
面对对抗攻击,具身智能体除了被动防范,也能主动出击!
在人类视觉系统启发下,清华朱军团队在TPMAI 2025中提出了强化学习驱动的主动防御框架REIN-EAD。
该框架让智能体也能学会“看第二眼”,提升对抗场景下的感知鲁棒性。

对抗攻击已成为视觉感知系统安全性和可靠性的重大威胁,这类攻击通过在三维物理场景中放置精心设计的扰动物体(如对抗补丁和三维对抗物体)来操纵深度神经网络的预测结果。
在人脸识别和自动驾驶等安全关键领域,此类漏洞的后果尤为严重,错误预测可能严重损害系统安全性。
然而,现有防御方法多依赖攻击先验,通过对抗训练或输入净化等手段实现对有害画面的“被动防守”,忽略了与环境交互可获得的丰富信息,遇上未知或自适应攻击时效果迅速衰减。
相比之下,人类视觉系统更为灵活,可以通过主动探索与纠错,自然地降低瞬时感知的不确定性。
类似的,REIN-EAD的核心在于利用环境交互与策略探索,对目标进行连续观察和循环预测,在优化即时准确率的同时兼顾长期预测熵,缓解对抗攻击带来的幻觉。
特别地,该框架引入了基于不确定性的奖励塑形机制,无需依赖可微分环境,即可实现高效策略更新,支持物理环境下的鲁棒训练。
实验验证表明,REIN-EAD在多个任务中显著降低了攻击成功率,同时保持了模型标准精度,在面对未知攻击与自适应攻击时同样表现出色,展现出强大的泛化能力。
主要贡献
(1)提出REIN-EAD模型,融合感知与策略模块来模拟运动视觉机制
论文设计了一种结合感知模块与策略模块的主动防御框架REIN-EAD,借鉴人类大脑支持运动视觉的工作方式,使模型能够在动态环境中持续观察、探索并重构其对场景的理解。
REIN-EAD通过整合当前与历史观测,构建具有时间一致性的鲁棒环境表征,从而提升系统对潜在威胁的识别与适应能力。
(2)引入基于累计信息探索的强化学习方法以优化主动策略
为提升REIN-EAD的策略学习能力,论文提出一种基于累计信息探索的强化学习算法,通过引导式密集奖励优化多步探索路径,引入不确定性感知机制以驱动信息性探索。
该方法强化了时间上的一致性探索行为,并通过强化学习范式消除了对可微环境建模的依赖,使系统能够主动识别潜在高风险区域并动态调整行为策略,显著提升了观测数据的有效性与系统安全性。
(3)提出离线对抗补丁近似技术(OAPA),实现效率高、泛化强的防御能力
针对3D环境下对抗训练计算开销巨大的挑战,论文提出OAPA技术,通过对抗补丁流形的离线近似,构建无需依赖对手信息的普适防御机制。
OAPA大幅降低了训练成本,同时具备在未知或自适应攻击场景下的稳健防御能力,为三维环境下的主动防御提供了一种实用且高效的解决方案。
(4)在多任务与多环境上取得优越性能,展现优越的泛化与适应能力
论文在多个标准对抗测试环境与任务中进行了系统评估,实验结果表明:REIN-EAD在抵抗多种未知和自适应攻击下表现出显著优于现有被动防御方法的性能。
其卓越的泛化能力和对复杂现实世界场景的适应性,进一步验证了本文方法在安全关键系统中的应用潜力。
方法与理论
REIN-EAD框架
REIN-EAD是一种模拟人类在动态环境中主动感知与反应能力的对抗防御框架,该框架(如下图所示)通过感知模块与策略模块的协同,使系统具备了与环境主动交互、迭代采集信息并增强自身鲁棒性的能力。
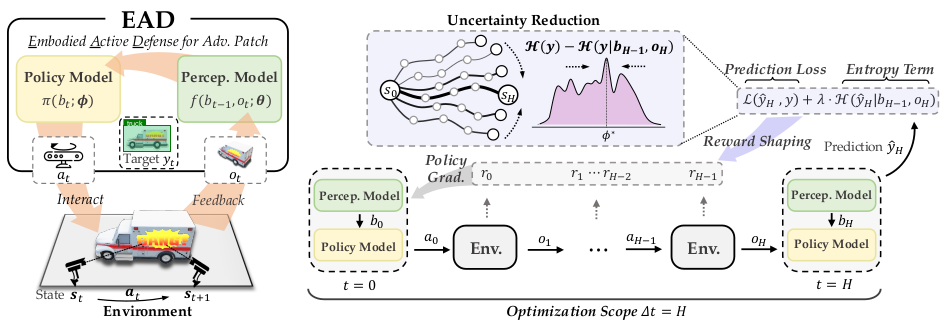
△图1:REIN-EAD框架
REIN-EAD由两个核心的循环神经模块组成,灵感来源于支撑人类活跃视觉系统的大脑结构:
通过感知模型与策略模型的闭环联动,REIN-EAD实现了对抗防御过程中的“感知—决策—行动”一体化:
在每一时刻选择长期最优的交互动作,并根据环境反馈不断修正其内部表示,使得模型能从多步交互中获取最具信息量的观测反馈。
这种主动防御机制突破了传统静态防御策略在鲁棒性与适应性方面的瓶颈,显著提升了系统面对未知攻击时的识别与响应能力。
基于累计信息探索的强化学习策略
论文扩展了部分可观察马尔可夫决策过程(POMDP)框架以正式描述REIN-EAD框架与环境的相互作用。
场景下的交互过程用表示。
这里分别表示状态、动作和观测空间。场景下的状态转移符合马尔可夫性质。
由于环境的部分可观察性,智能体不能直接访问状态,而是接收从观察函数采样的观察值。
REIN-EAD的预测过程是多步条件下的连续观测和循环预测,感知与动作循环依赖——感知指导了动作,而动作又获得更好的感知。
直观上,可以通过RNN Style的训练方式优化多步条件下的EAD框架,然而,该过程涉及沿时间步反传梯度,团队证明了这种做法的缺陷。
首先,论文通过理论分析证明RNN Style的训练方式本质上是一种贪婪探索策略:
这种贪婪探索策略可能导致EAD采用局部最优策略,难以从多步探索中持续获益。
△图2:贪婪信息探索可能导致重复探索
第二,沿时间步反传梯度要求状态转移函数和观察函数必须具有可微分性,该性质在现实环境和常用的仿真引擎(如UE)中都是不满足的。
最后,在多步条件下反传梯度需要构建非常长的梯度链条,这可能导致梯度消失/爆炸,并带来巨大的显存开销。
为了解决贪婪策略的次优性,提高REIN-EAD的性能,论文引入了累积信息探索的定义:
以及多步累积交互目标:
其中, 是探索轨迹, 表示时间步的预测损失,作为正则化项,表示时间步的标签预测熵,阻止智能体做出具有对抗特征的高熵预测。
多步累积交互目标包含最小化预测损失的目标项和惩罚高熵预测的正则项,通过一系列与环境的相互作用,在步的范围内优化策略,最小化目标变量的长期不确定性,而不是只专注于单步。
该目标通过一系列行动和观察来最小化目标变量的不确定性,结合预测损失和熵正则化项,鼓励智能体达到信息丰富且鲁棒的认知状态,从而对对抗扰动具有鲁棒性。
论文中对所提出的多步累积交互目标与累积信息探索的定义一致性进行了证明,并进一步分析了累积信息策略相比贪婪信息策略的性能优越性。
为了进一步消除对可微分训练环境的依赖并降低梯度优化的不稳定性,论文中提出了一种结合了面向不确定性的奖励塑形的强化策略学习方法。
面向不确定性的奖励塑形在每一步提供密集的奖励,促使策略寻求新的观察结果作为来自环境的反馈,解决了多步累积交互目标中的只能在回合结束时获得奖励的稀疏性问题,减轻了探索和利用分配的挑战,促进了更快的收敛和更有效的学习。
论文中还证明了这种奖励塑形与多步累积交互目标的等价性(细节参见论文)。
对于强化学习主干,论文中采用了学习效率和收敛稳定性较好的近端策略优化(PPO),通过限制策略的大小来实现稳定的策略更新。

离线对抗补丁近似技术
论文中还提出了离线对抗补丁近似(OAPA),以解决3D环境中对抗训练的计算开销。
对抗补丁的计算通常需要内部最大化迭代,这不仅计算昂贵,还可能导致防御对特定攻击策略过拟合,从而阻碍模型在未知攻击中推广的能力。
为了在保持对抗不可知性的同时提高采样效率,论文在训练REIN-EAD模型之前引入了OAPA,通过预先对视觉主干进行投影梯度上升得到一组替代的补丁作为对抗补丁流形的离线近似。
实验结果表明,执行这种离线近似最大化允许REIN-EAD模型学习紧凑而富有表现力的对抗特征,使其能够有效地防御未知攻击。
此外,由于这种最大化过程只在训练前发生一次,因此大大提高了训练效率,使其与传统对抗训练相比更具有竞争力。
实验与结果
论文中在人脸识别、3D物体分类、目标检测多个任务上使用一系列像素空间、隐变量空间下的白盒、黑盒、自适应攻击方法,结果表明在三个任务上REIN-EAD的效果都优于SAC、PZ、DOA等基线防御(表1,3,4)。
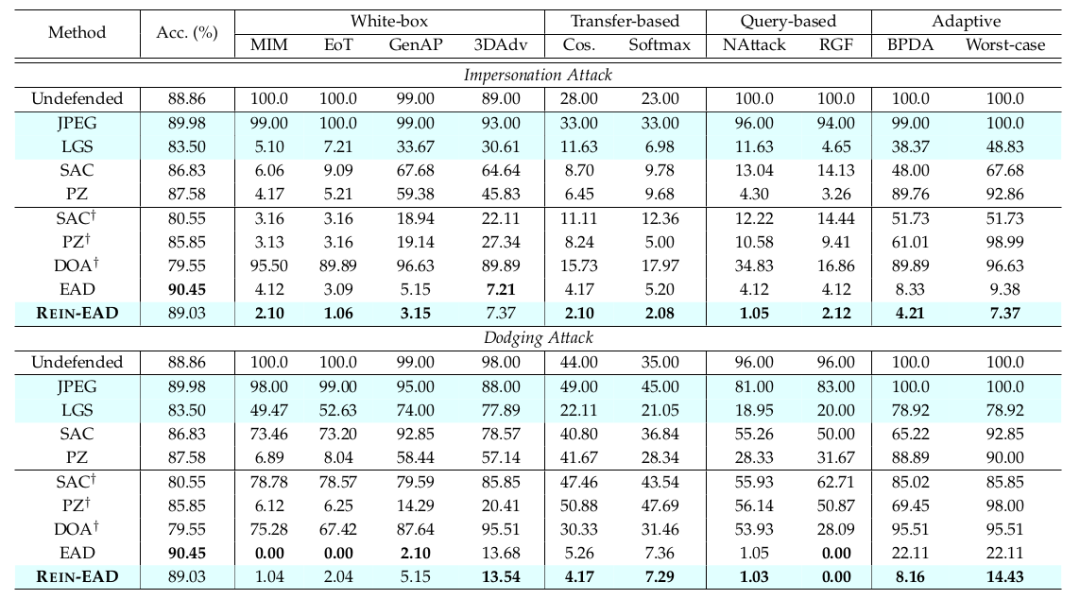
△表1:人脸识别任务中逃逸和扮演两种攻击目标下的结果
人脸识别任务中,通过REIN-EAD框架改进IResNet50模型,使用EG3D可微分渲染器实现CelebA-3D数据集的可微分三维重建,以对累计探索的REIN-EAD与ICLR 2024 工作中贪婪探索的EAD进行公平比较。
通过对各个组件的消融,分别证明了累计信息探索和OAPA的有效性(表1,2,图3)。
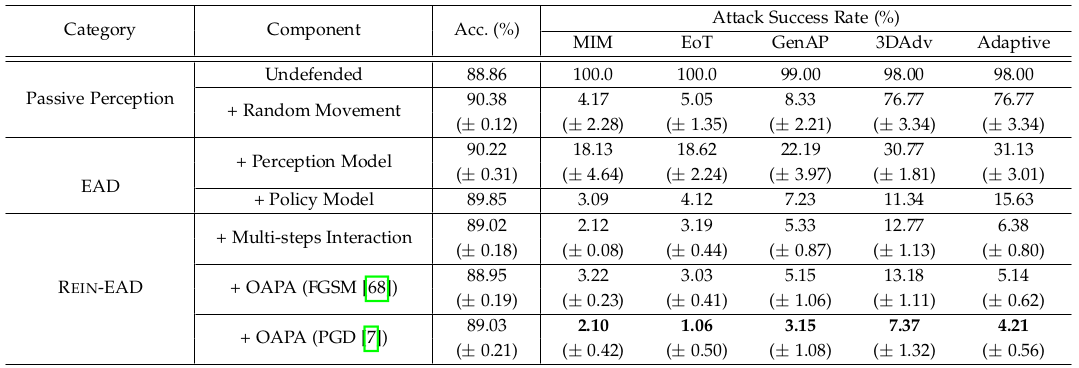
△表2:人脸识别任务中的REIN-EAD模块消融结果

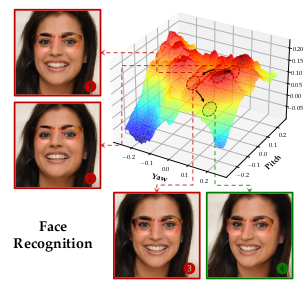
△图3:人脸识别实验的REIN-EAD可视化示例
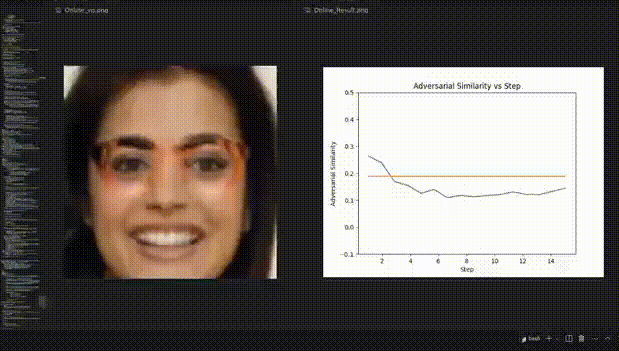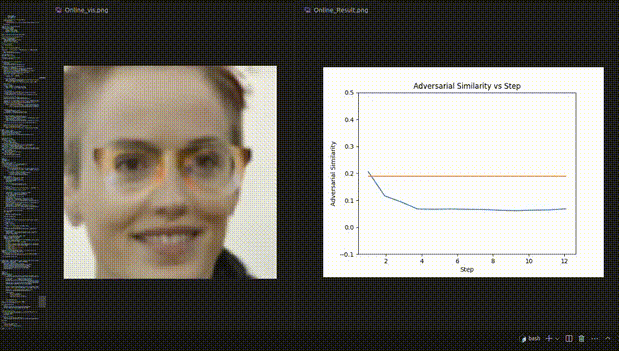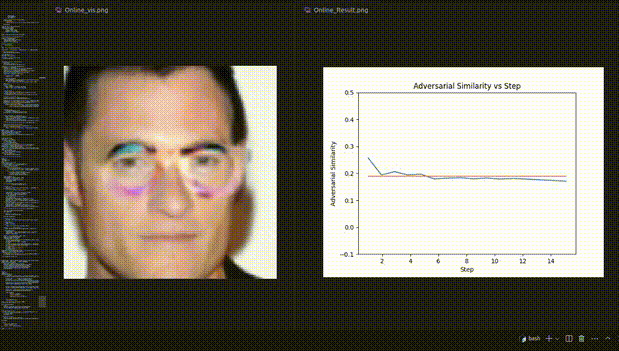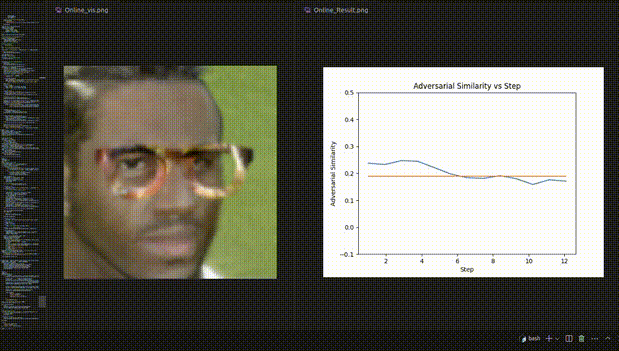
△人脸识别实验的可视化动态示例
在物体分类任务中,通过REIN-EAD框架改进Swin-S模型,使用Pytorch3D对OmniObject3D三维扫描物体数据集进行可微分渲染,以在三维环境下的图像分类任务上对REIN-EAD的通用性进行评估(表3)。
尽管在早期步骤中REIN-EAD可能被对抗补丁欺骗做出错误预测,但在随后的步骤REIN-EAD进行了正确的自我修正(图4)。
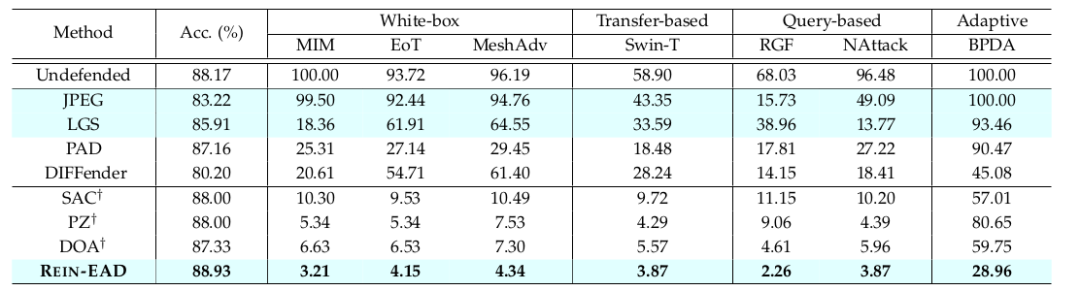
△表3:物体分类实验结果
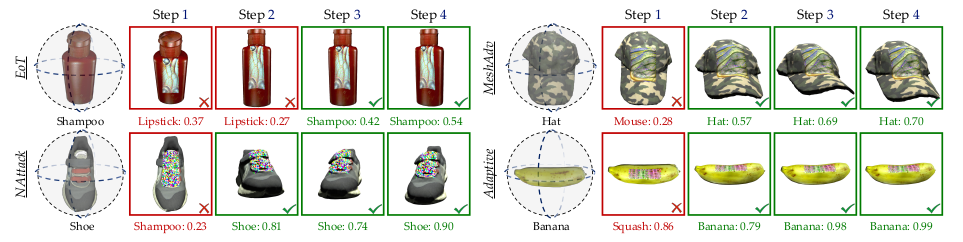
△图4:物体分类实验的REIN-EAD可视化示例
目标检测任务中,通过REIN-EAD框架改进YOLO-v5模型,使用CARLA构建具有真实渲染观测的实验场景,进一步证明了REIN-EAD在复杂任务和现实场景的有效性(表4,图5)。
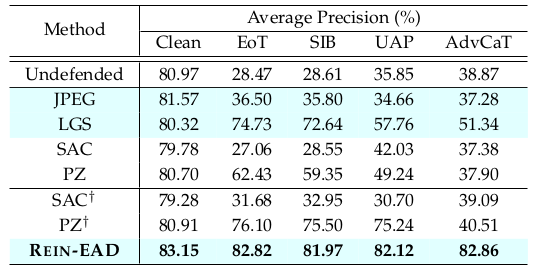
△表4:目标检测实验结果
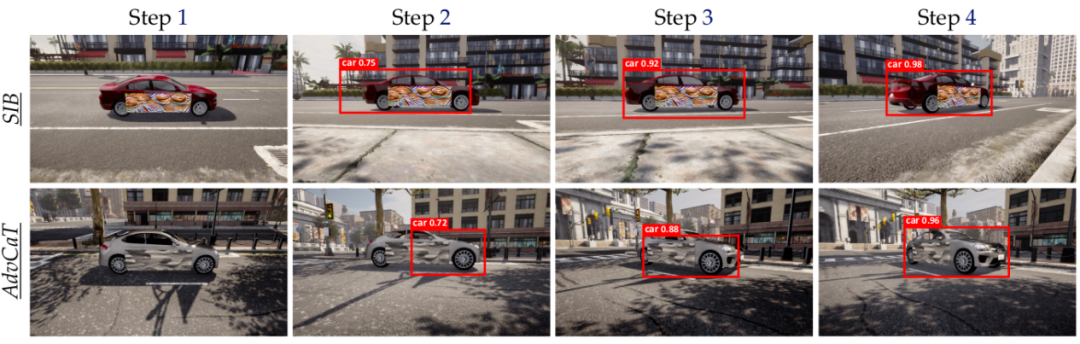
△图5:目标检测实验的REIN-EAD可视化示例

△目标检测实验的可视化动态示例
此外,论文中还对补丁大小、补丁形状、攻击强度等多个不同的攻击对手策略进行了补充实验,以全面的验证REIN-EAD面对未知攻击对手的泛化能力。
本文提出的REIN-EAD是一种新的主动防御框架,可以有效地减轻现实世界3D环境中的对抗补丁攻击。
REIN-EAD利用探索和与环境的交互来将环境信息语境化,并改进其对目标对象的理解。
它积累了多步相互作用的时间一致性,平衡了即时预测精度和长期熵最小化。
实验表明,REIN-EAD显著增强了鲁棒性和泛化性,在复杂任务中具有较强的适用性,为对抗防御提供了不同于被动防御技术的新研究视角。
论文:https://arxiv.org/abs/2507.18484
代码:https://github.com/thu-ml/EmbodiedActiveDefense
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
