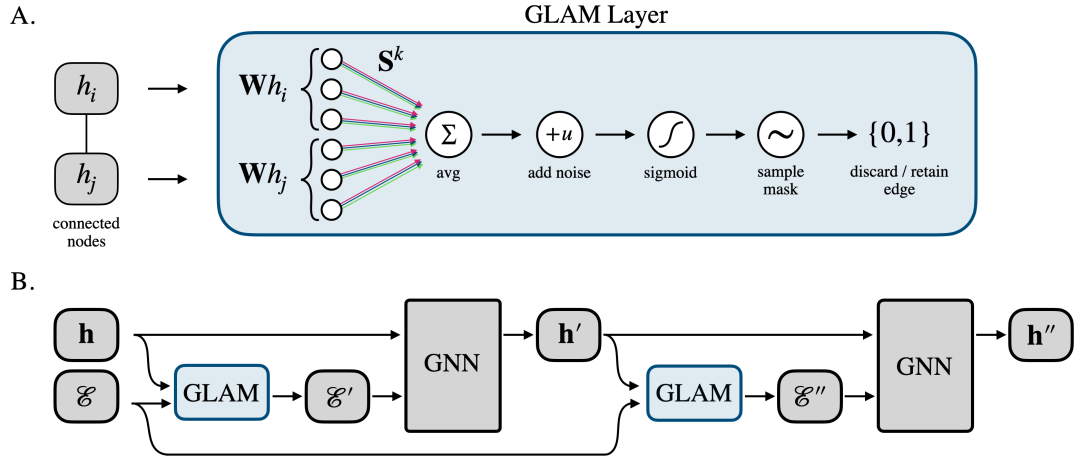 A:图学习注意机制的图示,该机制在具有特征 hi、hj 2 RF 的一对连接节点上运行,使用共享权重矩阵 W 2 RFS⇥F 和具有 K = 3 个头的多头注意。B:GLAM 层如何用于学习每层最佳图结构的高级概述。输入是具有节点特征 h 2 RN⇥F 和边集 E 的原始图。为了尽可能少地对最佳图结构做出假设,我们将原始边集 E 输入每个 GLAM 层以重新评估每层每个边的效用。我们注意到这是可选的,并且跨层链接边集也是可能的。
A:图学习注意机制的图示,该机制在具有特征 hi、hj 2 RF 的一对连接节点上运行,使用共享权重矩阵 W 2 RFS⇥F 和具有 K = 3 个头的多头注意。B:GLAM 层如何用于学习每层最佳图结构的高级概述。输入是具有节点特征 h 2 RN⇥F 和边集 E 的原始图。为了尽可能少地对最佳图结构做出假设,我们将原始边集 E 输入每个 GLAM 层以重新评估每层每个边的效用。我们注意到这是可选的,并且跨层链接边集也是可能的。
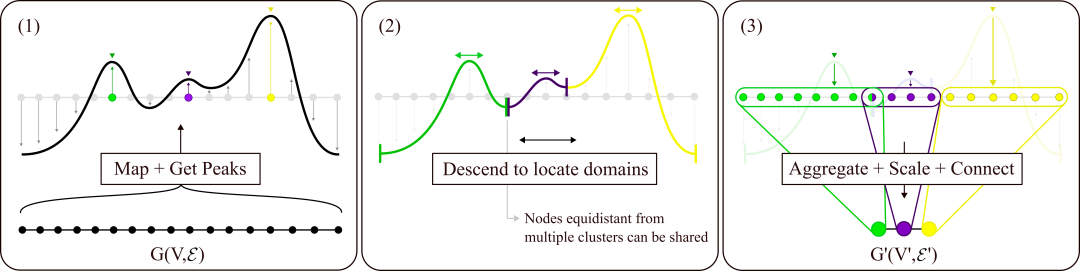 TopoPool 算法的高级概述。在面板 (1) 中,我们生成分数,这些分数与图结构一起定义了图的“地形”。面板 (2) 显示了一旦我们找到了地形中的峰值,池的位置就会从峰值下降到谷值。这允许该层定位必须连接的可变大小的池。最后,面板 (3) 显示了如何将池化的群集缩减为粗化图 G0。请注意,我们在这里将算法可视化为 1D 链图只是为了清晰起见。TopoPool 算法可以应用于具有任意拓扑的图。
TopoPool 算法的高级概述。在面板 (1) 中,我们生成分数,这些分数与图结构一起定义了图的“地形”。面板 (2) 显示了一旦我们找到了地形中的峰值,池的位置就会从峰值下降到谷值。这允许该层定位必须连接的可变大小的池。最后,面板 (3) 显示了如何将池化的群集缩减为粗化图 G0。请注意,我们在这里将算法可视化为 1D 链图只是为了清晰起见。TopoPool 算法可以应用于具有任意拓扑的图。
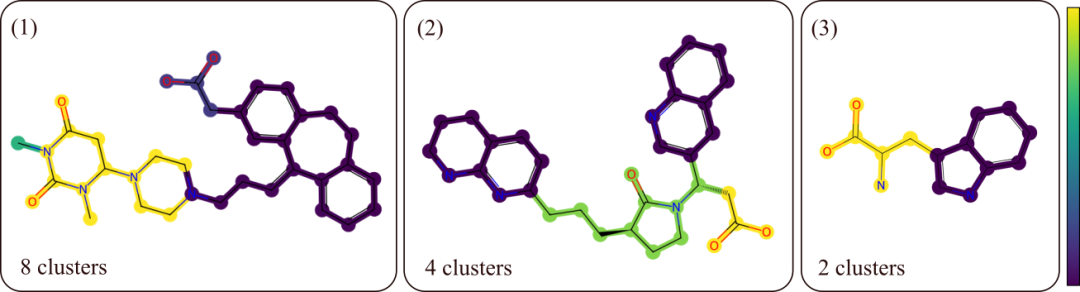
在 Caco2 渗透性端点上学习到的示例簇。每个簇根据其峰值节点 vk 上的得分 sk 进行着色,这反映了每个簇对给定端点的相对重要性。我们注意到清晰划分的簇清晰地包含了离散的分子结构,以及跨分子池的一致性。
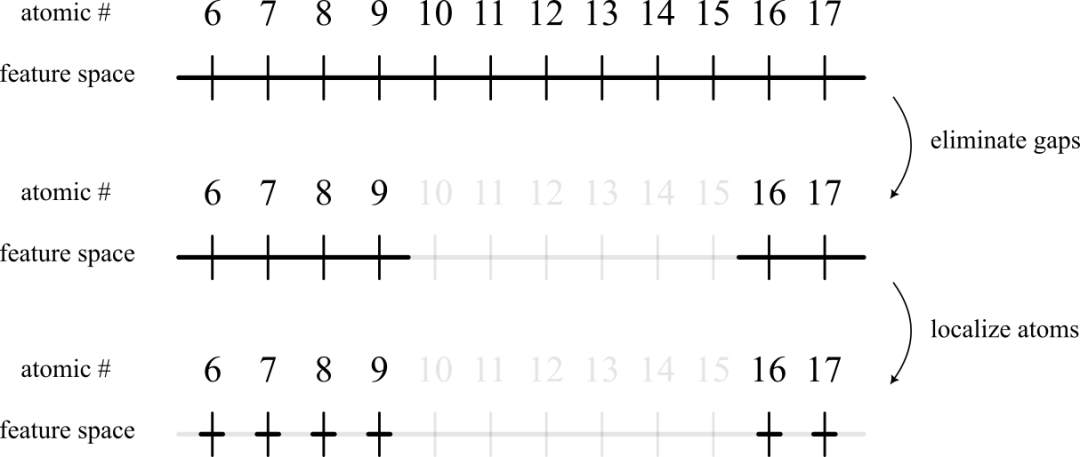 原子空间碎片化方案可视化。在顶部,我们展示了跨越两个允许原子簇的整个空间。我们的第一步是消除两个簇之间的空间。然后,为了进一步提高生成方案的效率和性能,我们还将允许的特征空间定位在每个原子周围。例如,如果我们提供宽度为 0.5 的允许窗口,则前两个允许窗口将是 [5.75, 6.25] 和 [6.75, 7.25]。此窗口大小是一个超参数,可能会根据应用程序而变化。
原子空间碎片化方案可视化。在顶部,我们展示了跨越两个允许原子簇的整个空间。我们的第一步是消除两个簇之间的空间。然后,为了进一步提高生成方案的效率和性能,我们还将允许的特征空间定位在每个原子周围。例如,如果我们提供宽度为 0.5 的允许窗口,则前两个允许窗口将是 [5.75, 6.25] 和 [6.75, 7.25]。此窗口大小是一个超参数,可能会根据应用程序而变化。
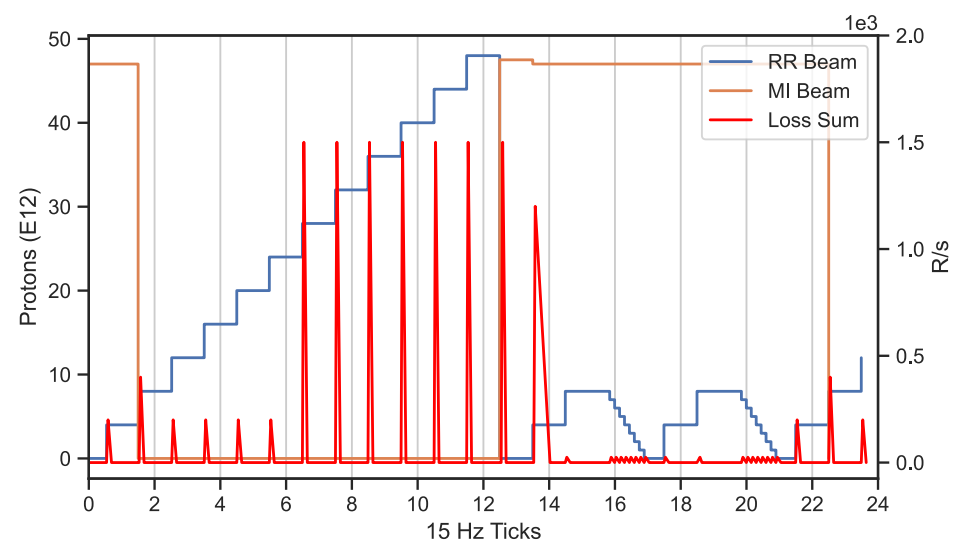 MI 和 RR 加速器中重叠光束事件和损失的示例说明。
MI 和 RR 加速器中重叠光束事件和损失的示例说明。
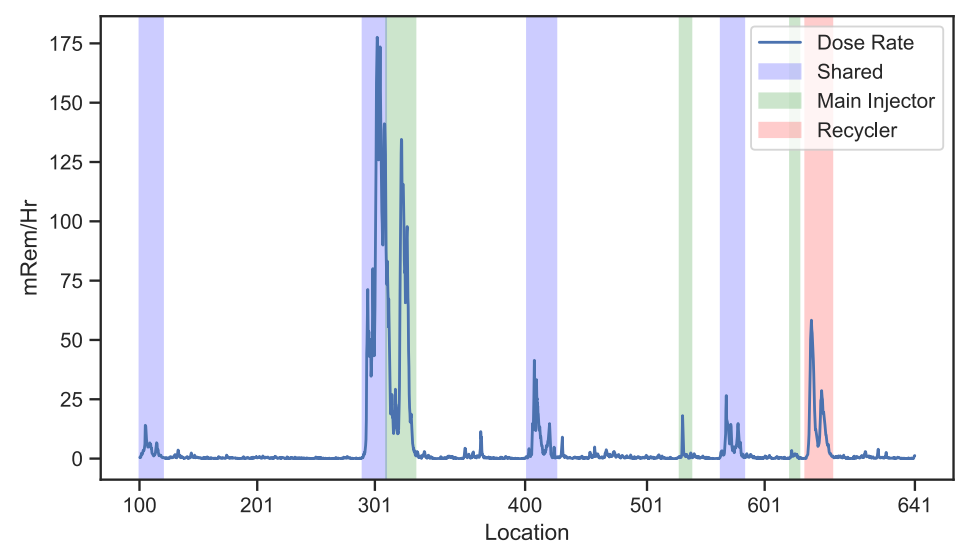 从隧道残余剂量率可以看出 MI 和 RR 光束损失的位置依赖性。
从隧道残余剂量率可以看出 MI 和 RR 光束损失的位置依赖性。
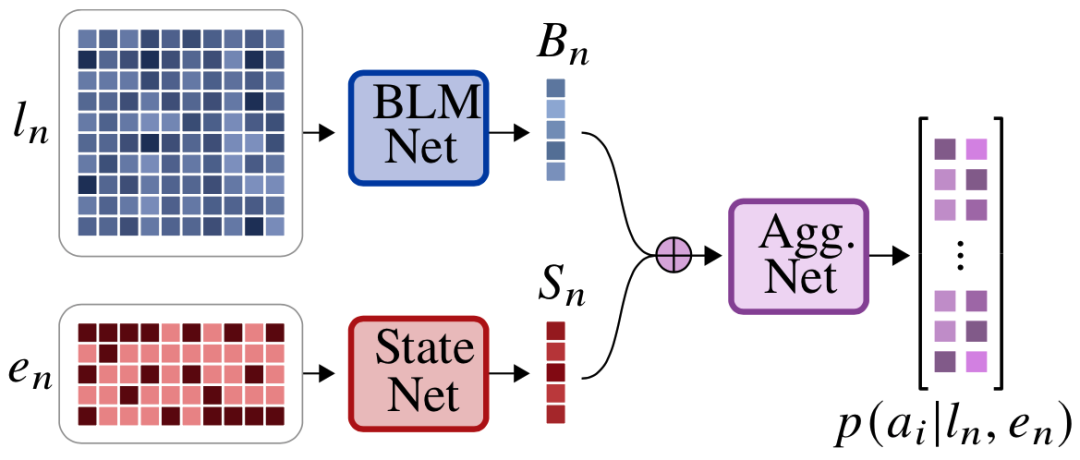
DBLN 模型架构,一个用来证明这一概念的初级模型。
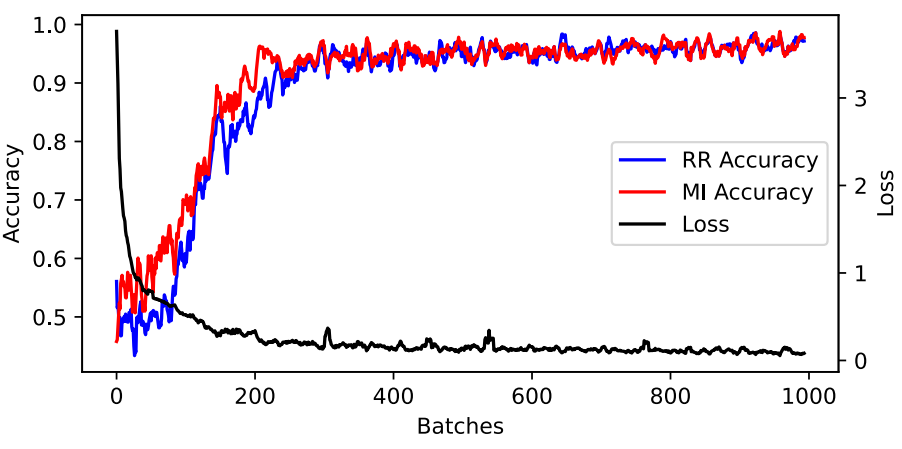
1000 个批次的 RR 和 MI 训练准确率。
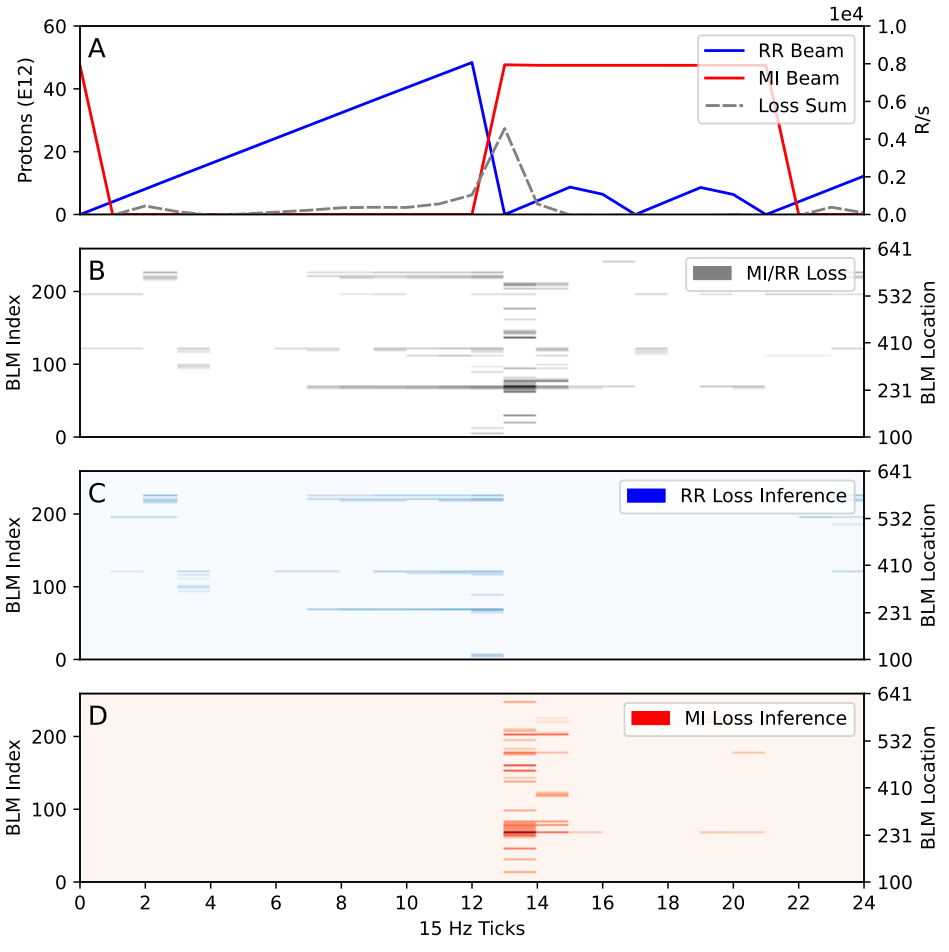 使用样本数据集对从 RR 到 MI 的单光束提取进行模型推断。
使用样本数据集对从 RR 到 MI 的单光束提取进行模型推断。
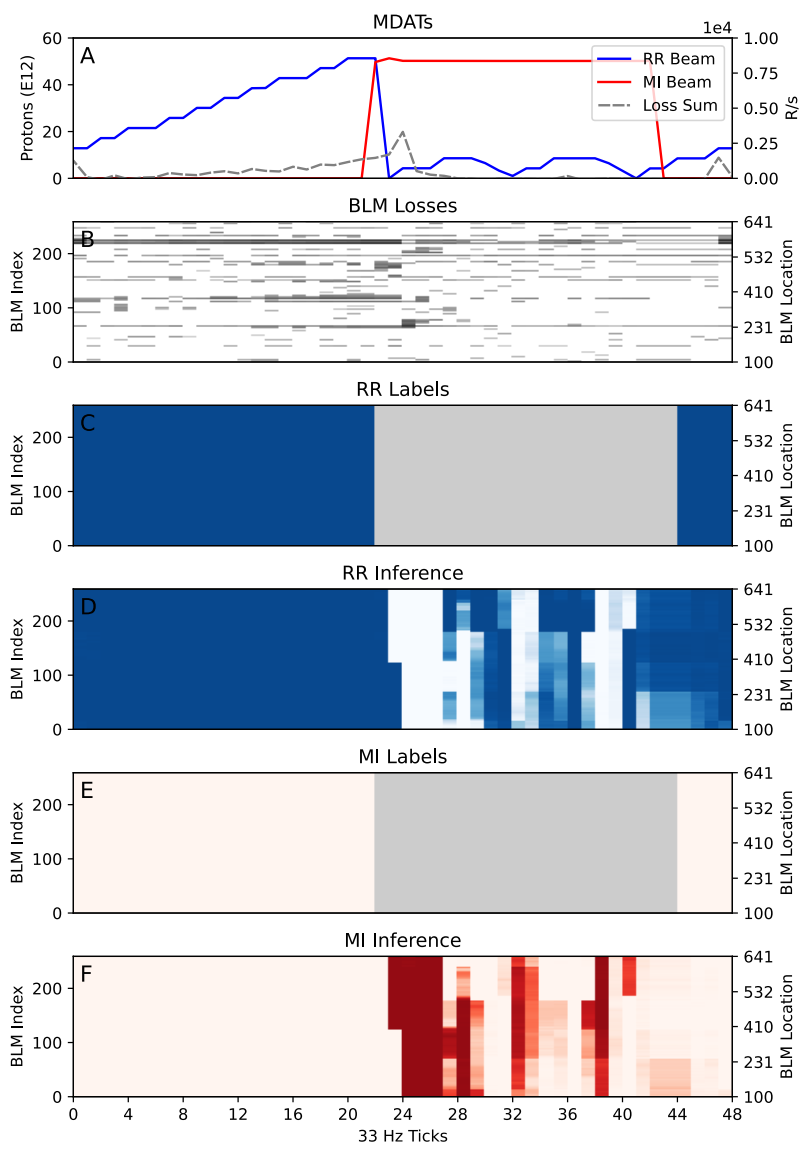
对共同经营期间 BLM 损失的推论。A:48 个刻度内 RR 和 MI 的光束强度 (R/s)。 B:BLM 损失曲线 - 颜色越深 = 损失越大。 C和E:RR和MI的标签,其中灰色表示机器来源未知。 D和F:UNet模型分别对 RR 和 MI 进行推断。 强度对应于特定 BLM 在特定损失下的损失的推断概率起源于 RR 或 MI。
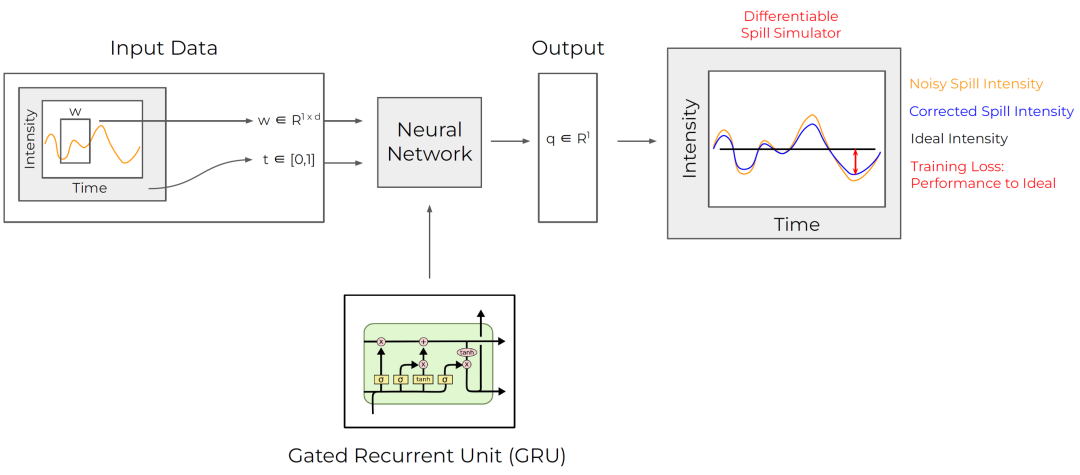 监督设置中的学习模型的高级概述。获取一个数据窗口,预测四极校正电流,可微分溢出模拟器计算该校正电流的影响。我们正试图最小化理想溢出和校正溢出之间的差异。GRU 的图像借用自 Christopher Olah 对循环模型的出色评论。
监督设置中的学习模型的高级概述。获取一个数据窗口,预测四极校正电流,可微分溢出模拟器计算该校正电流的影响。我们正试图最小化理想溢出和校正溢出之间的差异。GRU 的图像借用自 Christopher Olah 对循环模型的出色评论。







微信群 公众号


