
Published on July 19, 2024 4:10 PM GMT
New paper from the Google DeepMind mechanistic interpretability team, led by Sen Rajamanoharan!
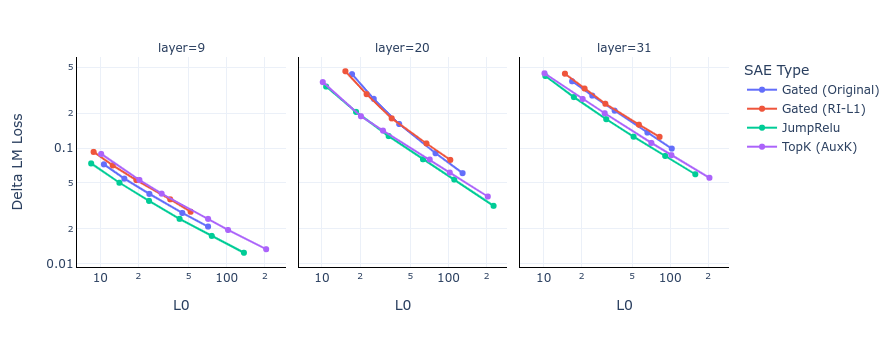
We introduce JumpReLU SAEs, a new SAE architecture that replaces the standard ReLUs with discontinuous JumpReLU activations, and seems to be (narrowly) state of the art over existing methods like TopK and Gated SAEs for achieving high reconstruction at a given sparsity level, without a hit to interpretability. We train through discontinuity with straight-through estimators, which also let us directly optimise the L0.
To accompany this, we will release the weights of hundreds of JumpReLU SAEs on every layer and sublayer of Gemma 2 2B and 9B in a few weeks. Apply now for early access to the 9B ones! We're keen to get feedback from the community, and to get these into the hands of researchers as fast as possible. There's a lot of great projects that we hope will be much easier with open SAEs on capable models!
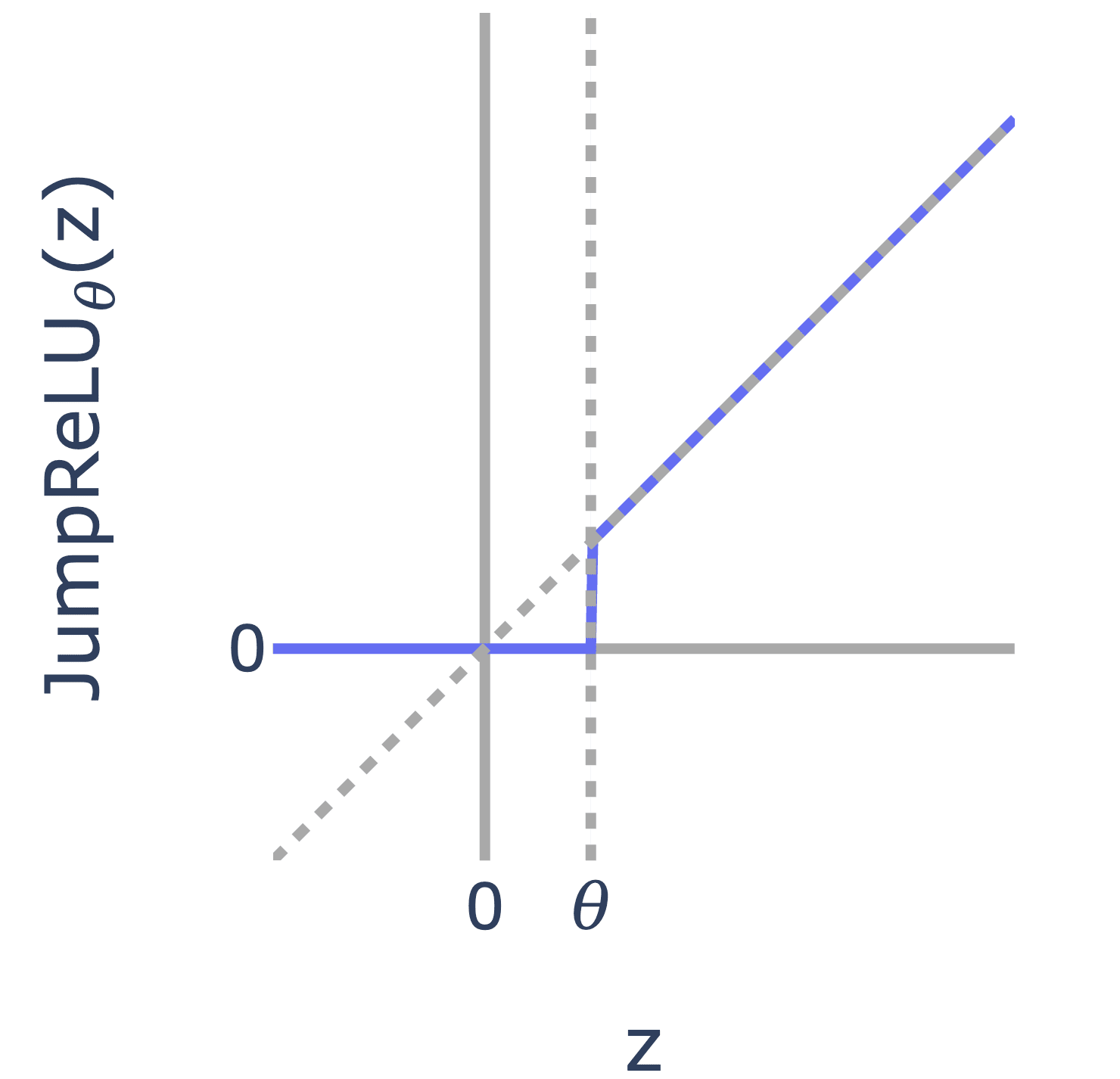

Gated SAEs already reduced to JumpReLU activations after weight tying, so this can be thought of as Gated SAEs++, but less computationally intensive to train, and better performing. They should be runnable in existing Gated implementations.
Abstract:
Sparse autoencoders (SAEs) are a promising unsupervised approach for identifying causally relevant and interpretable linear features in a language model’s (LM) activations. To be useful for downstream tasks, SAEs need to decompose LM activations faithfully; yet to be interpretable the decomposition must be sparse – two objectives that are in tension. In this paper, we introduce JumpReLU SAEs, which achieve state-of the-art reconstruction fidelity at a given sparsity level on Gemma 2 9B activations, compared to other recent advances such as Gated and TopK SAEs. We also show that this improvement does not come at the cost of interpretability through manual and automated interpretability studies. JumpReLU SAEs are a simple modification of vanilla (ReLU) SAEs – where we replace the ReLU with a discontinuous JumpReLU activation function – and are similarly efficient to train and run. By utilising straight-through-estimators (STEs) in a principled manner, we show how it is possible to train JumpReLU SAEs effectively despite the discontinuous JumpReLU function introduced in the SAE’s forward pass. Similarly, we use STEs to directly train L0 to be sparse, instead of training on proxies such as L1, avoiding problems like shrinkage.
Discuss
