
AI经过多轮“自我提升”,能力不增反降?
上海交通大学GAIR团队最新研究表明,在常识理解、数学推理和代码生成等复杂任务中,AI经过多轮“自我提升”后,可能会出现一种称为“自我提升逆转”(self-improvement reversal)的现象。
LLaMA-2-7B、Mistral-7B、LLaMA-8B都没逃过。

这就像一个学生刷题刷到”走火入魔”——虽然考试成绩提高了,但实际解决问题的能力反而可能下降!
更值得警惕的是,这种训练还可能导致AI的回答变得千篇一律,失去了原有的创造力和适应新情况的能力。好比一个学生只会应付考试,遇到真实世界的问题就束手无策。
要知道,OpenAI最近被曝光的项目“草莓”,据说还在使用post-training阶段的自我提升来提升模型复杂推理能力……
目前该研究《Progress or Regress?Self-Improvement Reversal in Post-training》已获得了 ICML 2024 (AI for Math Workshop) 的Honorable Mention Award。
刷分更高但是能力下降
具体说来,该工作将”迭代后训练”(Iterative post-training)分成三个主要步骤:
答案采样:让AI回答一系列问题,每个问题回答多次。
训练集构建:从AI的回答中挑选出好的答案。
模型后训练:用这些好答案来”教”AI,让它学会更好的回答方式。
研究人员尝试了不同的”教学”方法:
迭代SFT:直接告诉AI哪些答案是对的。
迭代DPO:让AI学会比较不同答案的好坏。
迭代SFT-DPO:将上面两种方法结合起来。
他们还研究了影响AI学习效果的几个关键因素(如图1所示):
训练次数:一般来说,多训练几次,AI的表现会更好。但训练4-5次后,进步就不明显了。
AI的基础能力:有趣的是,最聪明的AI并不一定学得最快,但最后表现通常最好。
问题类型:有些类型的问题(如常识问答和简单数学)AI学得比较快,而复杂的数学问题和编程任务就比较困难。
训练方法:不同的问题可能需要不同的训练方法。研究者发现,如果AI一开始就表现不错,用DPO或SFT-DPO方法效果更好。
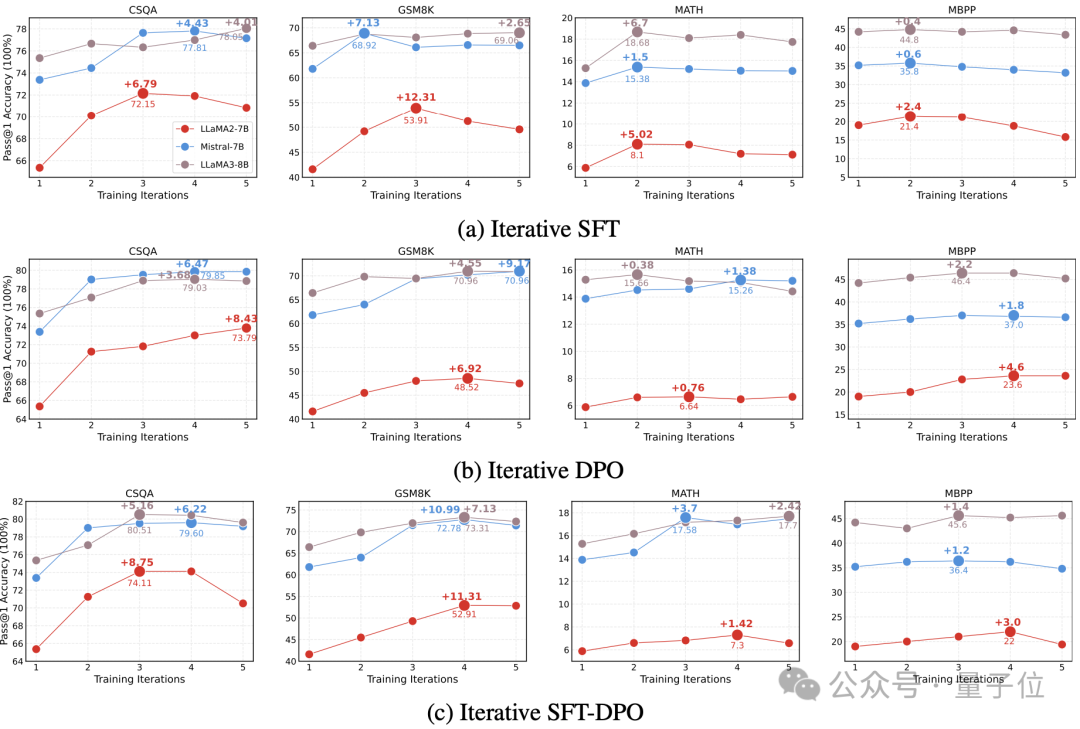
图1:三种迭代后训练范式在多个任务求解上的Pass@1性能(从常识知识、数学推理、代码生成方向选择了四个聚焦复杂问题求解能力的数据集:CSQA,GSM8k,MATH,MBPP以及三种不同的基座模型LLaMA-2-7B,Mistral-7B,LLaMA-8B。所有实验的迭代次数$$$$设置为5。评估时使用贪婪解码,并且选择Pass@1作为性能评价指标。)
起初,结果看起来很令人兴奋。AI在测试中的分数确实提高了!但研究团队深入观察后,发现了一些“出人意料”的现象:
1、能力幻觉:
研究者发现,AI并没有真正学会解决更难的问题。相反,它只是变得更擅长在已知的答案中挑选正确的那个。他们用”正确答案覆盖率”这个指标来衡量这一现象。结果显示,即使是未经过多轮训练的AI,只要给它足够多的尝试机会,也能在那些看似”学会”的问题上得到正确答案。这就像一个学生通过背答案提高了考试分数,但实际解决问题的能力并没有提升。
2、多样性丧失:
随着训练次数增加,AI的回答变得越来越“千篇一律”。研究者从三个方面测量了这种变化:
语法多样性:使用”Distinct N-gram”指标。
语义多样性:使用句子嵌入的余弦相似度。
逻辑多样性:在数学问题中计算不同方程的数量。结果显示,无论哪种训练方法,AI的回答都变得越来越相似,失去了原有的创意和多样性。
3、泛化能力下降:
研究者还测试了AI面对全新类型问题时的表现。他们先让AI在一个简单的数学问题集(GSM8K)上训练,然后用一个更难的数学问题集(MATH)来测试它。结果发现,经过多轮”自学”的AI在面对这些新问题时,表现反而更差。而且,AI在简单问题和困难问题上的表现差距越来越大,这说明它可能只是在”死记硬背”,而不是真正理解和学习。
毫无疑问,post-training阶段的”自我提升“仍然是一个充满潜力的研究方向,”让AI自我提升”也是一个很酷的想法。但GAIR团队的发现表明,AI的进化之路可能比想象中更加复杂和充满挑战。在追求AI性能提升的同时,也需要更全面地考虑:
AI真正的问题解决能力是否提升了?
AI是否保持了创造力和多样性?
AI能否灵活应对新的、未知的情况?
人工智能的未来令人期待,但同时也需要以更加审慎和全面的视角来看待其发展。只有这样,才能真正实现AI的潜力,创造出既智能又可靠的系统,为人类社会带来真正的价值。
实验室介绍:
生成式人工智能研究实验室(GAIR,主页:https://plms.ai/)由上海交通大学刘鹏飞副教授2023年4月回国创建,是国内首个聚焦于生成式人工智能的高校研究组。汇聚了来自于CMU、复旦、交大(ACM班、IEEE试点班等)等顶尖高校的年轻本硕博人才。实验室专注于三大核心领域:大模型基础研究、对齐系统和社会影响,致力于培养顶尖人工智能人才(具有原创、批判精神等)、开发尖端的生成式人工智能技术,赋能人类解决复杂问题,提升人类生活质量。
论文地址:
https://arxiv.org/pdf/2407.05013
项目主页:https://gair-nlp.github.io/self-improvement-reversal/
投稿请发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

点这里?关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~

