


Spatiotemporal prediction is a critical area of research in computer vision and artificial intelligence. It leverages historical data to predict future events. This technology has significant implications across various fields, such as meteorology, robotics, and autonomous vehicles. It aims to develop accurate models to forecast future states from past and present data, impacting applications from weather forecasting to traffic flow management.
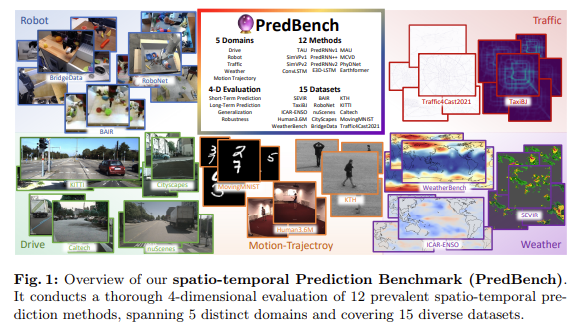
A major challenge in spatio-temporal prediction is the need for a standardized framework to evaluate different network architectures. This inconsistency hinders meaningful comparisons of various models’ performance. Researchers emphasize the need for a comprehensive benchmarking system to provide detailed and comparative analyses of different prediction methods across multiple applications. The research team introduced PredBench, a holistic benchmark for evaluating spatio-temporal prediction networks to address this.
Current methods and tools often need to evaluate spatio-temporal prediction networks comprehensively. Traditional studies typically assess models on limited datasets, resulting in an incomplete understanding of their performance across diverse scenarios. Inconsistent experimental settings across different networks further complicate fair comparisons, as models might use varied settings even within the same dataset.
Researchers from Shanghai AI Laboratory, The Chinese University of Hong Kong, Shanghai Jiao Tong University, Sydney University, and The University of Hong Kong introduced PredBench, which offers a standardized framework for evaluating spatio-temporal prediction networks across multiple domains. PredBench integrates 12 widely adopted methods and 15 diverse datasets. It aims to provide a holistic evaluation by maintaining consistent experimental settings and employing a multi-dimensional framework. This framework includes short-term and long-term prediction abilities, generalization capabilities, and temporal robustness, allowing for a deeper model performance analysis across various applications.
PredBench standardizes prediction settings across different networks to ensure fair comparisons and introduces new evaluation dimensions. These dimensions assess short-term and long-term prediction abilities, generalization abilities, and temporal robustness of models. This comprehensive approach allows for a deeper model performance analysis across applications, from weather forecasting to autonomous driving.
The performance of PredBench models, such as PredRNN++ and MCVD, has demonstrated high visual quality and predictive accuracy in different domains. The research team conducted extensive experiments to evaluate the models’ capabilities, revealing insights that can guide future developments in spatio-temporal prediction. PredBench is the most exhaustive benchmark, integrating 12 established STP methods and 15 diverse datasets from various applications and disciplines.
The benchmark employs tailored metrics for distinct tasks. Mean Absolute Error (MAE) & Root Mean Squared Error (RMSE) assess the discrepancy between predicted and target sequences. Structural Similarity Index Measure (SSIM) and Peak Signal-to-Noise Ratio (PSNR) gauge the resemblance between prediction and ground truth, providing image quality assessment. Learned Perceptual Image Patch Similarity (LPIPS) and Fréchet Video Distance (FVD) assess perceptual similarity, aligning with the human visual system. For weather forecasting, metrics like Weighted Root Mean Squared Error (WRMSE) and Anomaly Correlation Coefficient (ACC) align with domain-specific benchmarks.
PredBench employs a meticulously standardized experimental protocol to ensure comparability and replicability across various prediction tasks. For instance, the motion trajectory prediction tasks use datasets like Moving-MNIST, KTH, and Human3.6M, with standardized input-output settings to ensure experimental consistency. Robot action prediction uses datasets like RoboNet, BAIR, and BridgeData while driving scene prediction, which leverages CityScapes, KITTI, and nuScenes datasets. Traffic flow prediction utilizes TaxiBJ and Traffic4Cast2021, and weather forecasting evaluates using ICAR-ENSO, SEVIR, and WeatherBench datasets.
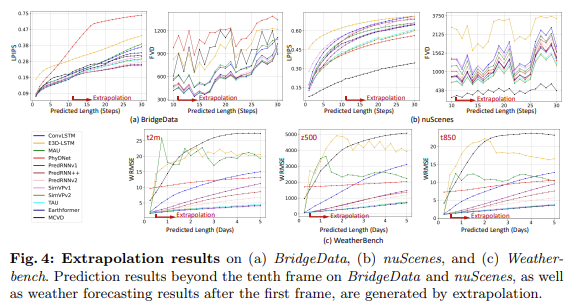
PredBench’s multi-dimensional evaluation framework provides thorough and detailed assessments of various spatio-temporal prediction models. The short-term prediction task focuses on forecasting imminent future states given historical data. Long-term prediction ability is assessed by extrapolation, where models iteratively use their predictions as inputs to generate further into the future. Generalization remains a pivotal yet underexplored facet of STP research. PredBench evaluates generalization across diverse datasets and scenarios, such as robot action prediction and driving scene prediction.

In conclusion, PredBench, providing a standardized and comprehensive benchmarking system, addresses the gaps in current evaluation practices and offers strategic directions for future research. This development is expected to catalyze progress in the field, promoting the creation of more accurate and robust prediction models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post PredBench: A Comprehensive AI Benchmark for Evaluating 12 Spatio-Temporal Prediction Methods Across 15 Diverse Datasets with Multi-Dimensional Analysis appeared first on MarkTechPost.
