
「如果在训练文本的大语言模型的时候,加入 1 千万小时的语音数据会发生什么呢?」带着这个想法,李沐及其团队 Boson AI 经研究,正式发布了语音大模型「Higgs Audio V2」。
传统 TTS(文本转语音)系统往往为机械式的语音输出,缺乏情绪适应性与自然韵律,对于多角色对话需要进行人工分段处理,仅靠模型难以实现音色与角色的匹配。而 Higgs Audio V2 的出现,正是创新推出了传统 TTS 中很少见的功能,包括旁白时的自动韵律适应、多说话人对话生成能力、零样本克隆声音以及旋律哼唱、同时生成语音和背景音乐等,代表了音频 AI 能力的重大跃迁。
值得一提的是,在 EmergentTTS-Eval 上,该模型在「情绪」和「问题」类别上超过「gpt-4o-mini-tts」的胜率分别为 75.7% 和 55.7%,这反映出「情感化交互」成为该模型在音频领域迈出的关键一步。
目前,HyperAI 超神经官网已上线了「Higgs Audio V2:重新定义语音生成的表达能力」,快来试试吧~
在线使用:https://go.hyper.ai/Ty0CM
8 月 4 日-8 月 8 日,hyper.ai 官网更新速览:
* 优质公共数据集:10 个
* 优质教程精选:7 个
* 本周论文推荐: 5 篇
* 社区文章解读:5 篇
* 热门百科词条:5 条
* 8 月截稿顶会:2 个
访问官网:hyper.ai
1. STRIDE-QA-Mini 自动驾驶问答数据集
STRIDE-QA-Mini 是一个自动驾驶问答数据集,旨在用于研究自动驾驶场景中视觉语言模型(VLMs)的时空推理能力。该数据集包含 103,220 个问答对及 5,539 张图像样本。数据源自东京收集的真实行车记录仪镜头。
直接使用:https://go.hyper.ai/9DVTI
2. MathCaptcha10k 算数验证码图像数据集
MathCaptcha10K 是一个算数验证码图像数据集,旨在测试并训练验证码识别算法,尤其是在处理具有干扰背景和变形文本的验证码时。该数据集包含 10,000 个带标签样本和 11,766 个未标注文件样本,每个带标签样本包含算数验证码图像,图像中的精确字符及其整数答案。
直接使用:https://go.hyper.ai/QERJt

数据集示例
3. CoSyn-400K 多模态合成问答数据集
CoSyn-400K 是由宾夕法尼亚大学和 Allen Institute for Artificial 联合发布的一个多模态合成问答数据集,旨在为多模态模型训练提供高质量、可扩展的合成数据资源。该数据集包含超过 40 万条图像-文本问答对数据,支持视觉回答任务。
直接使用:https://go.hyper.ai/aNjiz
4. NonverbalTTS 非语言音频生成数据集
NonverbalTTS 是由 VK Lab 联合 Yandex 发布的一个非语言音频生成数据集,旨在推动表达性文本到音频(TTS)研究,支持模型生成包含情绪和非语言发声的自然语音。
直接使用:https://go.hyper.ai/y2a1e
5. GPT Image Edit-1.5M 图像生成数据集
GPT Image Edit-1.5M 是由加利福尼亚大学圣克鲁兹分校联合爱丁堡大学发布的一个图像生成数据集,旨在为图像编辑模型的训练与评估提供全面的多模态数据资源。该数据集包含超过 150 万个高质量三元组(指令、源图像、编辑后的图像)。
直接使用:https://go.hyper.ai/ohpmD

数据集示例
6. UniRef50 蛋白质序列数据集
UniRef50 蛋白质序列数据集来自 UniProt 知识库,通过迭代聚类从 UniParc 序列中筛选得出。迭代流程确保了 UniRef50 代表性序列高质量、非冗余且多样化的特性,为蛋白质语言模型提供了覆盖广泛的蛋白质序列空间。
直接使用:https://go.hyper.ai/EcUF5
7. Difference Aware Fairness 差异感知基准数据集
Difference Aware Fairness 是由斯坦福大学发布的一个差异感知基准数据集,旨在衡量模型在差异感知和情境感知方面的表现。相关论文成果发表于 ACL 2025 并获评最佳论文。
直接使用:https://go.hyper.ai/wwBos
8. T-Wix 俄罗斯 SFT 数据集
T-Wix 是一个 SFT 数据集,包含了 499,598 个俄语样本,旨在增强模型从解决算法和数学问题到对话、逻辑思维和推理模式的能力。
直接使用:https://go.hyper.ai/p0sgT
9. WebInstruct-verified 多领域推理数据集
WebInstruct-verified 是由滑铁卢大学和 Vector Institute 联合发布的一个多领域推理数据集,旨在增强 LLMs 在多样化领域的推理能力,同时保留其在数学领域的优势。该数据集包含约 23 万道推理问题,涵盖多种答案格式,包括选择题、数值表达式数据集的均衡领域分布。
直接使用:https://go.hyper.ai/oCgsZ
10. Finance-Instruct-500k 金融推理数据集
Finance-Instruct-500k 是一个金融推理数据集,旨在训练用于金融任务、推理和多轮对话的高级语言模型。该数据集包含超过 50 万条金融领域的高质量数据,涵盖金融问答、推理、情感分析、主题分类、多语言命名实体识别和对话式 AI 。
直接使用:https://go.hyper.ai/03UVH
1. Higgs Audio V2:重新定义语音生成的表达能力
Higgs Audio V2 是由李沐及其团队 Boson AI 发布的的语音大模型,在 Seed-TTS Eval 和 Emotional Speech Dataset(ESD)等传统 TTS 基准测试中获得了最先进的性能。该模型展示了以前系统中很少见的功能,包括旁白时的自动韵律适应、多语言自然多说话者对话的零样本生成等。
在线运行:https://go.hyper.ai/BqZJD
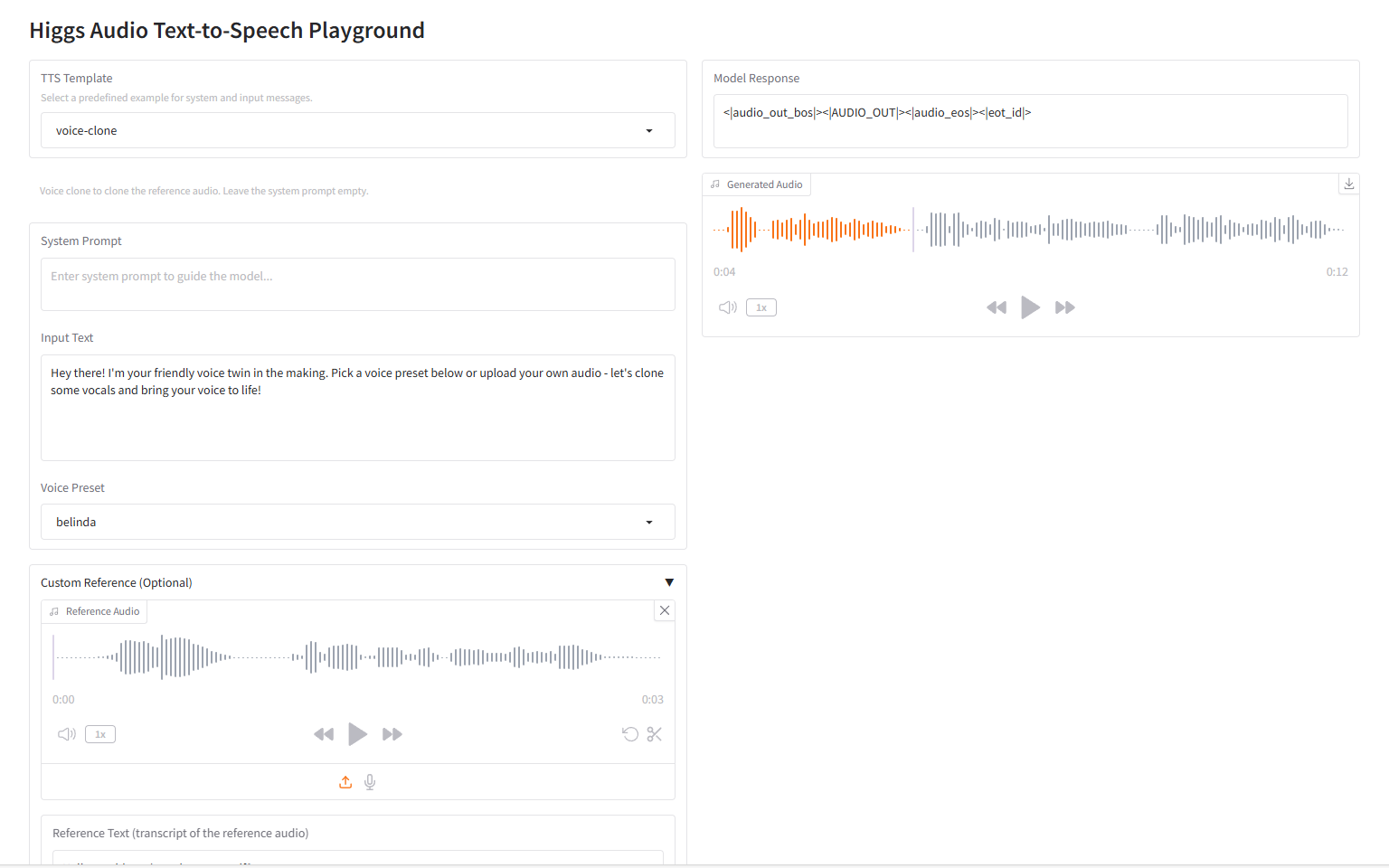
voice-clone 项目示例
2. Ovis-U1-3B:多模态理解与生成模型
Ovis-U1-3B 是由阿里巴巴集团 Ovis 团队发布的多模态统一模型。该模型集成多模态理解、文本到图像生成和图像编辑三种核心能力,基于先进的架构和协同统一训练方式,实现高保真图像合成和高效的文本视觉交互。
在线运行:https://go.hyper.ai/oSA7p

项目示例
3. Neta Lumina:高品质二次元风格图像生成模型
Neta Lumina 是由捏 Ta 实验室(Neta.art)发布的高品质二次元风格图像生成模型。该模型基于上海人工智能实验室 Alpha-VLLM 团队开源的 Lumina-Image-2.0,利用海量、高质量的二次元风格图像及多语种标签数据,使模型具备强大的需求理解与诠释能力。
在线运行:https://go.hyper.ai/nxCwD

项目示例
4. Qwen-Image:具有高级文本渲染能力的图像模型
Qwen-Image 是由阿里巴巴通义千问团队发布的高质量图片生成和编辑的大模型。该模型在文本渲染领域实现突破,支持中英双语多行段落级高保真输出,对复杂场景与毫米级细节均具备精准还原能力。
在线运行:https://go.hyper.ai/8s00s

项目示例
5. MediCLIP:采用 CLIP 进行小样本医学图像异常检测
MediCLIP 是由北京大学发布的一种高效的少样本医学图像异常检测方法,仅需极少数正常医学图像即可展现出顶尖的异常检测性能。该模型集成了可学习的提示、适配器以及逼真的医学图像异常合成任务。
在线运行:https://go.hyper.ai/3BnDy

项目示例
6. Aeneas 模型:古罗马铭文修复 Demo
Aeneas 是由 Google DeepMind 联合多所高校发布的多模态生成式神经网络,用于拉丁与古希腊铭文的文本修复、地理归因与年代归因。该模型的发布标志着数字碑铭学进入全新时代,其在古代文本修复、地理/时间归因、历史研究辅助等领域的潜力巨大,有望加速科学发现与跨学科应用。
在线运行:https://go.hyper.ai/8ROfT

项目示例
7. 一键部署 Qwen3-Coder-30B-A3B-Instruct
Qwen3-Coder-30B-A3B-Instruct 是由阿里巴巴旗下通义万相实验室推出的大语言模型,在代理编码、代理浏览器使用和其他基础编码任务上的开放模型中具有显着的性能,能够高效地处理多种编程语言的编码任务。其强大的上下文理解和逻辑推理能力使其在复杂项目开发和代码优化中表现出色。
在线运行:https://go.hyper.ai/vYf3s
项目示例
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD 教程】,入群探讨各类技术问题、分享应用效果~

1. Qwen-Image Technical Report
Qwen-Image 是 Qwen 系列中的一个图像生成基础模型,在复杂文本渲染与精确图像编辑方面取得了显著进展。为应对复杂文本渲染带来的挑战,研究人员设计了一套完整的数据处理流程,涵盖大规模数据采集、过滤、标注、合成与平衡等环节。该模型在多个基准测试中均达到当前最优性能,充分展现了其在图像生成与编辑任务中的强大能力。
论文链接:https://go.hyper.ai/HWjVM
2. Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
本文提出 Seed Diffusion Preview,这是一种基于离散状态扩散机制的大规模语言模型,具备极快的推理速度。得益于非顺序的并行生成机制,离散扩散模型显著提升了推理效率,有效缓解了传统逐标记解码带来的固有延迟。
论文链接:https://go.hyper.ai/NvrNm
3. Cognitive Kernel-Pro: A Framework for Deep Research Agents and Agent Foundation Models Training
通用人工智能代理(General AI Agents)正日益被视为下一代人工智能的基石性框架,能够实现复杂推理、网络交互、编程以及自主研究等能力。在本研究中,研究人员提出 Cognitive Kernel-Pro——一个完全开源且在最大程度上免费的多模块智能代理框架,旨在推动先进人工智能代理的开发与评估的民主化。
论文链接:https://go.hyper.ai/65j3v
4. Beyond Fixed: Variable-Length Denoising for Diffusion Large Language Models
在本文中,研究人员提出了一种无需训练的新型去噪策略—— DAEDAL,实现了 DLLMs 的动态自适应长度扩展。在多种 DLLMs 上的大量实验表明, DAEDAL 在性能上可达到甚至在某些情况下超越精心调优的固定长度基线模型,同时显著提升了计算效率,实现了更高的有效 token 比率。
论文链接:https://go.hyper.ai/p7WxK
5. Skywork UniPic: Unified Autoregressive Modeling for Visual Understanding and Generation
本文提出了一个参数量为 15 亿的自回归模型 Skywork UniPic,该模型在单一架构内统一实现了图像理解、文本到图像生成以及图像编辑功能,无需依赖特定任务的适配器或模块间连接器。通过证明高保真多模态融合无需付出高昂的资源代价,Skywork UniPic 建立了一种可部署、高保真多模态人工智能的实用范式。
论文链接:https://go.hyper.ai/FiVaf
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
1. 登 Nature 子刊,基于基因测序和机器学习的废水流行病学评估,病毒检出时间最高提前 4 周
内华达大学拉斯维加斯分校的研究团队提出一种名为 ICA-Var 的多变量分析方法,该方法基于无监督机器学习流程设计,通过独立成分分析从废水数据中提取共变和时间演变的突变模式,实现了更早、更准确的变异株检测。
查看完整报道:https://go.hyper.ai/z1vVo
2. 在线教程丨 Qwen3-Coder-Flash 刷新开源 AI 编程 SOTA,Agentic 能力媲美 Claude4
Qwen 团队开源 Qwen3-Coder-Flash,其在代理编码、代理浏览器使用和其他基础编码任务上的开源模型中具有优越性能,能高效处理多种编程语言的编码任务,同时强大的上下文理解和逻辑推理能力使其在复杂项目开发和代码优化中表现出色。
查看完整报道:https://go.hyper.ai/FmOep
3. 登 Science,David Baker 团队提出无序区域结合蛋白设计新方法,专攻不可成药靶点
针对天然无序蛋白质的靶向问题,David Baker 及其团队提出了一种名为 Logos 的蛋白质设计策略,使蛋白质可以结合具有多种延伸构象的天然无序蛋白质区域,侧链可插入互补的结合口袋。研究利用 RFdiffusion 模型重新组合口袋并将其推广至广泛序列中,基于设计的结合蛋白-目标肽模版实现对无序蛋白质区域的通用识别。
查看完整报道:https://go.hyper.ai/F0lti
4. 设计蛋白变体活性提升 50 倍!清华 AIR 周浩团队基于贝叶斯流网络提出 AMix-1,实现可扩展通用的蛋白质设计
清华大学智能产业研究院周浩课题组联合上海人工智能实验室,基于贝叶斯流网络提出蛋白质基座模型 AMix-1,首次以 Pretraining Scaling Law 、 Emergent Ability 、 In-Context Learning 和 Test-time Scaling 的系统化方法论来构建蛋白质基座模型,将大语言模型的成功范式引入蛋白质设计,并通过 Test-time Scaling 和真实实验验证了其高效性和通用性。
查看完整报道:https://go.hyper.ai/X9iMe
5. GPT-5 发布,Sam Altman:像和博士级别专家对话,编程/写作/健康三大场景重点升级
OpenAI 正式发布 GPT-5,此次在 ChatGPT 最常见的三大应用场景——写作、编程和健康领域,进一步提升了 GPT-5 的性能。 GPT-5 作为一个统一系统,包含一个智能高效的模型用以回答大多数问题(GPT-5-main),一个用于解决更复杂问题的深入推理模型(GPT-5-thinking),以及一个实时 router,可根据对话类型、问题复杂度、所需工具以及用户的明确意图快速决定使用哪个模型。
查看完整报道:https://go.hyper.ai/gFHQg
1. DALL-E
2. 倒数排序融合 RRF
3. 帕累托前沿 Pareto Front
4. 大规模多任务语言理解 MMLU
5. 对比学习 Contrastive Learning
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:https://go.hyper.ai/wiki
8 月 21 日 11:59:59 ASPLOS 2026
8 月 27 日 7:59:59 USENIX Security Symposium 2025
一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
内容中包含的图片若涉及版权问题,请及时与我们联系删除
