
今年3月GTC大會期間,輝達宣布3款商用GPU產品導入Blackwell架構,並將這些機型稱為RTX Pro Blackwell系列,5月先推出其中兩款桌上型工作站GPU,另一款是資料中心GPU產品RTX Pro 6000 Blackwell Server Edition(以下簡稱為RTX Pro 6000 BSE),輝達當時僅揭露部分規格。
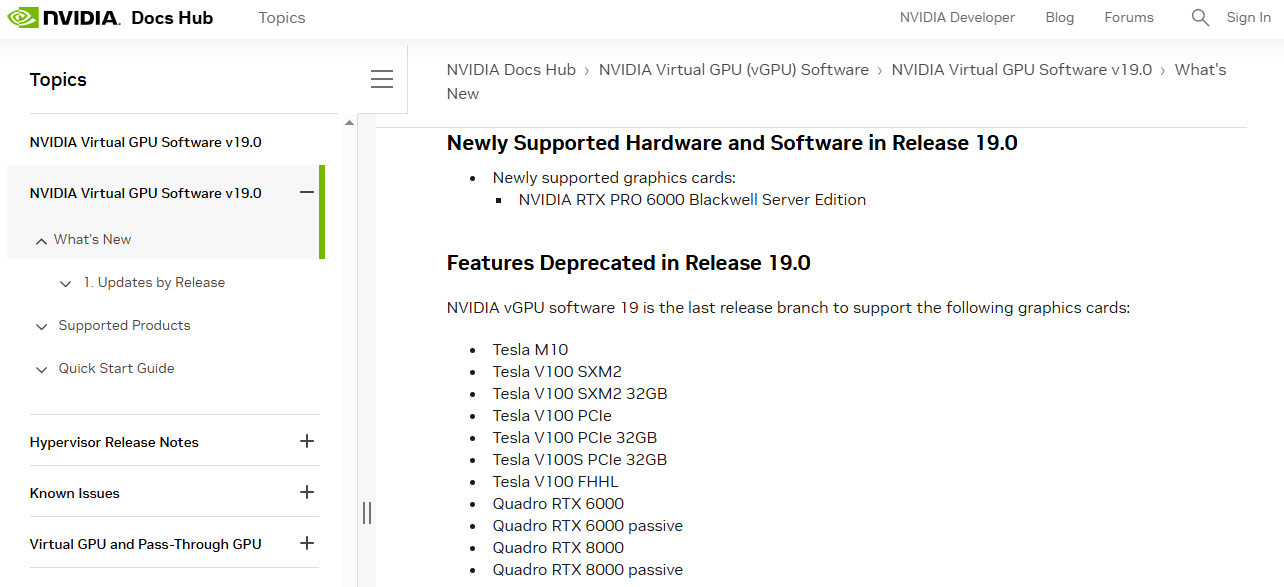
最近適逢SIGGRAPH年度大會舉行,我們發現伺服器版RTX Pro 6000 Blackwell的網頁,悄悄將產品上市狀態的標示,從原本的「即將推出(Coming Soon)」改為「現正供貨中(Coming Soon)」,而且公布更完整的技術規格文件,而在Nvidia Qualified System Catalog,也將這款GPU列入,並標明此項搭配已符合Nvidia要求的伺服器產品:Dell PowerEdge XE7745。
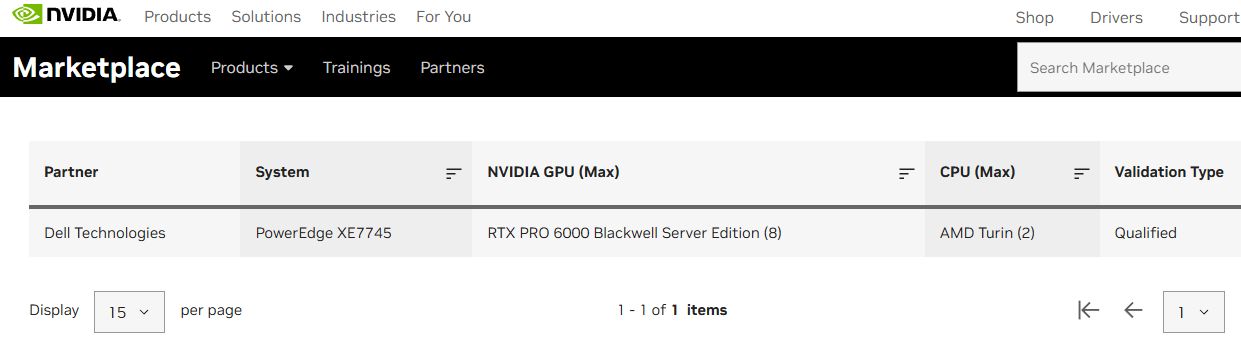
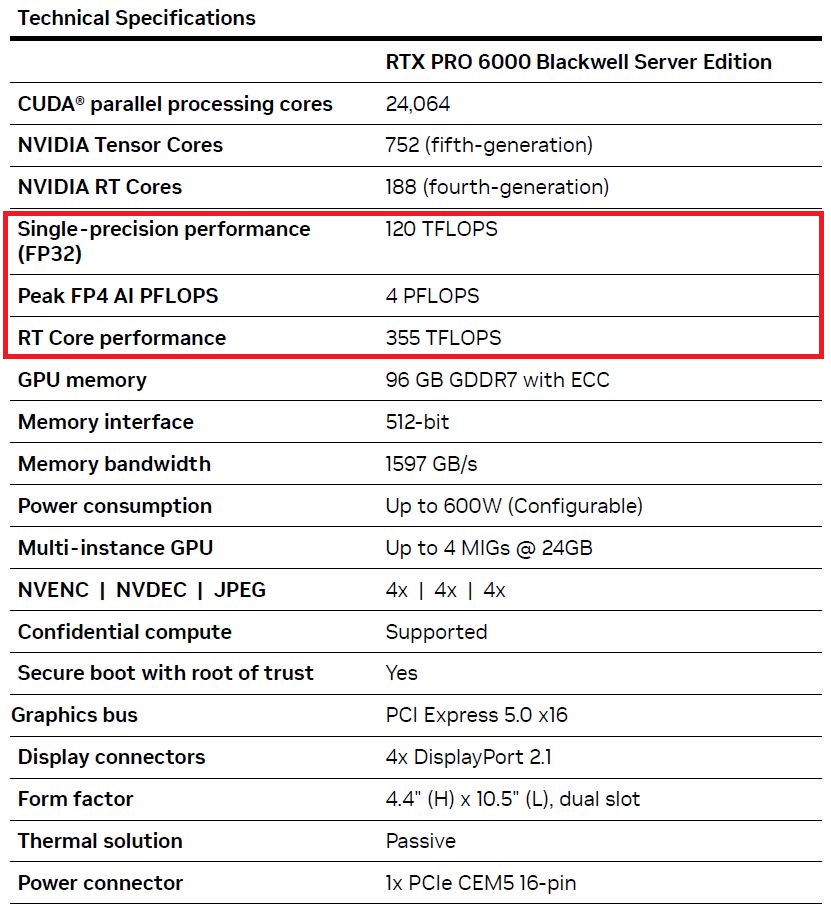
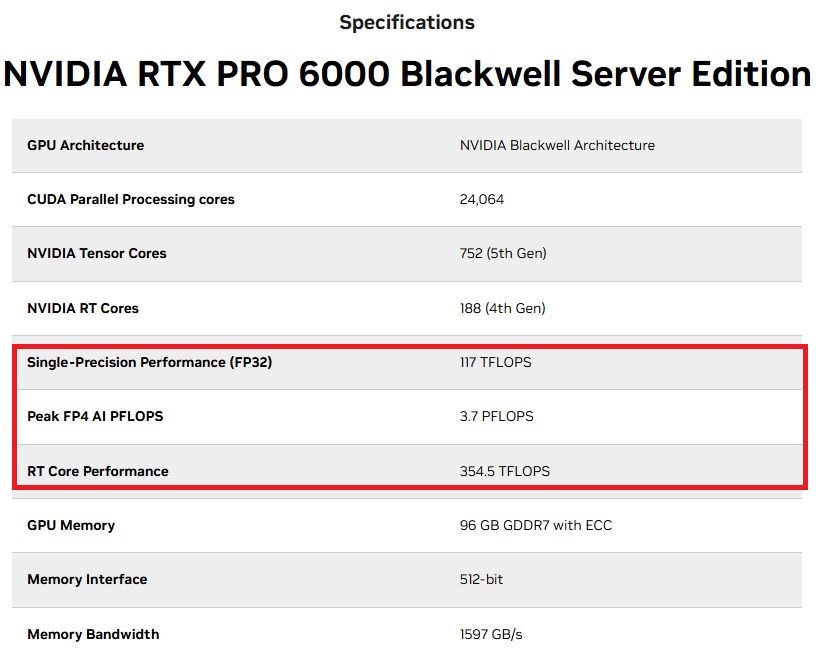
相較之下,伺服器版RTX Pro 6000 Blackwell的硬體配備,如CUDA核心、Tensor核心、RT核心的數量,以及GPU記憶體的類型、容量、頻寬,都同於先前預告的內容;對於3種運算效能的標示,也些微上修,例如,FP4最高為4 PFLOPS(先前為3.7 PFLOPS),FP32單精度為125 TFLOPS(先前為117 TFLOPS),RT核心的處理能力為355 TFLOPS(先前為354.5 TFLOPS)。
無獨有偶,輝達在8月第一週發表vGPU軟體第19版,當中唯一新支援的產品,就是RTX Pro 6000 BSE,強調GPU本身與搭配這款產品而成的RTX Pro Server伺服器平臺,可為虛擬化資料中心應用需求提供卓越的擴充性,以及更高的投資報酬率。
採用Blackwell架構,搭配最新一代Tensor核心與RT核心
單就RTX Pro 6000 BSE而言,可帶來哪些成效?Nvidia在3月預告在多種應用上,會有好幾倍的改善幅度。以採用Ada Lovelace架構的資料中心GPU產品L40S為基準,RTX Pro 6000 BSE針對代理型AI應用的大型語言模型(LLM)處理負載,吞吐量可提升至5倍,基因體學的定序速度暴增至7倍(Smith-Waterman演算法的處理可達到6.8倍),文字生成影片的速度提升至3.3倍,推薦系統的推論處理加快到逼近兩倍,著色處理速度超過兩倍。
在5月舉行的台北國際電腦展,Nvidia在自家的主題演講當中,共同創辦人暨執行長黃仁勳也親自介紹RTX Pro 6000 BSE,以及與各大伺服器廠商合作打造的RTX Pro Server。他旁邊的簡報畫面,列出搭配8張RTX Pro 6000 BSE的RTX Pro Server的效能特色,例如,使用Nvidia新創的浮點運算格式FP4,AI運算處理效能可達30 PFLOPS;執行Omniverse數位雙生即時模擬作業,效能為3 PFLOPS;可運用的GPU記憶體容量達到800 GB,並且擁有13 TB/s的GPU記憶體頻寬;伺服器配備ConnectX-8 SuperNIC Switch,針對多GPU的互連,可提供800 GB/s的總頻寬。

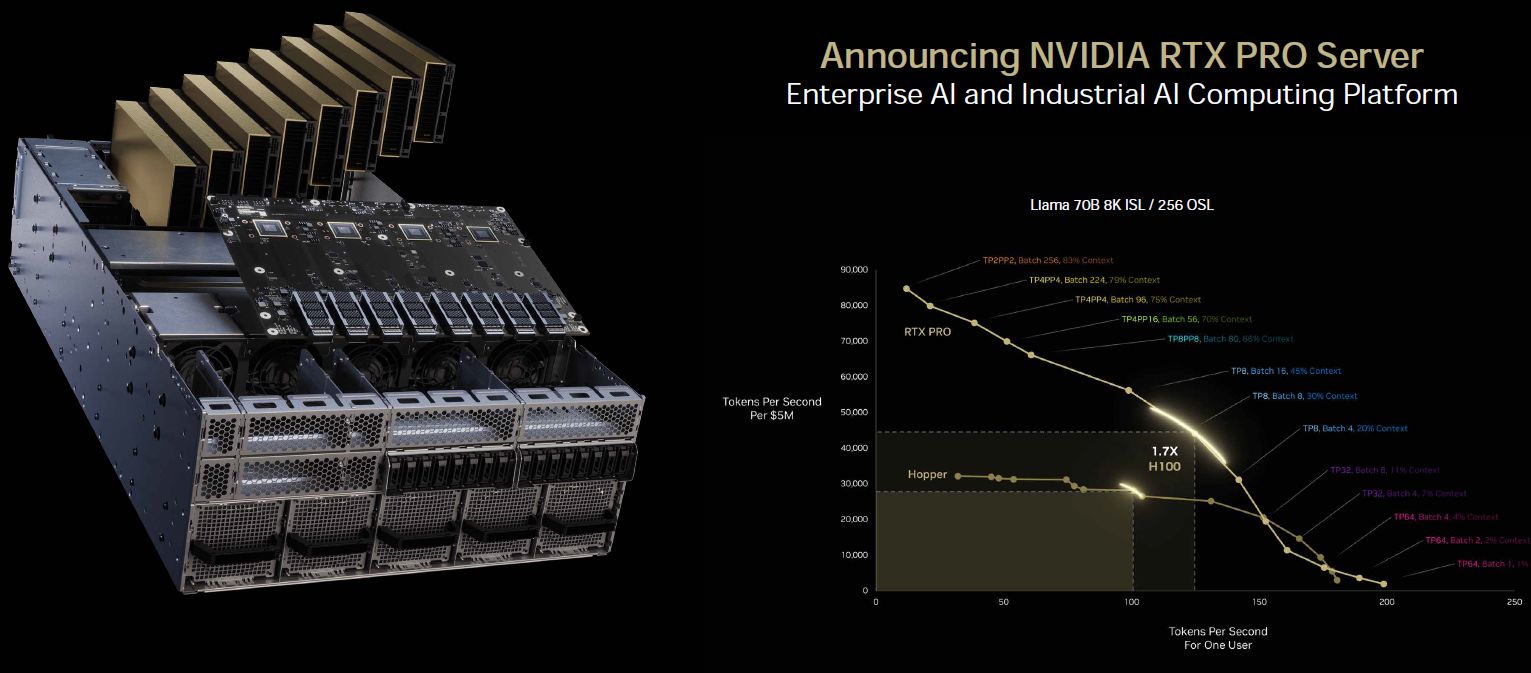
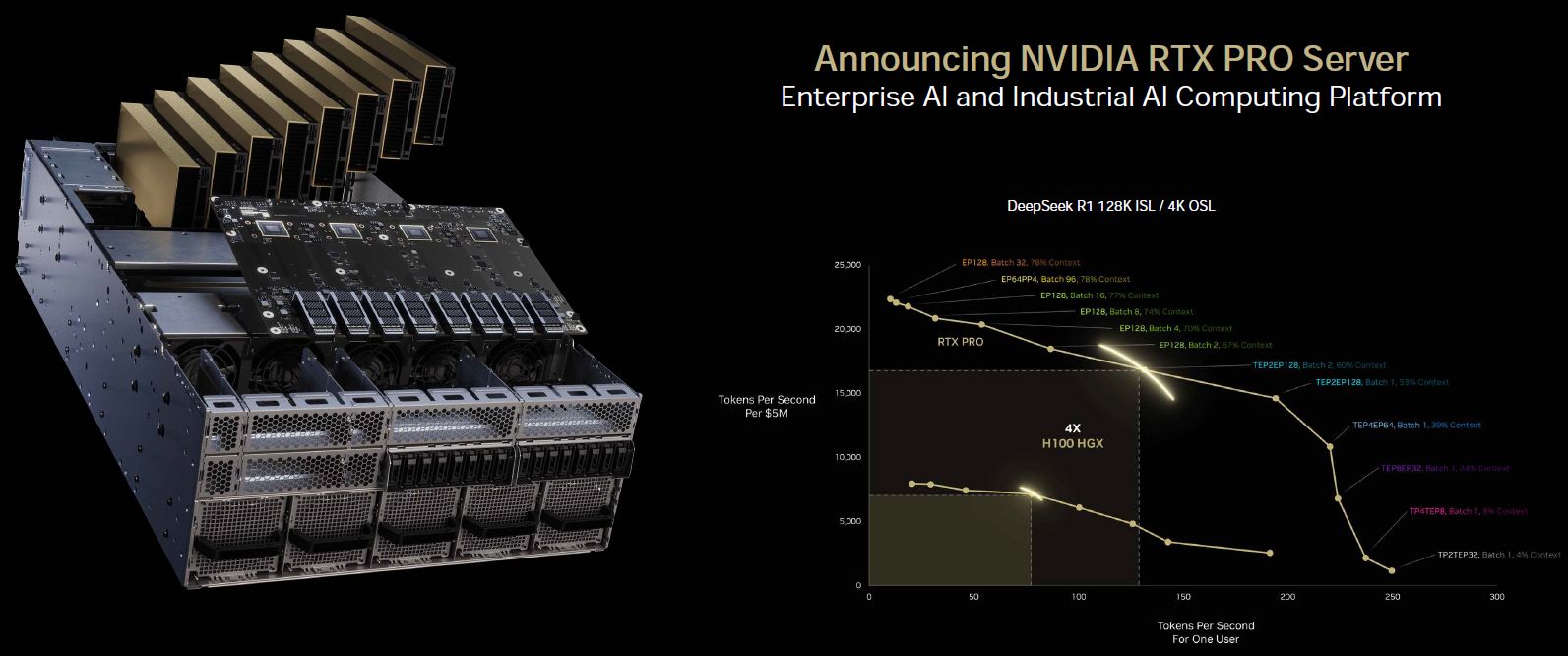
而在每秒產生的符元(Token)數量上,Nvidia也秀出耗費每5百萬美元與單一使用者這兩種情境對應的效能走勢。採用Llama 70B模型時,RTX Pro Server最高可達到H100伺服器的1.7倍;採用DeepSeek R1模型時,RTX Pro Server可達到H100伺服器的4倍。
7月初與Nvidia關係密切的AI運算服務供應商CoreWeave,宣布搭配RTX Pro 6000 BSE的執行個體正式上線,成為第一家採用這款伺服器級GPU暨提供運算服務的雲端平臺,每個執行個體配備2個英特爾第五代Xeon Scalable處理器、8個RTX Pro 6000 BSE GPU,以及多個BlueField-3資料處理器,他們也提及幾項效能突破的特色,例如:LLM推論效能提升至5.6倍(Lllama 3 70B模型),文字生成影片的速度提升至3.5倍,FP4運算效能為3.8 PFLOPS。
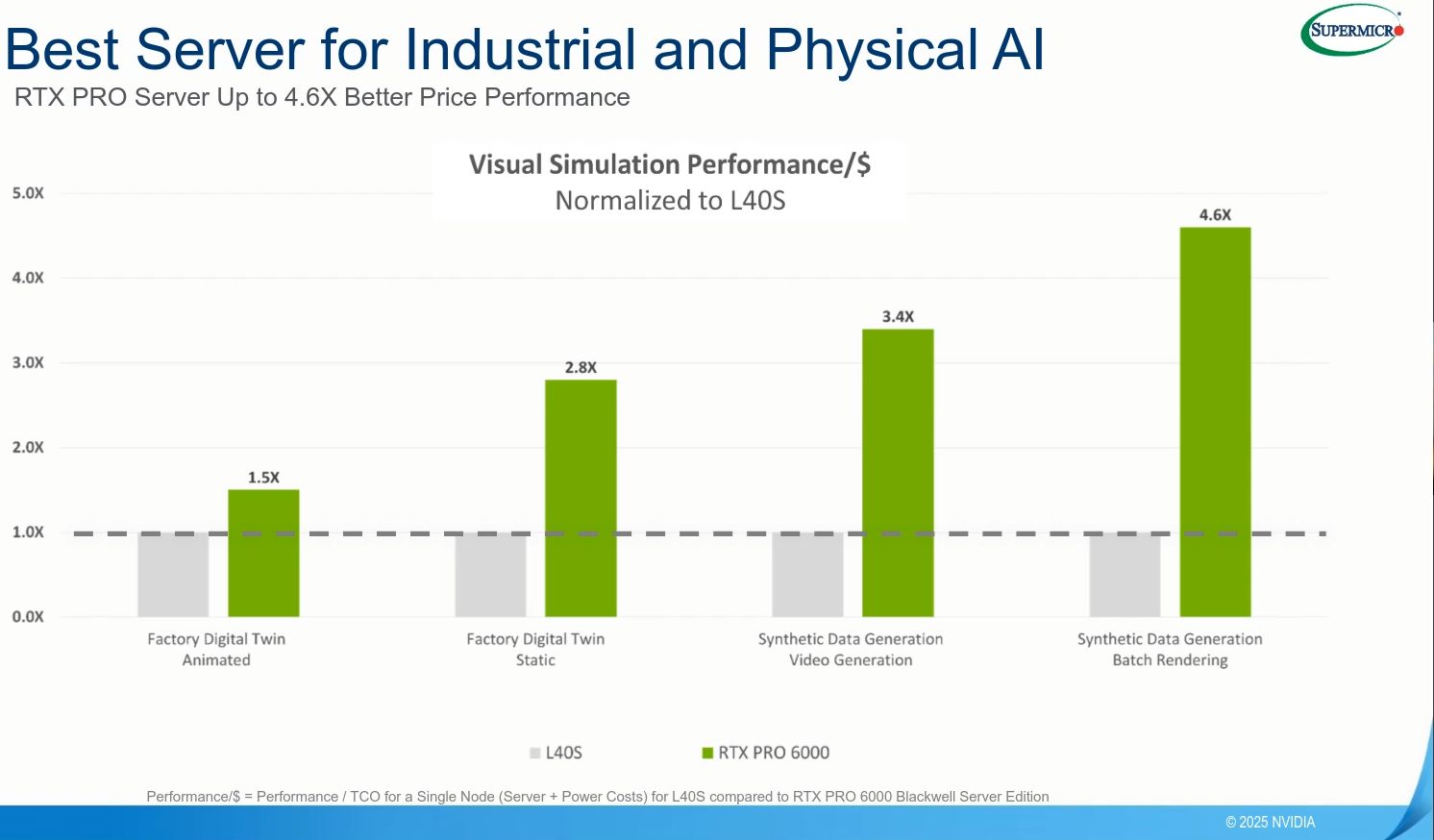
幾週後,在Supermicro的線上研討會上,Nvidia資深產品行銷經理Anthony Larijani針對RTX Pro 6000 BSE,也揭露更多效能改善幅度的比較圖表,涵蓋圖形處理、工業與物理AI、企業高效能運算、企業AI等應用。
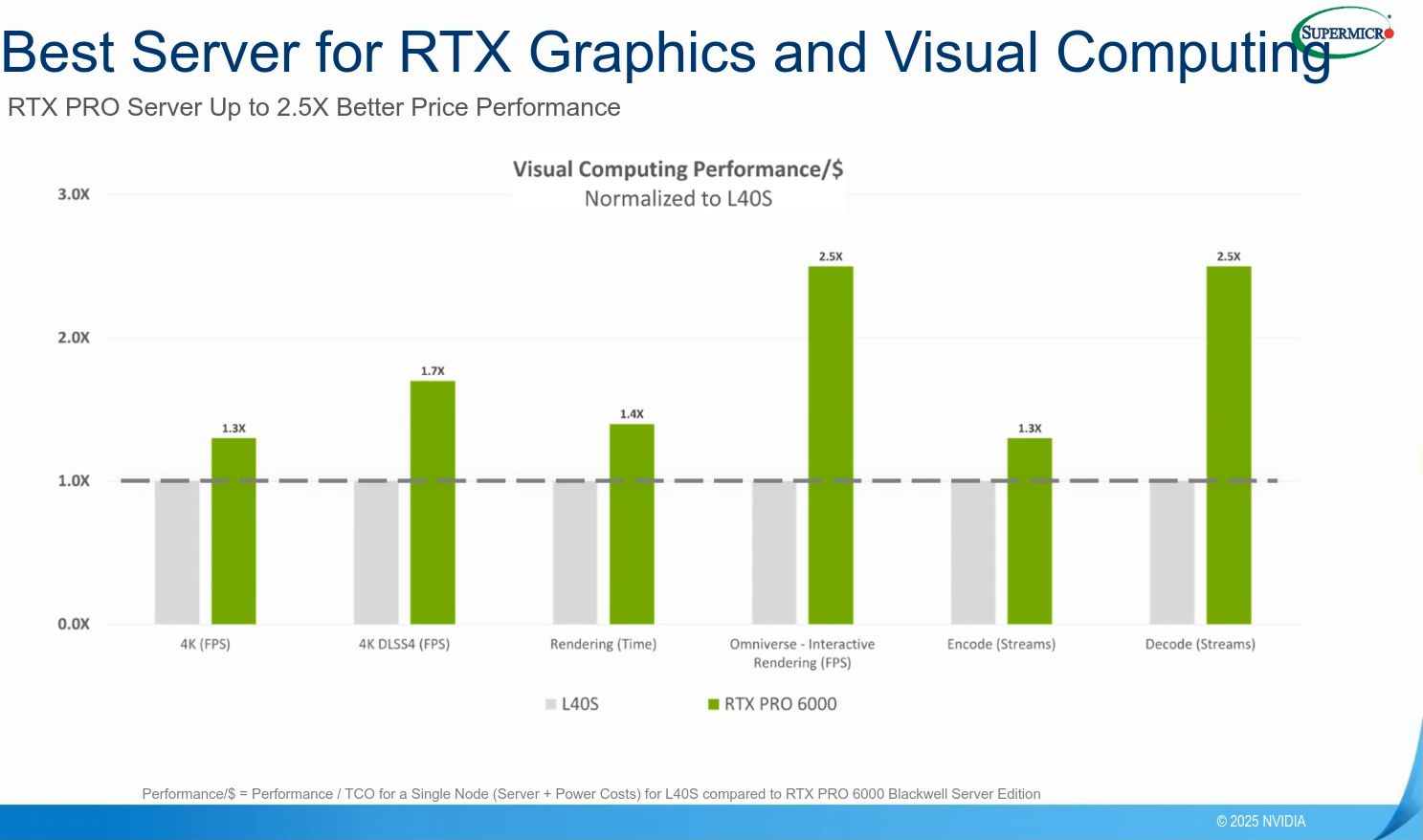
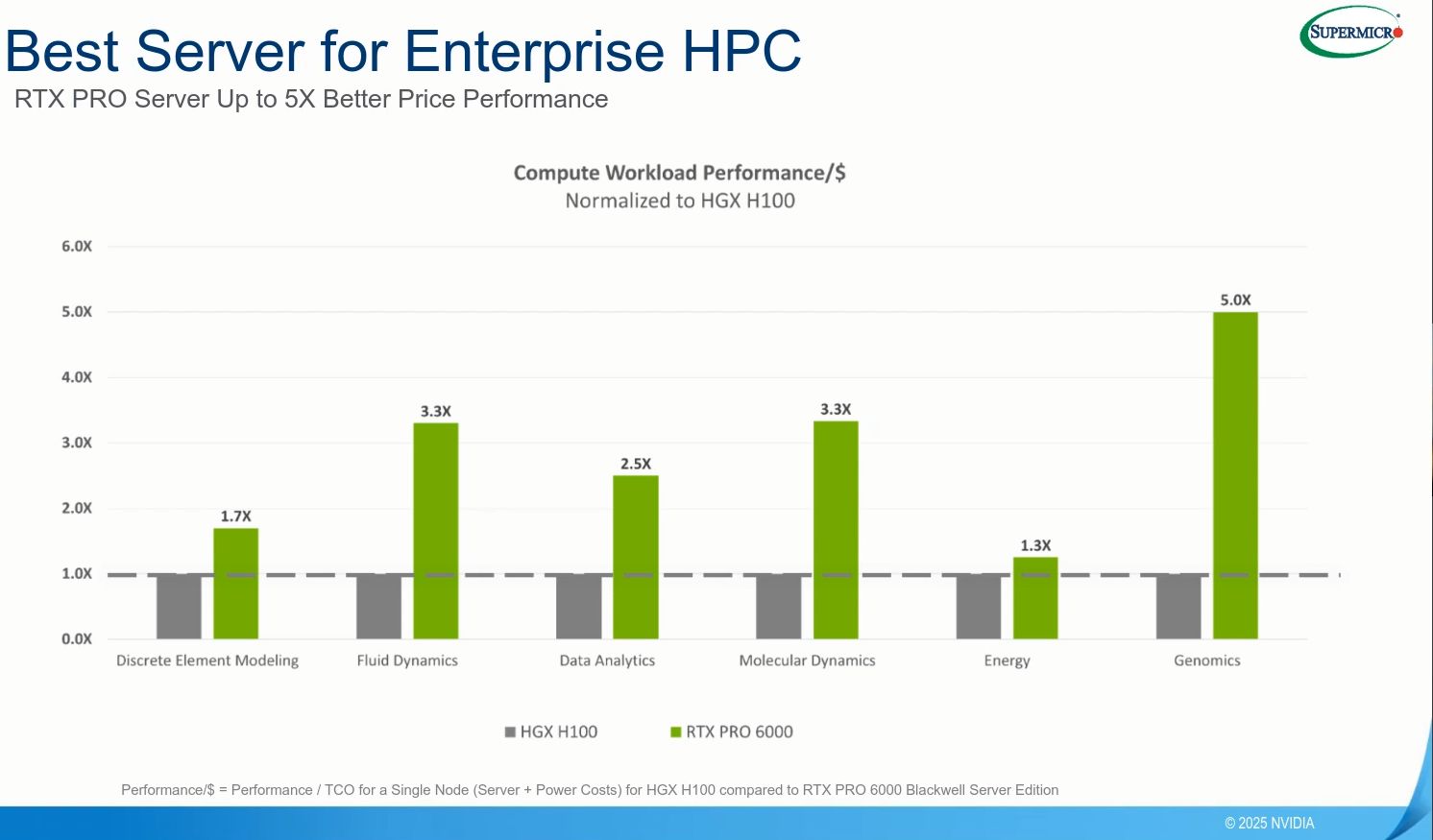
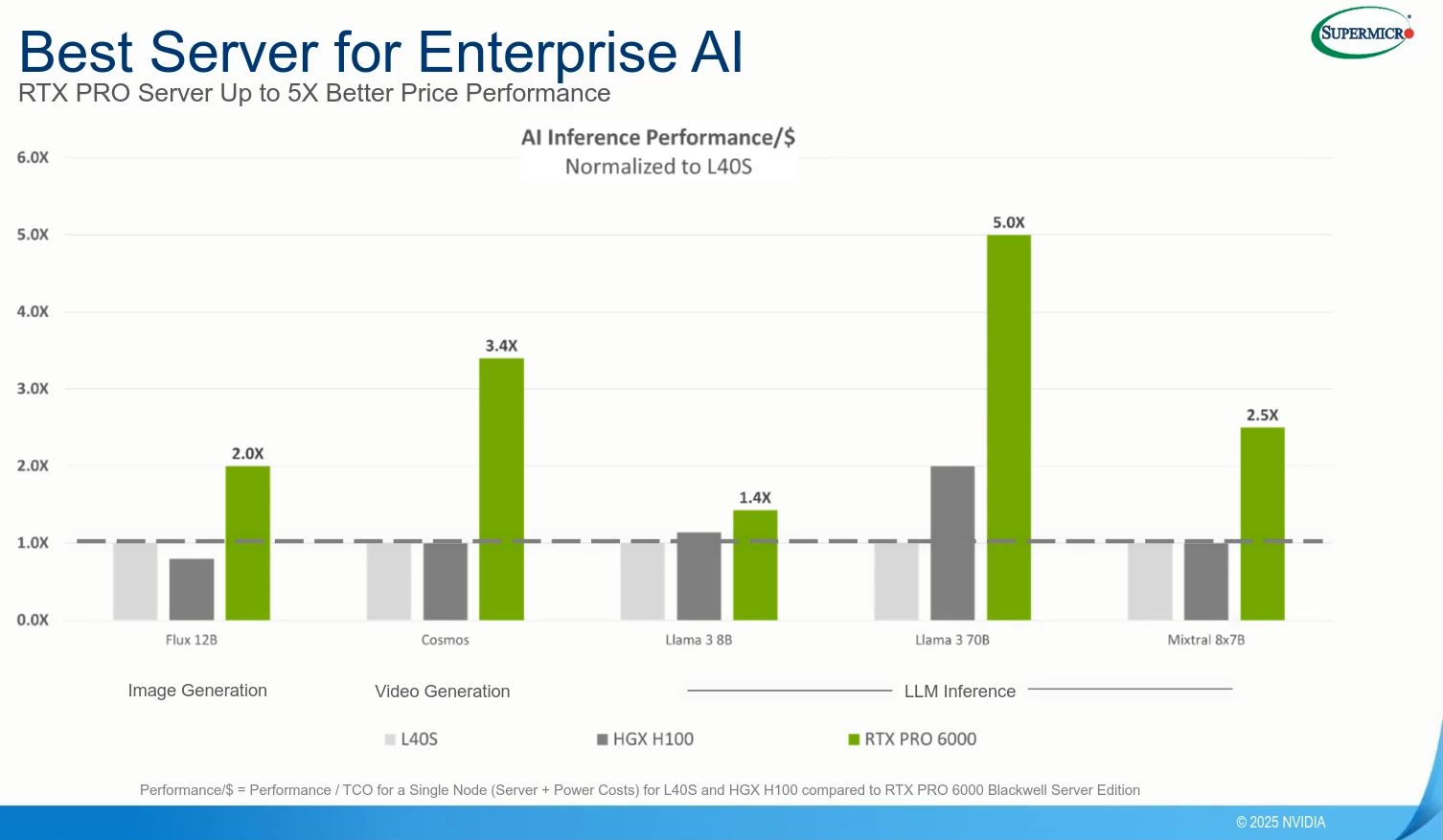
在8月初介紹vGPU軟體第19版推出的部落格文章,Nvidia揭露更多的效能改善資訊。例如,同樣以L40S為比較基準,RTX Pro 6000 BSE用於Lllama 3 70B模型,效能增長可達到5.6倍,用於自家Omniverse的著色處理效能是3.5倍,用於Autodesk Arnold的著色處理效能是1.9倍,用於模擬的效能提升至2倍(Siemens UFX、Dassault Abaqus)。
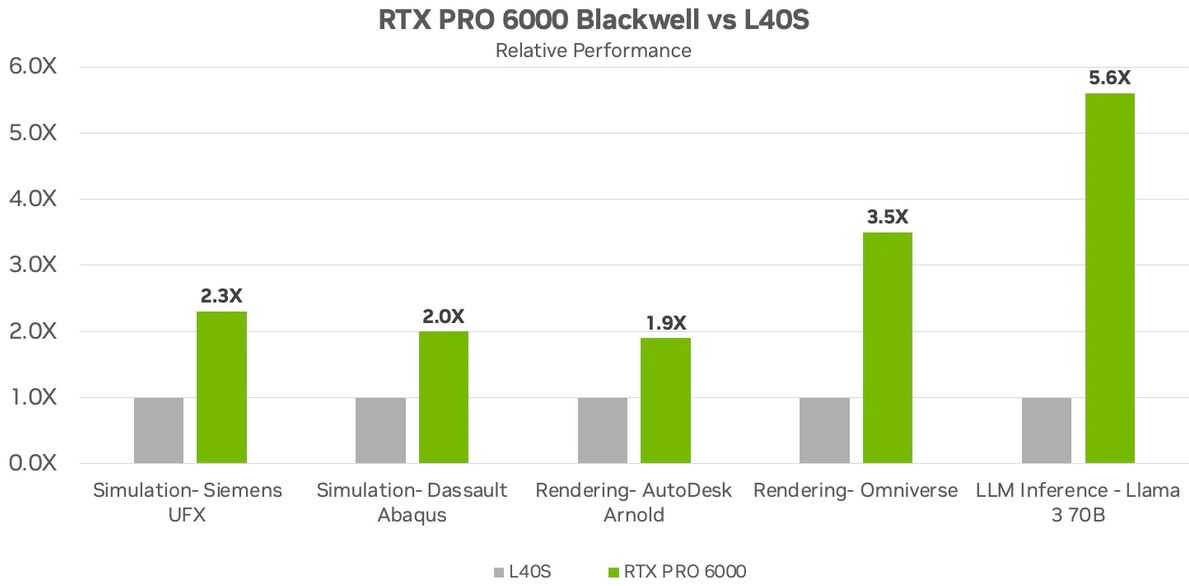
針對RTX Pro 6000 BSE內部而言,Nvidia也在新釋出的技術規格文件與8月11日發布的新聞稿,點出個別元件革新後的效能提升,呼應先前預告的資訊。
首先是這款GPU採用第五代Tensor核心與第二代Transformer引擎(支援Hopper架構的FP8 Transformer Engine,以及第二代的FP8 Transformer Engine),而且由於第五代Tensor核心支援FP4的運算精度,可加快AI模型處理、減少記憶體用量,相較於前一代GPU,AI推論的效能可提高至6倍。而在執行採用Llama Nemotron Super這類AI推理模型的AI代理,承擔複雜任務的自動化處理時,以單個GPU而言,對上既有支援FP8浮點運算格式的H100為比較基準時,RTX Pro 6000 Blackwell由於支援Nvidia新創設的浮點運算格式NVFP4,可獲得3倍的性價比優勢。
第二個特點是導入第四代RT核心,圖像擬真的著色處理效能增至4倍,可讓光線與三角形相交的速度提升1倍,而且搭配新支援的RTX Mega Geometry技術之後,光線追蹤三角形的繪製數量達到100倍以上,用戶可以創造逼真、精確度與物理環境一致的場景,以及身歷其境的3D設計。
針對工廠數位雙生、機器人模擬,以及大規模合成資料產生的工作流程,相較於採用L40S的系統,Nvidia表示,RTX Pro Server可提供4倍的速度。
而在能源使用效率方面,對比於單純採用CPU的2U伺服器系統,同樣面對資料分析、模擬、影片處理、圖形著色等工作負載時,Nvidia強調RTX Pro Server可提供45倍的效能、18倍的能源使用效率,以及更低的總持有成本。
支援MIG與vGPU技術,提供實體與虛擬等兩種多GPU應用
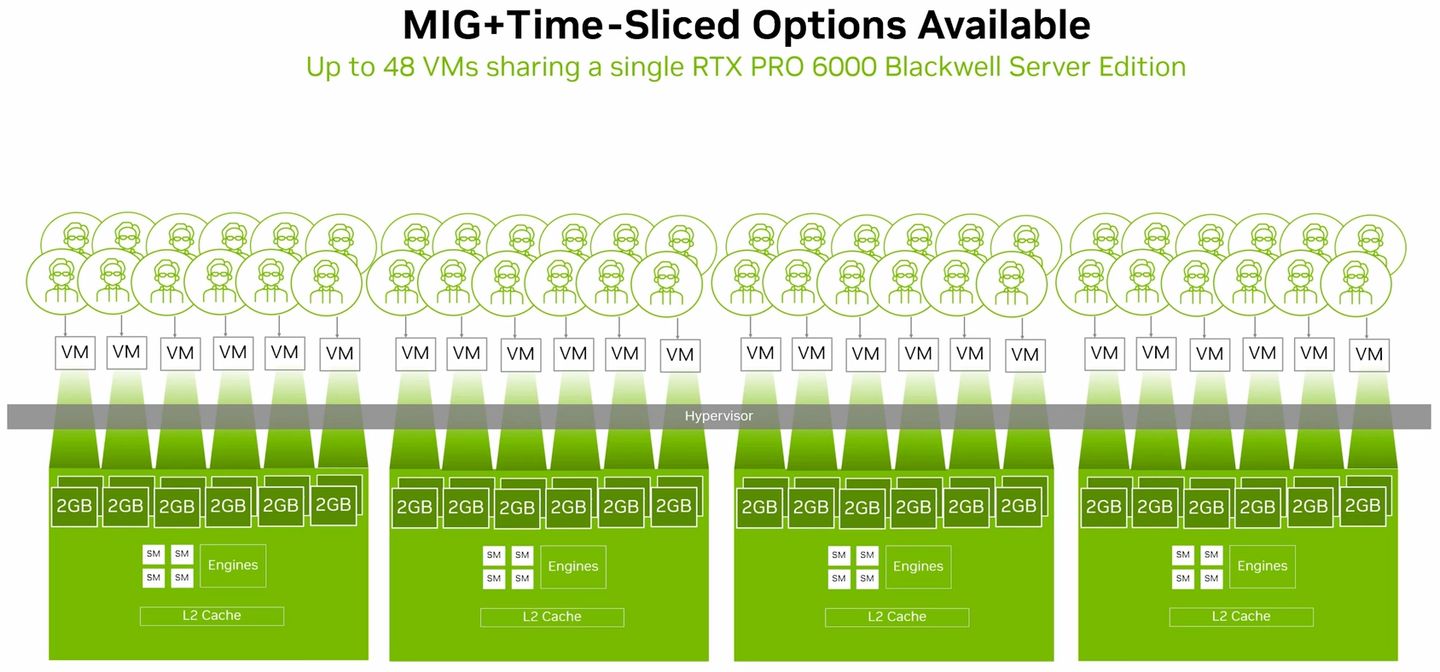
值得注意的是,Nvidia稍早推出的RTX Pro Blackwell系列GPU,當中的6000、5000,均支援GPU多執行個體(MIG),8月初Nvidia更強調,RTX Pro 6000 Blackwell系列是第一批支援MIG、專為加速圖形與運算工作負載的GPU產品。
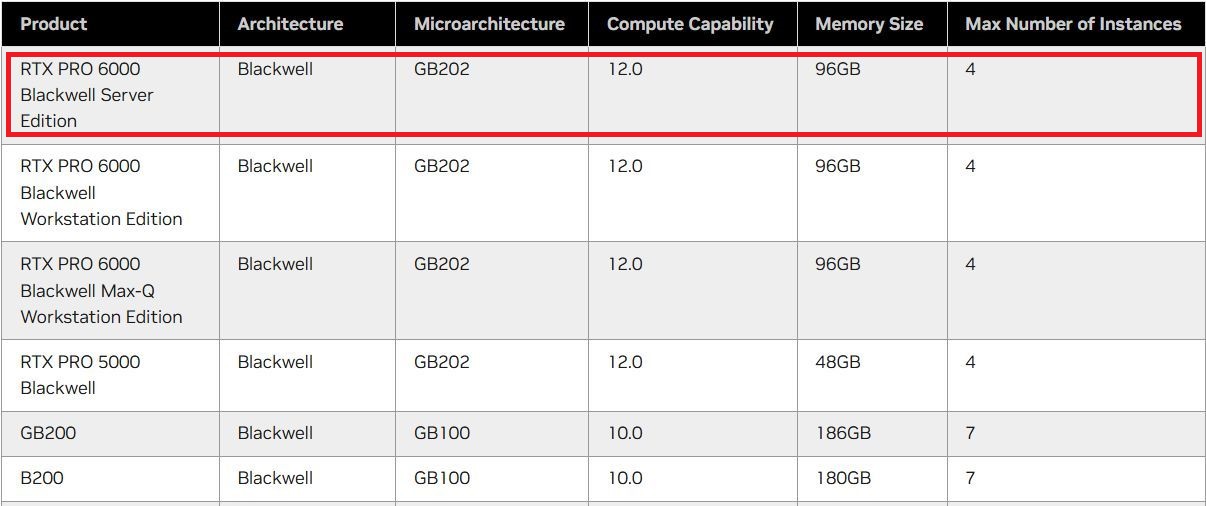
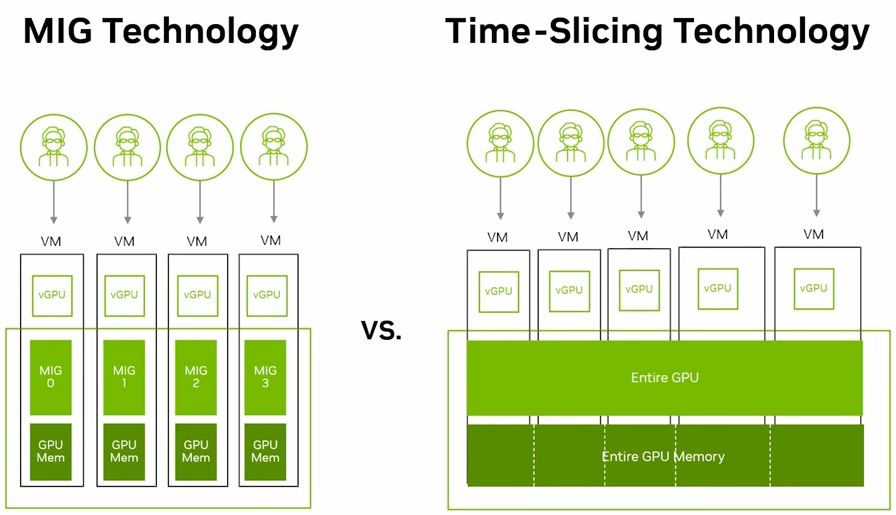
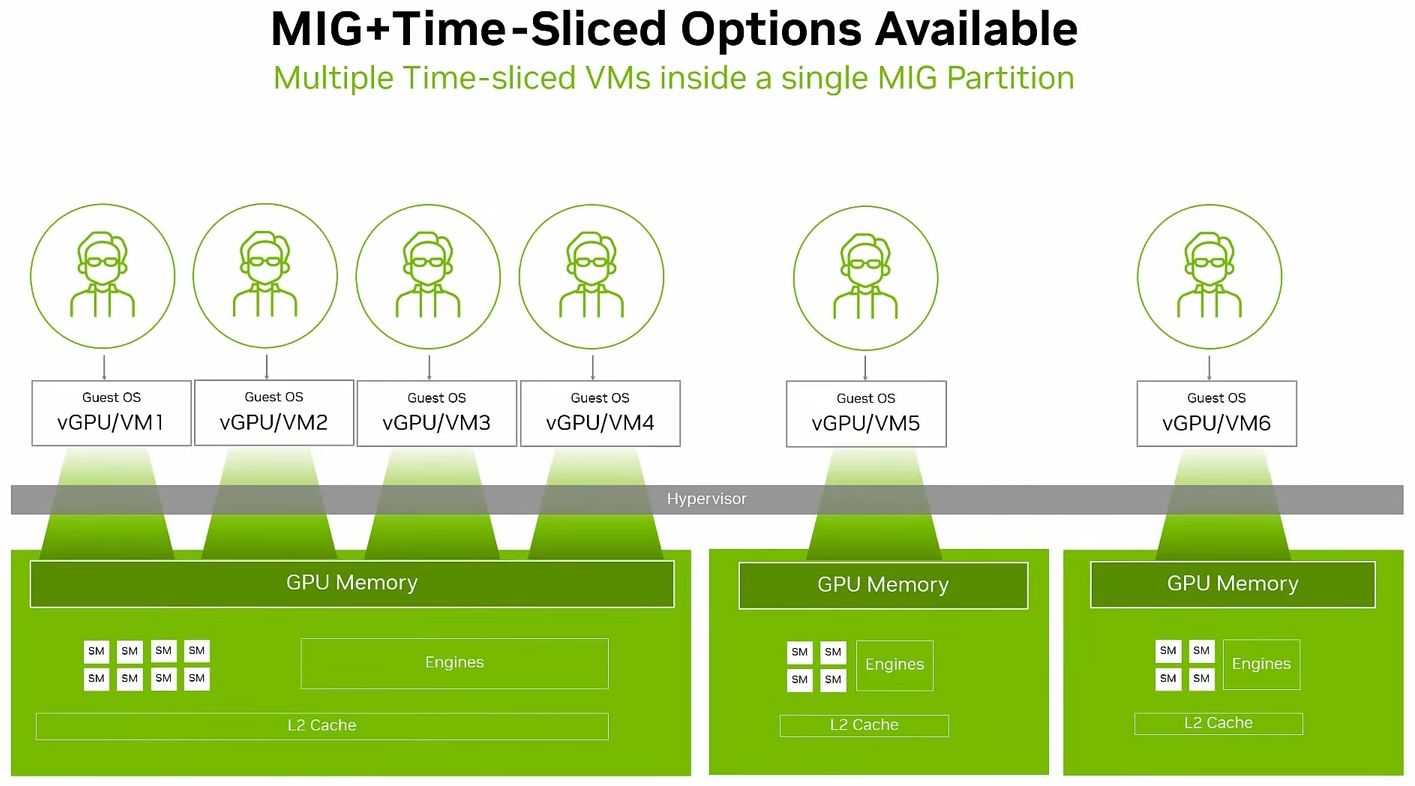
基於MIG的硬體分割機制,用戶可將單張RTX Pro 6000 BSE,區分為多個彼此隔離運作的GPU執行個體,各自擁有記憶體、快取、運算引擎,以及串流多處理器(Streaming Multiprocessors,SM),確保執行在不同MIG當中的個別工作負載,都能獲得一定的服務品質(QoS),不會因為其他工作負載的處理而遭到擾亂、甚至被迫中斷運作等影響。
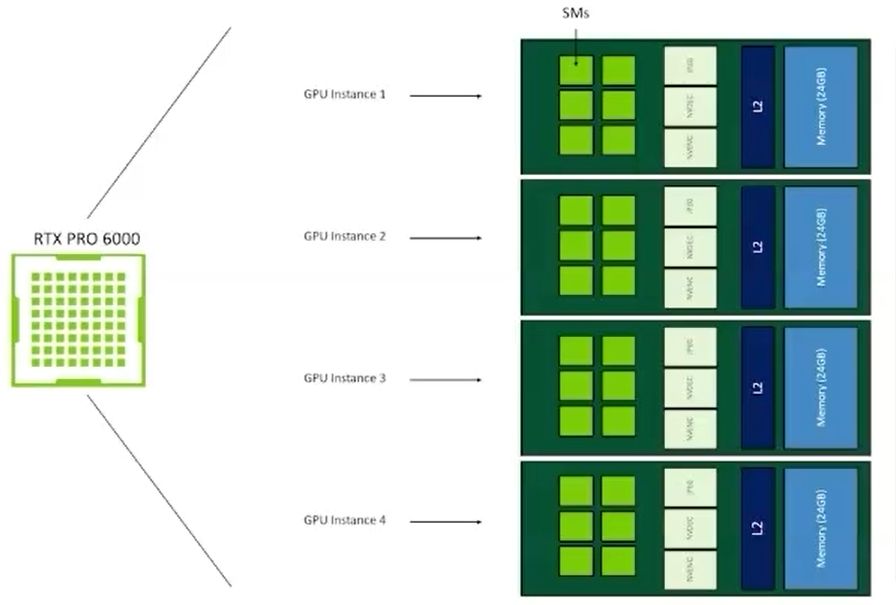
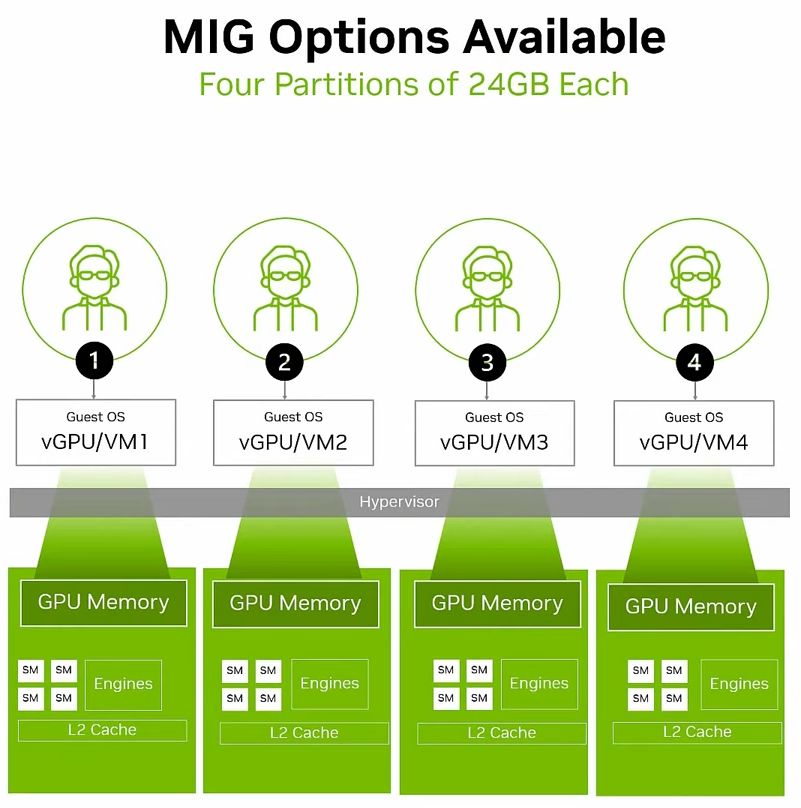
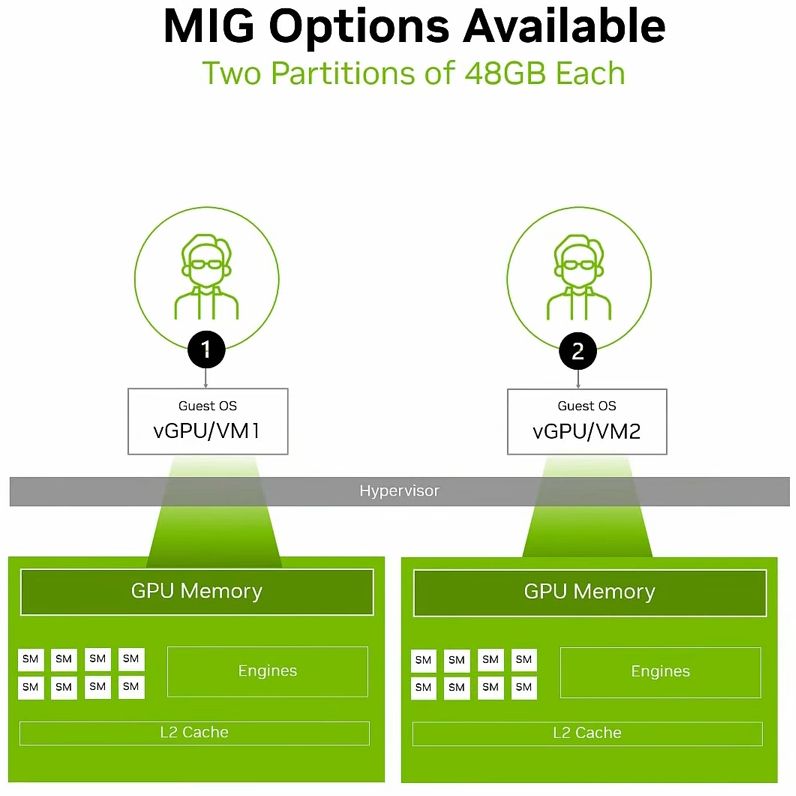
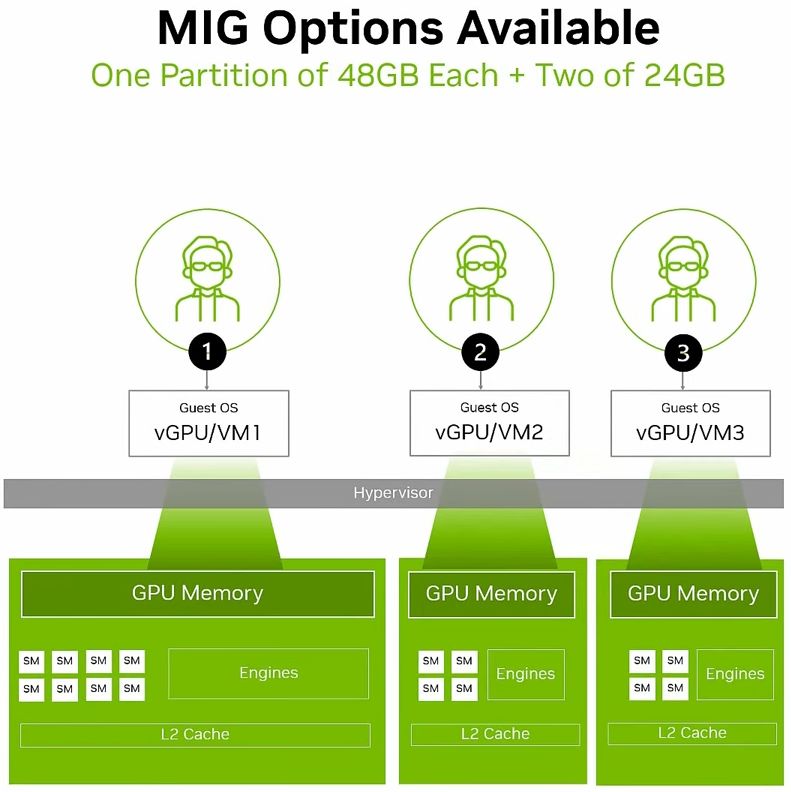
除此之外,若啟動MIG的GPU搭配vGPU軟體提供的分時共用機制(time-sliced)之後,用戶可在每一個GPU執行個體當中,建立多租戶服務架構,提供更大程度的執行規模擴充能力,實現高度整合的GPU基礎架構,促使單一GPU能支援更多元的工作負載執行。
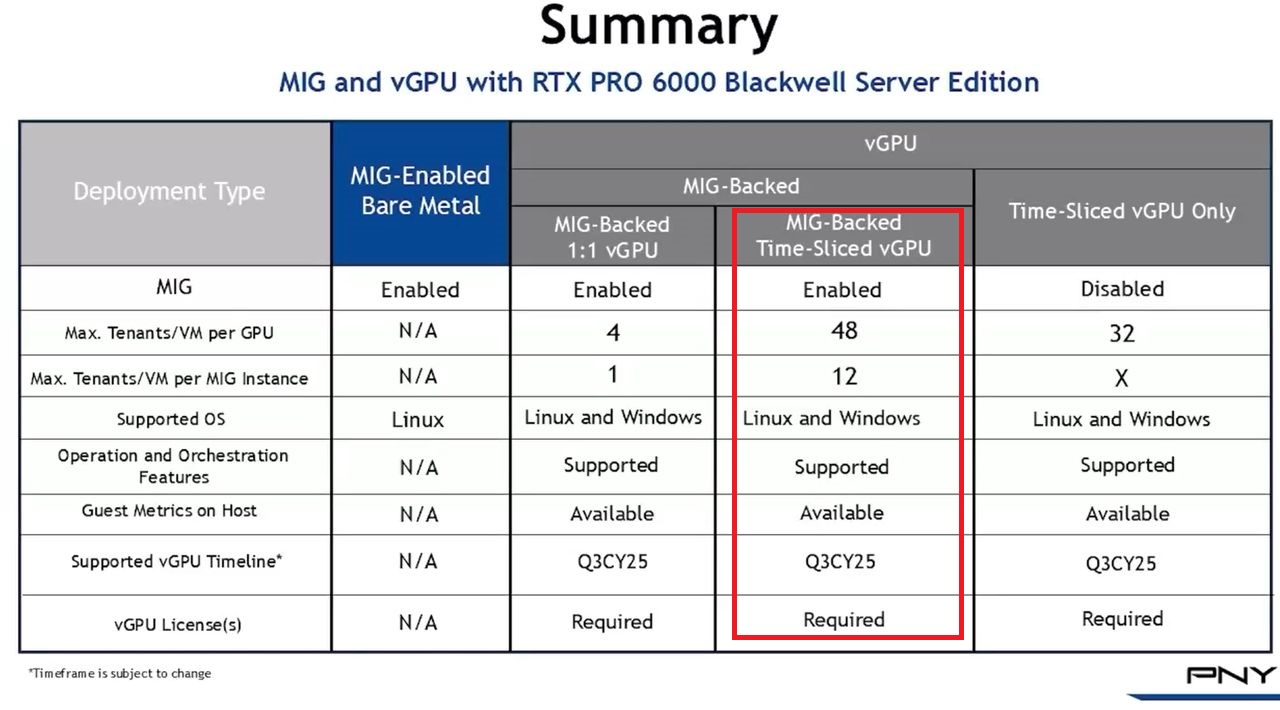
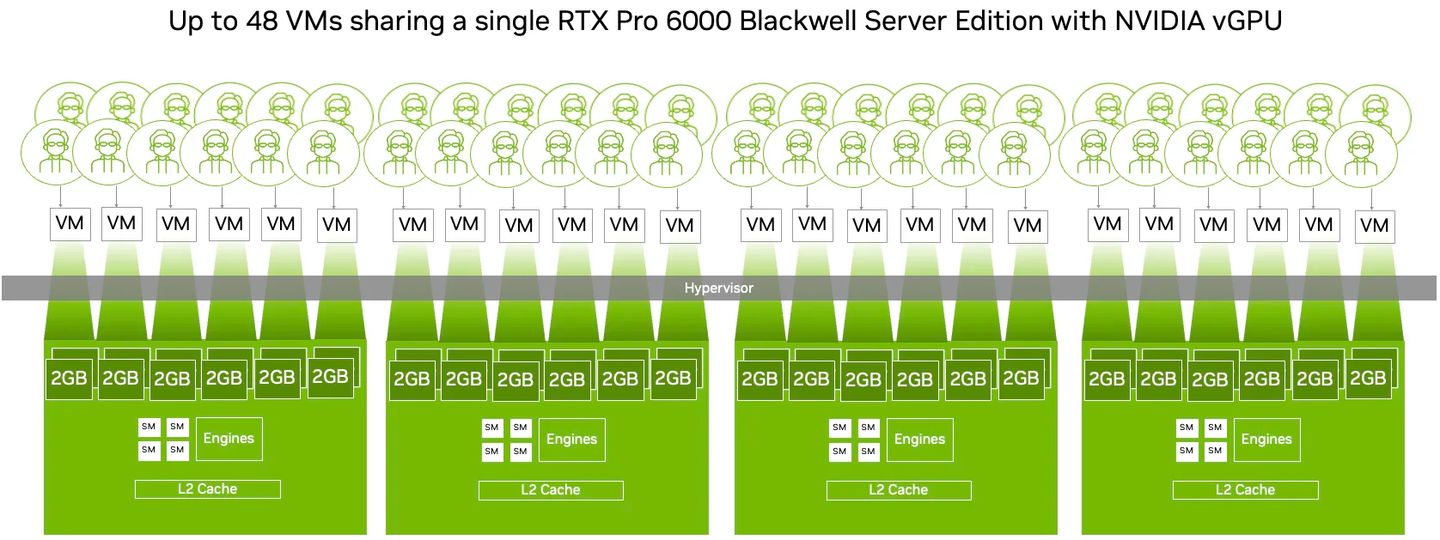
Nvidia表示,當RTX Pro Blackwell系列GPU啟用MIG功能,並且搭配vGPU 19.0軟體,能在單張GPU加速卡當中,最多支撐48臺配置GPU資源的虛擬機器同時運作——分成4個GPU執行個體,每個GPU個體可支撐12臺配置分時共用GPU資源的虛擬機器。有了這樣的使用彈性,企業的虛擬化基礎架構可用於多種工作負載,像是業務運作、視訊串流、圖形渲染、產品設計、AI開發。
產品資訊
Nvidia RTX Pro 6000 Blackwell Server Edition
●原廠:Nvidia
●建議售價:廠商未提供
●外形:雙槽,長10.5吋高4.4吋
●GPU架構:Blackwell
●CUDA處理核心數量:24,064個
●Tensor核心數量:752個(第五代Tensor核心)
●RT核心數量:188個(第四代RT核心)
●內建記憶體容量:96 GB GDDR7
●記憶體頻寬:1,597 GB/s
●連接介面:PCIe 5.0 x16
●支援NVLink:否
●單精度運算效能:120 TFLOPS
●RT核心效能:355 TFLOPS
●AI運算效能(FP4):4 PFLOPS
●視訊連接埠:2.1版DisplayPort規格,4個
●視訊處理引擎:4個NVENC(第9代)、4個NVDEC(第6代)
●多執行個體GPU(MIG):4個24 GB記憶體或2個48 GB記憶體或1個48 GB記憶體+2個24 GB記憶體
●耗電量:600瓦
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
