
Florence-2 是微软于 2024 年 6 月发布的一个基础视觉语言模型。该模型极具吸引力,因为它尺寸很小 (0.2B 及 0.7B) 且在各种计算机视觉和视觉语言任务上表现出色。
Florence 开箱即用支持多种类型的任务,包括: 看图说话、目标检测、OCR 等等。虽然覆盖面很广,但仍有可能你的任务或领域不在此列,也有可能你希望针对自己的任务更好地控制模型输出。此时,你就需要微调了!
本文,我们展示了一个在 DocVQA 上微调 Florence 的示例。尽管原文宣称 Florence 2 支持视觉问答 (VQA) 任务,但最终发布的模型并未包含 VQA 功能。因此,我们正好拿这个任务练练手,看看我们能做点什么!
预训练细节与模型架构
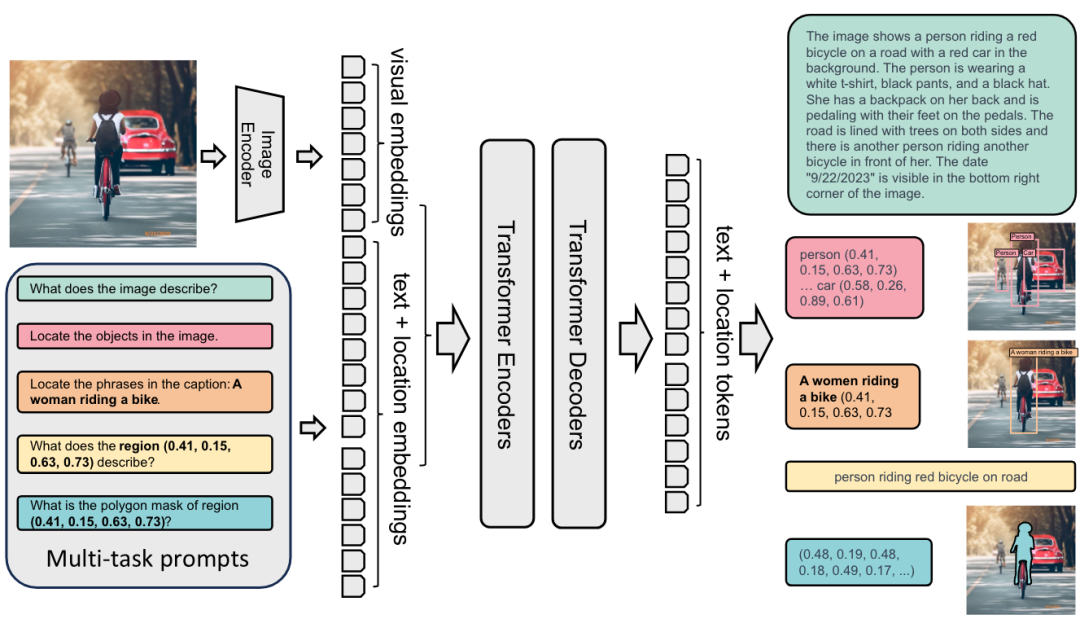
Florence-2 架构
无论执行什么样的计算机视觉任务,Florence-2 都会将其建模为序列到序列的任务。Florence-2 以图像和文本作为输入,并输出文本。模型结构比较简单: 用 DaViT 视觉编码器将图像转换为视觉嵌入,并用 BERT 将文本提示转换为文本和位置嵌入; 然后,生成的嵌入由标准编码器 - 解码器 transformer 架构进行处理,最终生成文本和位置词元。Florence-2 的优势并非源自其架构,而是源自海量的预训练数据集。作者指出,市面上领先的计算机视觉数据集通常所含信息有限 - WIT 仅有图文对,
VQA 上的原始性能
我们尝试了各种方法来微调模型以使其适配 VQA (视觉问答) 任务的响应方式。迄今为止,我们发现最有效方法将其建模为图像区域描述任务,尽管其并不完全等同于 VQA 任务。看图说话任务虽然可以输出图像的描述性信息,但其不允许直接输入问题。
我们还测试了几个“不支持”的提示,例如 “
微调后在 DocVQA 上的性能
我们使用 DocVQA 数据集的标准指标
我们创建了一个
下图给出了微调前后的推理结果对比。你还可以至

微调前后的结果
微调细节
由原文我们可以知道,基础模型在预训练时使用的 batch size 为 2048,大模型在预训练时使用的 batch size 为 3072。另外原文还说: 与冻结图像编码器相比,使用未冻结的图像编码器进行微调能带来性能改进。
我们在低资源的情况下进行了多组实验,以探索模型如何在更受限的条件下进行微调。我们冻结了视觉编码器,并在
与此同时,我们还对更多资源的情况进行了实验,以 batch size 64 对整个模型进行了微调。在配备 8 张 H100 GPU 的集群上该训练过程花费了 70 分钟。你可以在
我们都发现 1e-6 的小学习率适合上述所有训练情形。如果学习率变大,模型将很快过拟合。
遛代码
如果你想复现我们的结果,可以在
我们从安装依赖项开始。
!pip install -q datasets flash_attn timm einops
接着,从 Hugging Face Hub 加载 DocVQA 数据集。
import torch
from datasets import load_datasetdata = load_dataset("HuggingFaceM4/DocumentVQA")
我们可以使用 transformers 库中的 AutoModelForCausalLM 和 AutoProcessor 类来加载模型和处理器,并设 trust_remote_code=True ,因为该模型尚未原生集成到 transformers 中,因此需要使用自定义代码。我们还会冻结视觉编码器,以降低微调成本。
from transformers import AutoModelForCausalLM, AutoProcessor
import torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModelForCausalLM.from_pretrained("microsoft/Florence-2-base-ft",
trust_remote_code=True,
revision='refs/pr/6').to(device)processor = AutoProcessor.from_pretrained("microsoft/Florence-2-base-ft",
trust_remote_code=True, revision='refs/pr/6')for param in model.vision_tower.parameters():
param.is_trainable = False
现在开始微调模型!我们构建一个训练 PyTorch 数据集,并为数据集中的每个问题添加
import torch from torch.utils.data import Datasetclass DocVQADataset(Dataset):
def __init__(self, data):
self.data = datadef __len__(self):
return len(self.data)def __getitem__(self, idx):
example = self.data[idx]question = "
" + example['question']
first_answer = example['answers'][0]
image = example['image'].convert("RGB")
return question, first_answer, image
接着,构建数据整理器,从数据集样本构建训练 batch,以用于训练。在 40GB 内存的 A100 中,batch size 可设至 6。如果你在 T4 上进行训练,batch size 就只能是 1。
import os
from torch.utils.data import DataLoader
from tqdm import tqdm
from transformers import AdamW, get_schedulerdef collate_fn(batch):
questions, answers, images = zip(*batch)inputs = processor(text=list(questions), images=list(images), return_tensors="pt", padding=True).to(device)
return inputs, answerstrain_dataset = DocVQADataset(data['train'])
val_dataset = DocVQADataset(data['validation'])
batch_size = 6
num_workers = 0train_loader = DataLoader(train_dataset, batch_size=batch_size,collate_fn=collate_fn, num_workers=num_workers, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, collate_fn=collate_fn, num_workers=num_workers)
开始训练模型:
epochs = 7
optimizer = AdamW(model.parameters(), lr=1e-6)num_training_steps = epochs * len(train_loader)lr_scheduler = get_scheduler(name="linear", optimizer=optimizer,
num_warmup_steps=0, num_training_steps=num_training_steps,)for epoch in range(epochs):
model.train()train_loss = 0
i = -1
for inputs, answers in tqdm(train_loader, desc=f"Training Epoch {epoch + 1}/{epochs}"):
i += 1
input_ids = inputs["input_ids"]
pixel_values = inputs["pixel_values"]
labels = processor.tokenizer(text=answers, return_tensors="pt", padding=True, return_token_type_ids=False).input_ids.to(device) outputs = model(input_ids=input_ids, pixel_values=pixel_values, labels=labels) loss = outputs.loss loss.backward() optimizer.step() lr_scheduler.step() optimizer.zero_grad() train_loss += loss.item() avg_train_loss = train_loss / len(train_loader)print(f"Average Training Loss: {avg_train_loss}")
model.eval()val_loss = 0
with torch.no_grad():
for batch in tqdm(val_loader, desc=f"Validation Epoch {epoch + 1}/{epochs}"): inputs, answers = batchinput_ids = inputs["input_ids"]
pixel_values = inputs["pixel_values"]
labels = processor.tokenizer(text=answers, return_tensors="pt", padding=True, return_token_type_ids=False).input_ids.to(device) outputs = model(input_ids=input_ids, pixel_values=pixel_values, labels=labels) loss = outputs.loss val_loss += loss.item() print(val_loss / len(val_loader))
你可以分别对模型和处理器调用 save_pretrained() 以保存它们。微调后的模型在
演示示例
总结
本文,我们展示了如何有效地针对自定义数据集微调 Florence-2,以在短时间内在全新任务上取得令人眼前一亮的性能。对于那些希望在设备上或在生产环境中经济高效地部署小模型的人来说,该做法特别有价值。我们鼓励开源社区利用这个微调教程,探索 Florence-2 在各种新任务中的巨大潜力!我们迫不及待地想在 ? Hub 上看到你的模型!
有用资源
感谢 Pedro Cuenca 对本文的审阅。
英文原文: https://hf.co/blog/finetune-florence2
原文作者: Andres Marafioti,Merve Noyan,Piotr Skalski
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
