


Hugging Face has recently released SmolLM, a family of state-of-the-art small models designed to provide powerful performance in a compact form. The SmolLM models are available in three sizes: 135M, 360M, and 1.7B parameters, making them suitable for various applications while maintaining efficiency and performance.
SmolLM is a new series of small language models developed by Hugging Face, aimed at delivering high performance with lower computational costs and improved user privacy. These models are trained on a meticulously curated high-quality dataset, SmolLM-Corpus, which includes diverse educational and synthetic data sources. The three models in the SmolLM family, 135M, 360M, and 1.7B parameters, are designed to cater to different levels of computational resources while maintaining state-of-the-art performance.
The SmolLM models are built on the SmolLM-Corpus, a dataset comprising various high-quality sources such as Cosmopedia v2, Python-Edu, and FineWeb-Edu. Cosmopedia v2, for instance, is an enhanced version of a synthetic dataset generated by Mixtral, consisting of over 30 million textbooks, blog posts, and stories. This dataset ensures a broad coverage of topics and prompts, improving the diversity and quality of the training data.
For the 1.7B parameter model, Hugging Face used 1 trillion tokens from the SmolLM-Corpus, while the 135M and 360M parameter models were trained on 600 billion tokens. The training process employed a trapezoidal learning rate scheduler with a cooldown phase, ensuring efficient and effective model training. The smaller models incorporated Grouped-Query Attention (GQA) and prioritized depth over width in their architecture, while the larger 1.7B parameter model utilized a more traditional design.
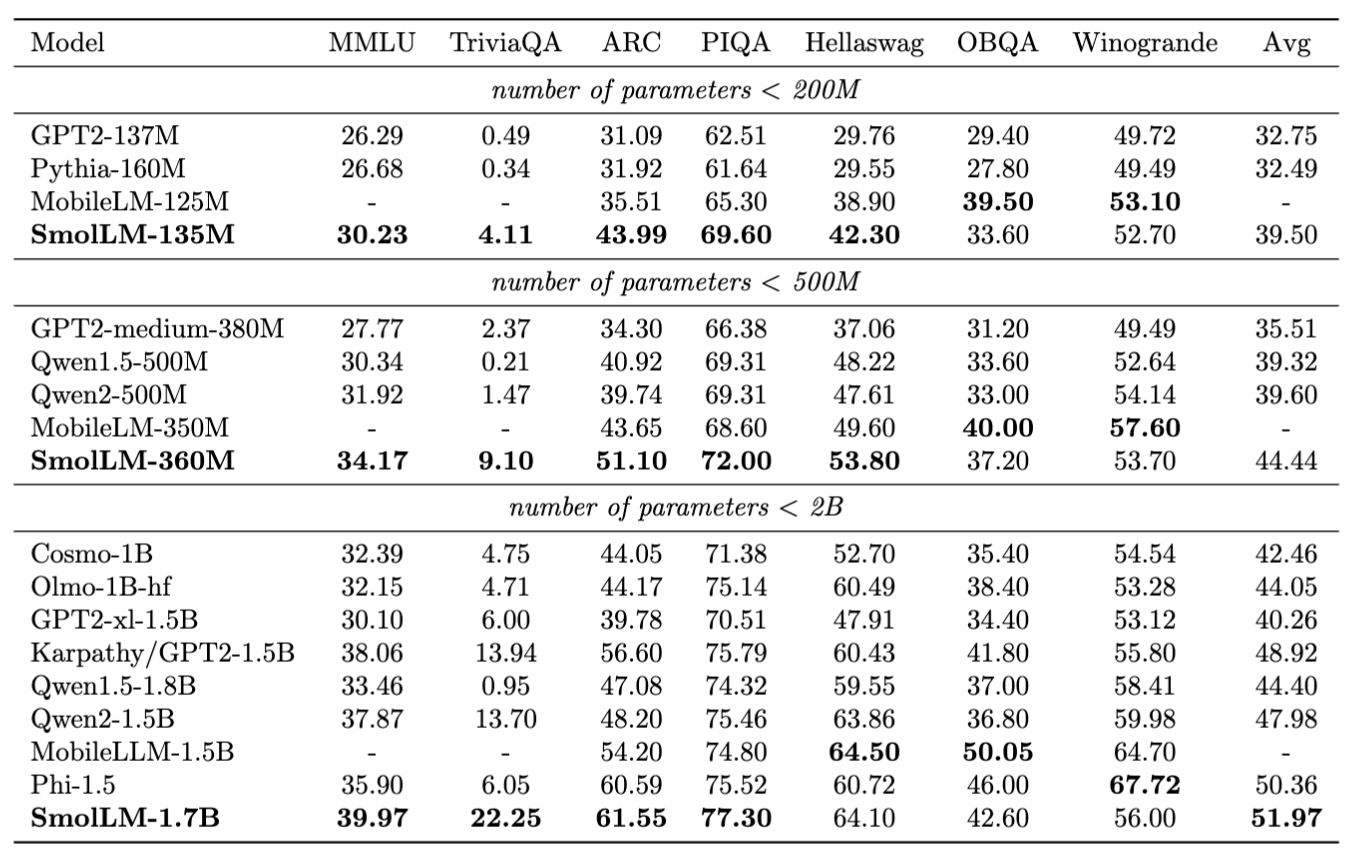
SmolLM models were evaluated across benchmarks, testing common sense reasoning and world knowledge. The models demonstrated impressive performance, outperforming others in their respective size categories. For instance, despite being trained on fewer tokens, the SmolLM-135M model surpassed MobileLM-125M, the current best model with less than 200M parameters. Similarly, the SmolLM-360M and SmolLM-1.7B models outperformed all other models with less than 500M and 2B parameters, respectively.

The models were also instruction-tuned using publicly available permissive instruction datasets, enhancing their performance on benchmarks like IFEval. The tuning involved training the models for one epoch on a subset of the WebInstructSub dataset, combined with StarCoder2-Self-OSS-Instruct, and performing Direct Preference Optimization (DPO) for another epoch. This process ensured that the models balanced between size and performance.
One of the significant advantages of the SmolLM models is their ability to run efficiently on various hardware configurations, including smartphones and laptops. This makes them suitable for deployment in multiple applications, from personal devices to more substantial computational setups. Hugging Face has also released WebGPU demos for the SmolLM-135M and SmolLM-360M models, showcasing their capabilities and ease of use.
In conclusion, Hugging Face has successfully demonstrated that high-performance models can be achieved with efficient training on high-quality datasets, providing a robust balance between model size and performance. The SmolLM models are set to revolutionize the landscape of small language models, offering powerful and efficient solutions for various applications.
Check out the Models and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Hugging Face Introduces SmolLM: Transforming On-Device AI with High-Performance Small Language Models from 135M to 1.7B Parameters appeared first on MarkTechPost.
