🔁 Hugging Face 转推了
𝚐𝔪𝟾𝚡𝚡𝟾 @gm8xx8
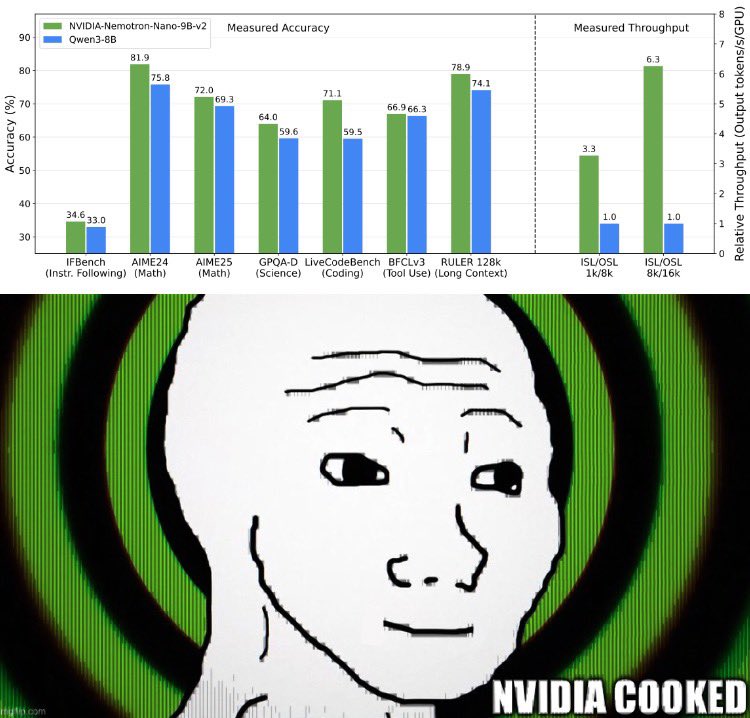
NVIDIA Nemotron-Nano v2
Models: 12B Base, 9B Reasoning, 9B Base
- Arch: Hybrid Mamba2–Transformer (128K ctx, 4 attn layers)
- Training: 10.6T tokens (3.5T synthetic from DeepSeek, Qwen, Nemotron-4, phi-4, etc.)
- 15 natural languages + 43 programming languages
- Datasets:
Models: 12B Base, 9B Reasoning, 9B Base
- Arch: Hybrid Mamba2–Transformer (128K ctx, 4 attn layers)
- Training: 10.6T tokens (3.5T synthetic from DeepSeek, Qwen, Nemotron-4, phi-4, etc.)
- 15 natural languages + 43 programming languages
- Datasets: