
Published on July 18, 2024 10:29 AM GMT
This is an interim report sharing preliminary results that we are currently building on. We hope this update will be useful to related research occurring in parallel.
Executive Summary
- We train SAEs on base / chat model pairs and find that SAEs trained on the base model transfer surprisingly well to reconstructing chat activations (and vice versa) on Mistral-7B and Qwen 1.5 0.5B.
- We also find that they don’t transfer on Gemma v1 2B, and are generally bad at reconstructing <1% of unusually high norm activations (e.g. BOS tokens) from the opposite model.
Introduction
Fine-tuning is a common technique applied to improve frontier language models, however we don’t actually understand what fine-tuning changes within the model’s internals. Sparse Autoencoders are a popular technique to decompose the internal activations of LLMs into sparse, interpretable features, and may provide a path to zoom into the differences between base vs fine-tuned representations.
In this update, we share preliminary results studying the representation drift caused by fine-tuning with SAEs. We investigate whether SAEs trained to accurately reconstruct a base model’s activations also accurately reconstruct activations from the model after fine-tuning (and vice versa). In addition to studying representation drift, we also think this is an important question to gauge the usefulness of sparse autoencoders as a general purpose technique. One flaw of SAEs is that they are expensive to train, so training a new suite of SAEs from scratch each time a model is fine-tuned may be prohibitive. If we are able to fine-tune existing SAEs for much cheaper, or even just re-use them, their utility seems more promising.
We find that SAEs trained on the middle-layer residual stream of base models transfer surprisingly well to the corresponding chat model, and vice versa. Splicing in the base SAE to the chat model achieves similar CE loss to the chat SAE on both Mistral-7B and Qwen 1.5 0.5B. This suggests that the residual streams for these base and chat models are very similar.
However, we also identify cases where the SAEs don’t transfer. First, the SAEs fail to reconstruct activations from the opposite model that have outlier norms (e.g. BOS tokens). These account for less than 1% of the total activations, but cause cascading errors, so we need to filter these out in much of our analysis. We also find that SAEs don’t transfer on Gemma v1 2B. We find that the difference in weights between Gemma v1 2B base vs chat is unusually large compared to other fine-tuned models, explaining this phenomenon.
Finally, to solve the outlier norm issue, we fine-tune a Mistral 7B base SAE on just 5 million tokens (compared to 800M token pre-training), to obtain a chat SAE of comparable quality to one trained from scratch, without the need to filter out outlier activations.
Investigating SAE Transfer between base and chat models
In this section we investigate if base SAEs transfer to chat models, and vice versa. We find that with the exception of outlier norm tokens (e.g. BOS), they transfer surprisingly well, achieving similar CE loss recovered to the original SAE across multiple model families and up to Mistral-7B.
For each pair of base / chat models, we train two different SAEs on the same site of the base and chat model respectively. All SAEs are trained on the pile on a middle layer of the residual stream. We used SAELens for training, and closely followed the setup from Conerly et al.
We evaluate the base SAEs on chat activations and vice versa, using standard metrics like L0 norm, CE loss recovered, MSE, and explained variance. All evals in this section are on 50k-100k tokens from the pile. We don’t apply any special instruction formatting for the chat models, and analyze this separately in Investigating SAE transfer on instruction data.
Note that we exclude activations with outlier norms in this section. That is, we identify activations with norm above a threshold, and exclude these from the evals. We find that the SAEs fail to reconstruct these activations from the opposite model. However in the Identifying Failures section, we show that these only make up <1% of activations, and we find that they mostly stem from special tokens like BOS. With this caveat, we find that the SAEs transfer surprisingly well, achieving extremely similar CE loss recovered when spliced into the opposite model:
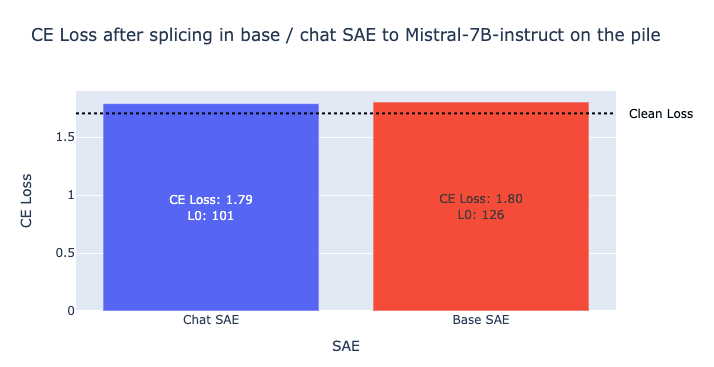
We also provide a more comprehensive table with standard SAE evaluation metrics for each (SAE, model) pair for Mistral 7B:
Models: Mistral-7B / Mistral-7B Instruct. Site: resid_pre layer 16. SAE widths: 131027
| SAE | Model | L0 | CE Loss rec % | Clean CE Loss | SAE CE Loss | CE Delta | 0 Abl. CE loss | Explained Variance % | MSE |
| Base | Base | 95 | 98.71% | 1.51 | 1.63 | 0.12 | 10.37 | 68.1% | 1014 |
| Chat | Base | 72 | 96.82% | 1.51 | 1.79 | 0.28 | 10.37 | 52.6% | 1502 |
| Chat | Chat | 101 | 99.01% | 1.70 | 1.78 | 0.08 | 10.37 | 69.2% | 1054 |
| Base | Chat | 126 | 98.85% | 1.70 | 1.80 | 0.10 | 10.37 | 60.9% | 1327 |
Though we focus on Mistral-7B in this post, we find similar results with Qwen1.5 0.5B, and share these in the appendix. However, we find that the SAEs don’t transfer on Gemma v1 2B, and we think this model is unusually cursed. We provide further analysis in Identifying failures.
We think the fact that SAEs can transfer between base and chat models is suggestive evidence that:
- The residual streams of the base and chat models are often extremely similarBase-model SAEs can likely be applied to interpret and steer chat models, without the need to train a new chat SAE from scratch
Identifying failures: Outlier norm activations and Gemma v1 2B
As mentioned above, we find that the SAEs are very bad at reconstructing extremely high norm activations from the opposite model. Although these only account for less than 1% of each model’s activations, this can cause cascading errors when splicing in the SAEs during the CE loss evals, and blows up the average MSE / L0.
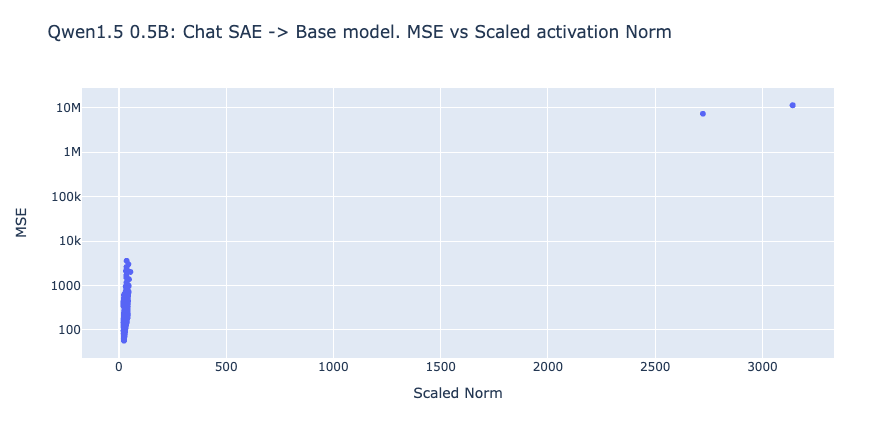
Here we analyze these activations in more detail. Over the same 100,000 tokens used for the evals above, we compute the norms of each activation, and record tokens with norms above a set threshold. Note that we consider the norms of the scaled activations, where each activation is scaled to have average norm sqrt(d_model) (see Conerly et al.). For each model we present the fraction of activations that have norms above this threshold, as well as a breakdown of what tokens are at these positions. In every case we find that the number of outliers is less than 1% of the total activations.
| Model | Outlier threshold | Frac outliers | Breakdown |
| Qwen 1.5 0.5B | 50 | 0.000488 | 100% BOS token |
| Qwen 1.5 0.5B Chat | 50 | 0.001689 | 29% BOS Tokens, 71% always within first 10 positions |
| Gemma v1 2B | 300 | 0.001892 | 100% BOS |
| Gemma v1 2B It | 300 | 0.001892 | 100% BOS |
| Mistral-7B | 200 | 0.001872 | 63% BOS, 26% first newline token, 11% paragraph symbols |
| Mistral-7B-instruct | 200 | 0.002187 | 53% BOS, 46% newline tokens |
Although the number of outliers is small, and we were able to classify all of the high norm tokens that we filtered out from our evals, we don’t think ignoring outlier tokens is an ideal solution. That being said, we think they are infrequent enough that we can still make the claim that these SAEs mostly transfer between base and chat models. We also show that we can cheaply fine-tune base SAEs to learn to reconstruct these outlier norms in Fine-tuning base SAEs for chat models.
What’s up with Gemma v1 2B?
Recall that we found that SAEs trained on Gemma v1 2B base did not transfer to Gemma v1 2B IT, unlike the Qwen and Mistral models. Here we show that the weights for Gemma v1 2B base vs chat models are unusually different, explaining this phenomenon (credit to Tom Lieberum for finding and sharing this result):

Investigating SAE Transfer on Instruction Formatted Data
So far, we have only evaluated the SAEs on the pile, but Chat models are trained on the completions of instruction formatted data. To address this, we now evaluate our Mistral SAEs on an instruction dataset.
We take ~50 instructions from alpaca and generate rollouts with Mistral-7B-instruct using greedy sampling. We then evaluate both the base and chat SAEs (trained on the pile) separately on the rollout and user prompt tokens. In the rollout case we only splice the SAE in the rollout positions, and in the user prompt case we only splice the SAE in the user prompt positions. We continue to filter outlier activations, using the same thresholds as above.
Model: Mistral 7B Instruct. Site: resid_pre layer 16. SAE widths: 131027. Section: Rollout.
| SAE | Model | L0 | CE Loss rec % | Clean CE Loss | SAE CE Loss | CE delta | 0 Abl. CE loss | Explained Variance % | MSE |
| Chat | Chat | 168 | 97.67 | 0.16 | 0.46 | 0.30 | 12.92 | 54.4% | 1860 |
| Base | Chat | 190 | 97.42 | 0.16 | 0.49 | 0.33 | 12.92 | 49.7% | 2060 |
Section: User Prompt.
| SAE | Model | L0 | CE Loss rec % | Clean CE Loss | SAE CE Loss | CE delta | 0 Abl. CE loss | Explained Variance % | MSE |
| Chat | Chat | 95 | 100.9% | 3.25 | 3.17 | -0.08 | 11.63 | 62.6% | 1411 |
| Base | Chat | 147 | 99.95% | 3.25 | 3.25 | 0.00 | 11.63 | 52.3% | 1805 |
We notice that both SAEs perform worse in terms of reconstruction compared to the pile, suggesting that we might benefit from training on some instruction formatted data. However we still notice that the base model performs similarly to the chat SAE, especially on the CE loss metrics, continuing to transfer surprisingly well. We note that the CE Loss metrics on the user prompt are difficult to interpret, since models are not trained to predict these tokens during instruction fine-tuning.
Fine-tuning Base SAEs for Chat Models
In the previous section, we have shown that base SAEs transfer surprisingly well to chat models with two caveats:
- They fail to reconstruct activations with outlier norms, like BOS tokensThey do not transfer if the base and chat models are unusually different (e.g. Gemma v1 2B)
To address the outlier norm problem, we now show that we can fine-tune base SAEs on chat activations to acquire a chat SAE of comparable quality to training one from scratch, for a fraction of the cost. Here we fine-tuned our Mistral-7B base SAE on 5 million chat activations to achieve competitive reconstruction fidelity and sparsity to the chat SAE that was trained from scratch (800 million tokens). These evaluations are performed on the pile, but we do not filter outlier activations, unlike above.
Model: Mistral-7B Instruct. Site: resid_pre layer 16. SAE widths: 131027. Not ignoring outliers:
| SAE | Model | L0 | CE Loss rec % | Clean CE Loss | SAE CE Loss | CE delta | 0 Abl. CE loss | Explained Variance % | MSE |
| Chat | Chat | 101 | 99.01% | 1.70 | 1.78 | 0.08 | 10.37 | 69.4% | 1054 |
| Base | Chat | 170 | 98.38% | 1.70 | 1.84 | 0.14 | 10.37 | 32.2% | 724350 |
| Fine-tuned base | Chat | 86 | 98.75% | 1.70 | 1.81 | 0.11 | 10.37 | 65.4% | 1189 |
The CE loss, explained variance, and MSE metrics show that the fine-tuned SAE obtains similar reconstruction fidelity to one trained from scratch. Further, our fine-tuned SAE is even sparser, with a notably lower average L0 norm.
Details of fine-tuning: We fine-tuned the existing base SAE to reconstruct chat activations on 5 million tokens from the pile. We used the same learning rate as pre-training, with a linear warmup for the first 5% of fine-tuning, and a decay to zero for the last 20%. We used a smaller batch size of 256 (compared for 4096 in pretraining). We used the same L1-coefficient as pre-training, but unlike pre-training, we did not apply an L1-coefficient warmup. Everything else is identical to the pre-training set up which closely followed Conerly et al. We did not tune these hyperparameters (this was our first attempt for Mistral), and suspect the fine-tuning process can be improved.
A natural next step might be to just fine-tune the base SAE on instruction formatted data with generations from the chat model, though we don’t focus on that in this work.
Conclusion
Overall, we see these preliminary results as an interesting piece of evidence that the residual streams between base and chat models are often very similar. We’re also excited that we can cheaply fine-tune existing base SAEs (or even just use the same base SAE) as we fine-tune the language models from which they were trained.
We see two natural directions of future work that we plan to pursue:
- Case studies: If the residual streams are so similar, then what causes chat models to e.g. refuse while base models do not? More thorough analysis at the feature level. E.g. how many features are the same, how many are modified, how many are new / deleted, etc after fine-tuning.
Limitations
- In all of our SAE evals (with the exception of the fine-tuning SAEs section), we filtered out activations with outlier norms. Though these account for less than 1% of the models’ activations, we would ideally like the option to apply SAEs to every activation.We studied 3 different models from different families and varying sizes, but in each case we trained SAEs on the middle layer residual stream. It’s possible that the results vary across different layers and sites.We trained both base and chat SAEs on the pile, following Templeton et al. It’s plausible that we should be training chat SAEs on some kind of instruction formatted data (e.g. to improve reconstruction quality on the rollouts), though the details of how to properly do this are not obvious. Upcoming research some authors are involved with this post are working on tentatively shows very similar conclusions, while addressing these limitations.Though our fine-tuned SAEs reported promising evaluation metrics, we did not evaluate feature interpretability of our fine-tuned SAE compared to the chat SAE trained from scratch. If fine-tuned SAEs are less interpretable (despite the similar L0), then they will be less useful.We report CE recovered, but since the zero ablation baseline for the residual stream is very unrealistic, and a more comprehensive evaluation would measure metrics such as the effective compute cost increase, following e.g. this comment thanks to Leo Gao.
Citing this work
This is ongoing research. If you would like to reference any of our current findings, we would appreciate reference to:
@misc{sae_finetuning, author= {Connor Kissane and Robert Krzyzanowski and Arthur Conmy and Neel Nanda}, url = {https://www.alignmentforum.org/posts/fmwk6qxrpW8d4jvbd/saes-usually-transfer-between-base-and-chat-models}, year = {2024}, howpublished = {Alignment Forum}, title = {SAEs (usually) Transfer Between Base and Chat Models},}Author contributions Statement
Connor and Rob were core contributors on this project. Connor trained the Mistral-7B and Qwen 1.5 0.5B SAEs. Rob trained the Gemma v1 2B SAEs. Connor performed all the experiments and wrote the post. Arthur suggested running the rollout/user prompt experiments. Arthur and Neel gave guidance and feedback throughout the project. The original project idea was suggested by Neel.
Acknowledgments
We’re grateful to Wes Gurnee for sharing extremely helpful advice and suggestions at the start of the project. We’d also like to thank Tom Lieberum for sharing the result on Gemma v1 2B base vs chat weight norms.
- ^
The wandb links show wandb artifacts of the SAE weights, and you can also view the training logs.
Discuss
