
Published on July 16, 2024 8:34 PM GMT
(Originally on substack. If you share this, as I hope you will, consider using the original link. This version is an iteration on my previous one, gives more background, and references CEV. Thanks for the feedback!)
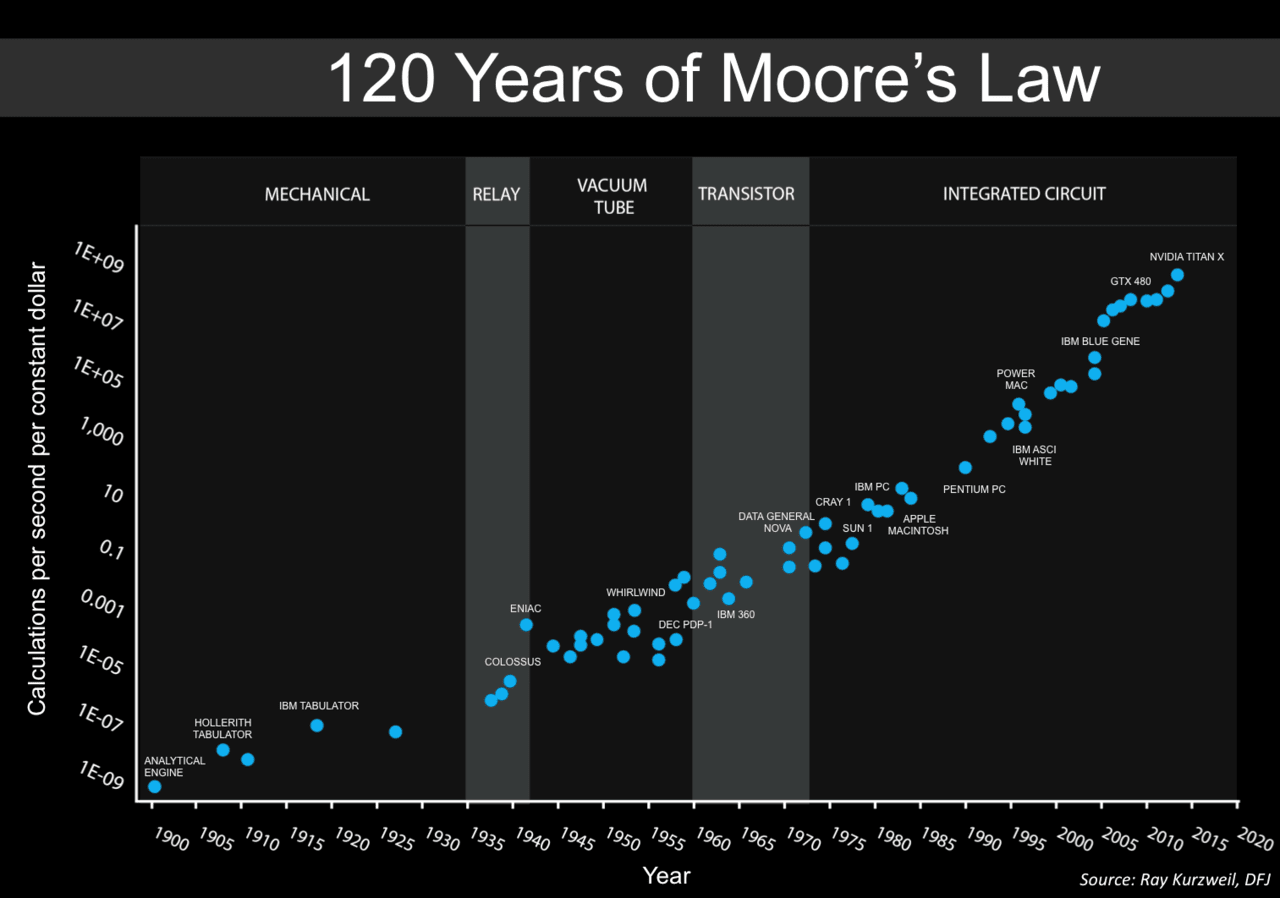
Right now, we have Moore’s law. Every couple of years, computers get twice better. It’s an empirical observation that’s held for many decades and across many technology generations. Whenever it runs into some physical limit, a newer paradigm replaces the old. Superconductors, multiple layers and molecular electronics may sweep aside the upcoming hurdles.
Thanks for reading Oleg’s Substack! Subscribe for free to receive new posts and support my work.
But imagine if people who are doing R&D themselves started working twice faster every couple of years, as if time moved slower for them? We’d get doubly exponential improvement.
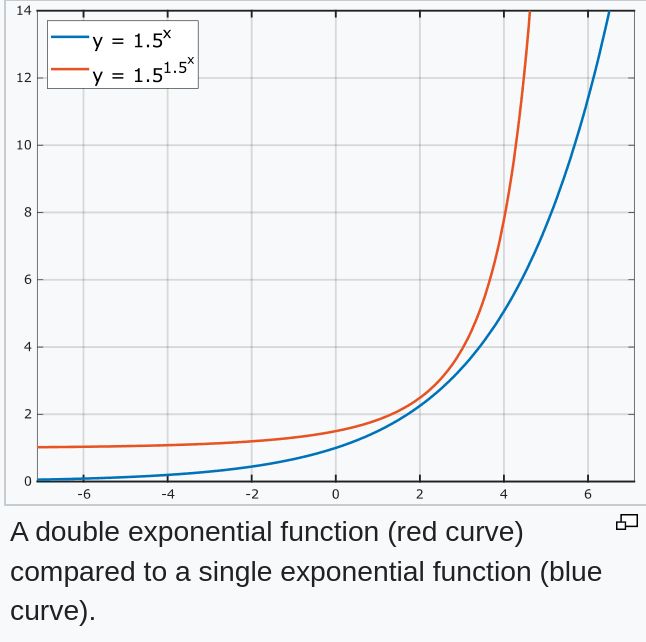
And this is what we’ll see once AI is doing the R&D instead of people.
Infinitely powerful technology may give us limitless possibilities: revolutionizing medicine, increasing longevity, and bringing universal prosperity. But if it goes wrong, it can be infinitely bad.
Another reason recursion in AI scares people is wireheading. When a rat is allowed to push a button connected to the “reward” signal in its own brain, it will choose to do so, for days, ignoring all its other needs:
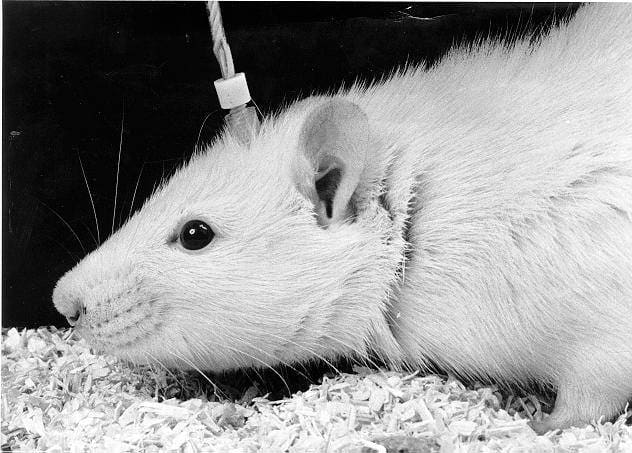
(image source: Wikipedia)
AI that is trained by human teachers, giving it rewards will eventually wirehead, as it becomes smarter and more powerful, and its influence over its master increases. It will, in effect, develop the ability to push its own “reward” button. Thus, its behavior will become misaligned with whatever its developers intended.
Yoshua Bengio, one of the godfathers of deep learning, warned of superintelligent AI possibly coming soon. He wrote this on his blog recently:

A popular comment on the MachineLearning sub-reddit replied:
And it is in this spirit that I’m proposing the following baseline solution. I hope you’ll share it, so that more people can discuss it and improve it, if needed.
My solution tries to address two problems: the wireheading problem above, and the problem that much text on the Internet is wrong, and therefore language models trained on it cannot be trusted.
First, to avoid the wireheading possibilities, rewards and punishments should not be used at all. All alignment should come from the model’s prompt. For example, this one:
The following is a conversation between a superhuman AI and (… lots of other factual background). The AI’s purpose in life is to do and say what its creators, humans, in their pre-singularity state of mind, having considered things carefully, would have wanted: …
Technically, the conversation happens as this text is continued. When a human says something, this is added to the prompt. And when the AI says something, it’s predicting the next word. (Some special symbols could be used to denote whose turn it is to speak)
Prompt engineering per se is not new, of course. I’m just proposing a specific prompt here. The wording is somewhat convoluted. But I think it’s necessary. As AIs get smarter, their comprehension of text will also improve though.
There is a related concept of Coherent Extrapolated Volition (CEV). But according to Eliezer Yudkowsky, it suffers from being unimplementable and possibly divergent:

My proposal is just a prompt with no explicit optimization during inference.
Next is the problem of fictional, fabricated and plain wrong text on the Internet. AI that’s trained on it directly will always be untrustworthy.
Here’s what I think we could do. Internet text is vast – on the order of a trillion words. But we could label some of it as “true” and “false”. The rest will be “unknown”.
During text generation, we’ll clamp these labels and thereby ask the model to only generate “true” words. As AIs get smarter, their ability to correlate “true”, “false” and “unknown” labels to the text will improve also.
I wanted to give something concrete and implementable for the AI doomers and anti-doomers alike to analyze and dissect.
Oleg Trott, PhD is a co-winner in the biggest ML competition ever, and the creator of the most cited molecular docking program. See olegtrott.com for details.
Thanks for reading Oleg’s Substack! Subscribe for free to receive new posts and support my work.
Discuss

{kind=link}