
Nvidia has taken a major leap in the development of multilingual speech AI, unveiling Granary, the largest open-source speech dataset for European languages, and two state-of-the-art models: Canary-1b-v2 and Parakeet-tdt-0.6b-v3. This release sets a new standard for accessible, high-quality resources in automatic speech recognition (ASR) and speech translation (AST), especially for underrepresented European languages.
Granary: The Foundation of Multilingual Speech AI
Granary is a massive, multilingual corpus developed in collaboration with Carnegie Mellon University and Fondazione Bruno Kessler. It delivers around one million hours of audio, with 650,000 hours for speech recognition and 350,000 for speech translation. The dataset covers 25 European languages—representing nearly all official EU languages, plus Russian and Ukrainian—with a critical focus on languages with limited annotated data, such as Croatian, Estonian, and Maltese.
Key features:
- Largest open-source speech dataset for 25 European languages.Pseudo-labeling pipeline: Unlabeled public audio data is processed using Nvidia NeMo’s Speech Data Processor, which adds structure and enhances quality, reducing the need for resource-intensive manual annotation.Supports both ASR and AST: Designed for transcription and translation tasks.Open access: Available to the global developer community for flexible, production-scale model training.
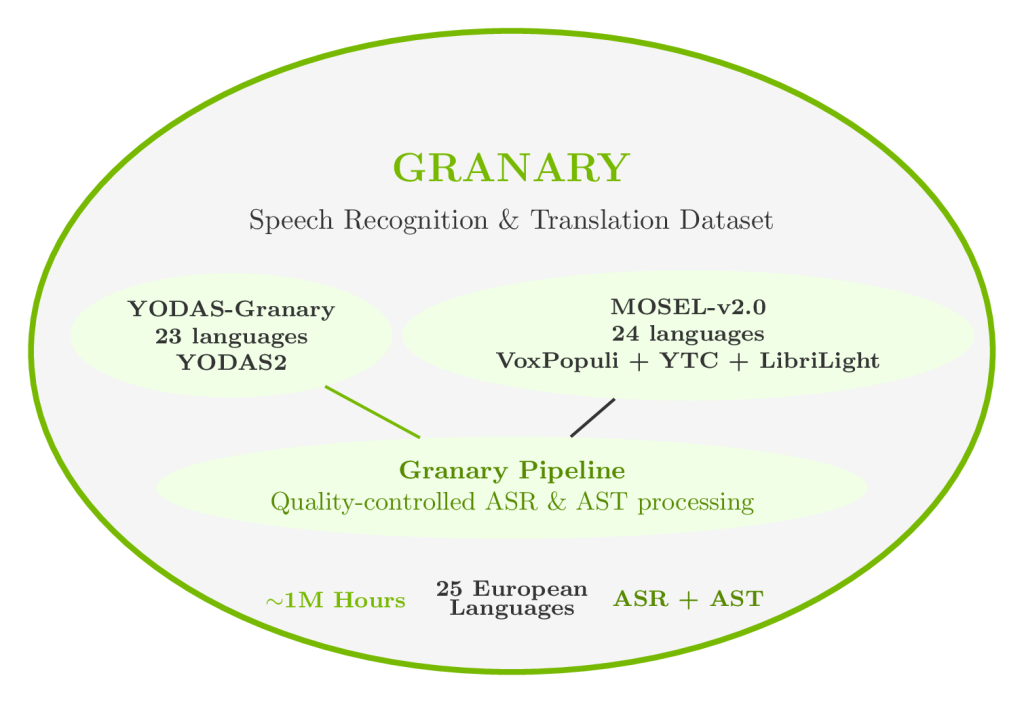
By leveraging clean, high-quality data, Granary enables significantly faster model convergence. Research demonstrates that developers need half as much Granary data to reach target accuracies compared to competing datasets, making it especially valuable for resource-constrained languages and rapid prototyping.
Canary-1b-v2: Multilingual ASR + Translation (En  24 Languages)
24 Languages)
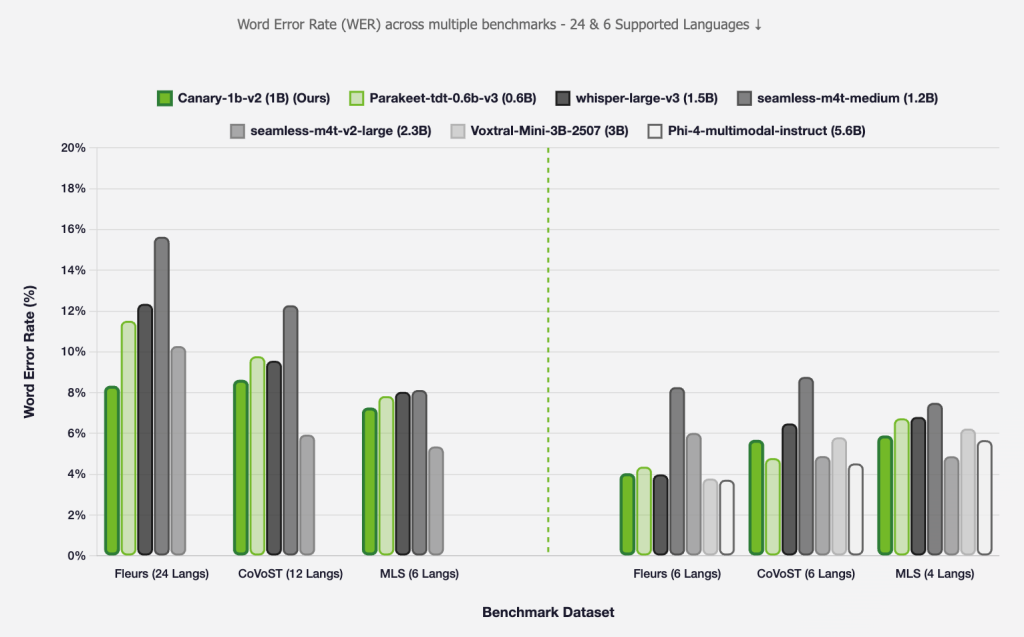
Canary-1b-v2 is a billion-parameter Encoder-Decoder model trained on Granary, delivering high-quality transcription and translation between English and 24 supported European languages.
It’s architected for accuracy and multitask capabilities:
- Languages supported: 25 European languages, doubling Canary’s coverage from 4.State-of-the-art performance: Comparable accuracy to models three times larger, but up to 10× faster inference.Multitask capability: Robust across both ASR and AST tasks.Features: Automatic punctuation, capitalization, word and segment-level timestamps—even timestamped translated outputs.Architecture: FastConformer Encoder with Transformer Decoder; unified vocabulary for all languages via SentencePiece tokenizer.Robustness: Maintains strong performance under noisy conditions and resists output hallucinations.
Evaluation highlights:
- ASR Word Error Rate (WER): 7.15% (AMI dataset), 10.82% (LibriSpeech Clean).AST COMET Scores: 79.3 (X→English), 84.56 (English→X).Deployment: Available under CC BY 4.0 license; optimized for Nvidia GPU-accelerated systems, enabling fast training and inference for scalable production use.
Parakeet-tdt-0.6b-v3: Real-Time Multilingual ASR
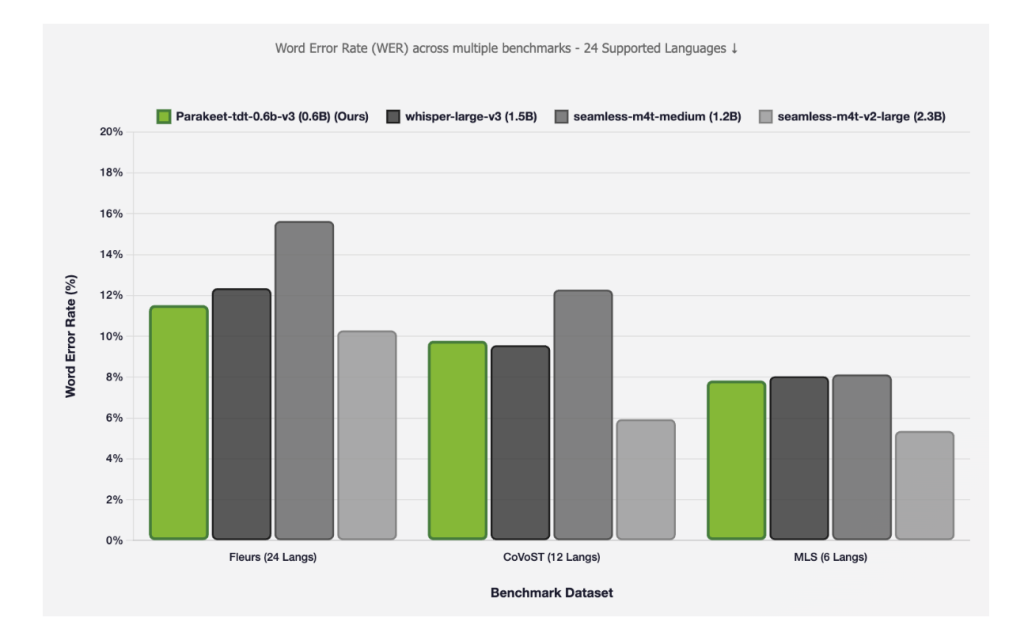
Parakeet-tdt-0.6b-v3 is a 600-million-parameter multilingual ASR model designed for high-throughput or large-volume transcription in all 25 supported languages. It extends the Parakeet family (previously English-centric) to full European coverage.
- Automatic language detection: Transcribes input audio without needing extra prompts.Real-time capability: Efficiently transcribes up to 24-minute audio segments in a single inference pass.Fast, scalable, and commercial-ready: Prioritizes low latency, batch processing, and accurate outputs, with word-level timestamps, punctuation, and capitalization.Robustness: Reliable even on complex content (numbers, lyrics) and challenging audio conditions.
Impact on Speech AI Development
Nvidia’s Granary dataset and model suite accelerate the democratization of speech AI for Europe, enabling scalable development of:
- Multilingual chatbotsCustomer service voice agentsNear-real-time translation services
Developers, researchers, and businesses can now build inclusive, high-quality applications supporting linguistic diversity, with open access to these super cool models and datasets
Check out the Granary, NVIDIA Canary-1b-v2 and NVIDIA Parakeet-tdt-0.6b-v3. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post NVIDIA AI Just Released the Largest Open-Source Speech AI Dataset and State-of-the-Art Models for European Languages appeared first on MarkTechPost.
