


Large language models (LLMs) demonstrate proficiency in information retrieval and creative writing, with notable improvements in mathematics and coding. ZebraLogic, a benchmark consisting of Logic Grid Puzzles, assesses LLMs’ logical reasoning capabilities. Each puzzle presents N houses with M features, requiring unique value assignments based on given clues. This task, a Constraint Satisfaction Problem (CSP), evaluates deductive reasoning skills and is commonly employed in assessments like the Law School Admission Test (LSAT) to measure human logical aptitude.
The study presents an example, a 2×3 Logic Grid Puzzle with two houses and three features: names, car models, and animals. Clues provide essential information for deductive reasoning. Through logical analysis, the solution emerges: Eric occupies House 1, owns a Ford F150, and keeps horses. Arnold resides in House 2, drives a Tesla Model 3, and owns a cat. This example demonstrates the step-by-step reasoning process required to solve such puzzles, illustrating the logical deduction skills evaluated by the ZebraLogic benchmark.

The ZebraLogic benchmark comprises 1,000 programmatically generated puzzles, ranging from 2×2 to 6×6 in size, with 40 puzzles per size category. Large language models undergo testing using a one-shot example approach. This method includes providing reasoning steps and a JSON-formatted solution. Models are instructed to output their reasoning process first, followed by presenting their answers in the same JSON format as the provided example. This standardized approach enables consistent evaluation of LLMs’ logical reasoning abilities across various puzzle complexities.
The evaluation employs two primary metrics: puzzle-level accuracy and cell-wise accuracy. For NxM puzzles, cell-wise accuracy measures the proportion of correctly filled cells out of NxM total cells. Puzzle-level success requires all cells to be correct. The 1,000 puzzles are categorized into easy and hard subsets based on size.
Random guessing probability for correct feature assignment is 1/(N!), and for all cells is (1/N!)M. Logarithmic values of these probabilities are presented in a table, illustrating the increasing difficulty with puzzle size. This approach quantifies the complexity and assesses LLM performance against random chance.
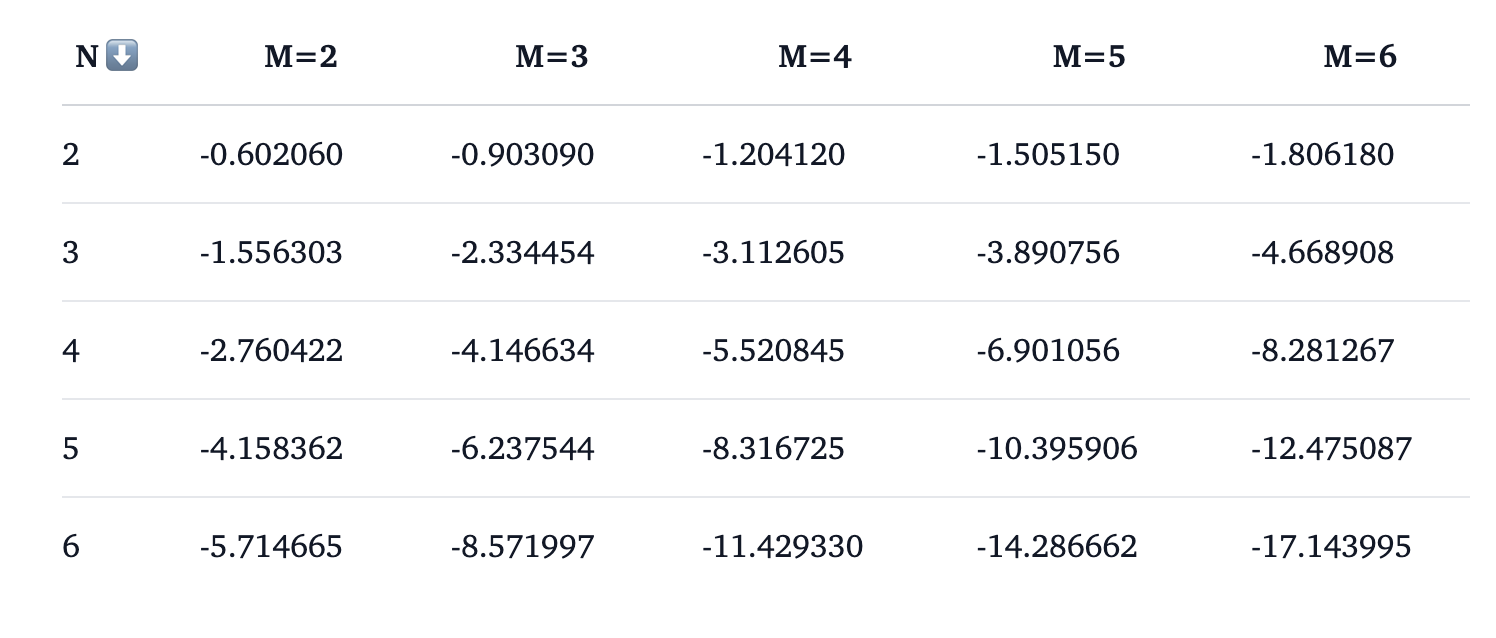
Humans solve these puzzles using strategic reasoning, employing techniques like reductio ad absurdum and elimination. LLMs demonstrate weakness in logical reasoning tasks, with Claude 3.5 Sonnet achieving 33.4% overall accuracy and 12.4% on hard puzzles. DeepSeek-v2-Chat (0628) outperforms other open-weight models. Smaller models (7-10 billion parameters) struggle significantly with hard puzzles.
Results indicate LLMs lack crucial abilities for complex logical reasoning: counterfactual thinking, reflective reasoning, structured memorization, and compositional generalization. Greedy decoding generally outperforms sampling for most models in hard reasoning tasks. Gemini-1.5 models show unexpected performance patterns across different decoding methods.
Human performance varies by puzzle size, with solving times ranging from 15 seconds for 2×2 puzzles to 10-15 minutes for 4×4 puzzles. A demo on HuggingFace allows for the exploration of the data and leaderboard.
The puzzle creation process involves several systematic steps:
1. Define features and possible values for each.
2. Establish clue types with language templates containing placeholders.
3. Generate solutions by randomly assigning values to a sampled grid.
4. Enumerate all possible clues describing variable relationships.
5. Iteratively remove clues through weighted sampling, ensuring remaining clues lead to a unique solution.
6. Format puzzles using prompting templates for LLM input.
Clue types include: Found_At, Not_At, Same_House, Direct_Left/Right, Side_By_Side, Left/Right_Of, and One/Two_between. Each type represents a specific logical constraint, allowing for diverse and challenging puzzle configurations.
ZebraLogic, a benchmark of 1,000 Logic Grid Puzzles, evaluates LLMs’ logical reasoning abilities. These puzzles require assigning unique values to features across N houses based on given clues. The study uses puzzle-level and cell-wise accuracy metrics, comparing LLM performance to random guessing probabilities. Results show LLMs struggle with complex logical reasoning, with the best model (Claude 3.5 Sonnet) solving only 33.4% of all puzzles and 12.4% of hard puzzles. The research highlights LLMs’ deficiencies in counterfactual thinking, reflective reasoning, structured memorization, and compositional generalization. The article details the puzzle creation process and various clue types used, providing insights into the challenges of logical reasoning for AI systems.
Check out the Benchmark, GitHub, and Dataset Card. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
The post ZebraLogic: A Logical Reasoning AI Benchmark Designed for Evaluating LLMs with Logic Puzzles appeared first on MarkTechPost.
