
台積電製程的挑戰有多大?以今年要邁入量產的2奈米製程來比喻,這個等級製程的控制難度,就像是兩臺飛機平行飛行,相距只有5公分,需要精密控制到能讓彼此安全的一起飛行,不會相撞。資料處理速度也是一大難題挑戰,台積的晶圓廠一小時會產生200萬張掃描影像,必須在一小時內辨識出1千個可疑的瑕疵點,進一步分析,來確保製程的良率。
為了達到這樣的生產能力,台積一座晶圓廠中,各式各樣的機臺設備超過了5千部,一天總共會下達上千萬條生產指令。這些設備會產生不同形式的資料,光是一座晶圓廠,一天就會產生近2TB的龐大資料。
為了協助工程師能夠更有效地分析晶圓廠的狀況,台積IT正在打造一套現代化的資料平臺和分析平臺,可以用來協助工程師即時診斷、分析和掌握工廠的狀態。這是台積今年初新成立的平臺工程處(Platform Engineering Division,簡稱PLED)的任務。
資料平臺大進化:從商用資料庫、Hadoop到現代化湖倉架構
台積早在一、二十年前,就已經發展了第一代的資料平臺,採用大量商用等級的資料庫叢集,來管理和分析龐大的工程數據。按照不同專業領域來劃分資料庫,因為每個領域的用戶團隊可能多達上百個,更有數百隻AP。
台積IT第一代資料平臺,按照領域劃分資料庫,採取多團隊共享的資料架構,也出現了許多資料孤島。(圖片來源/台灣積體電路製造股份有限公司)
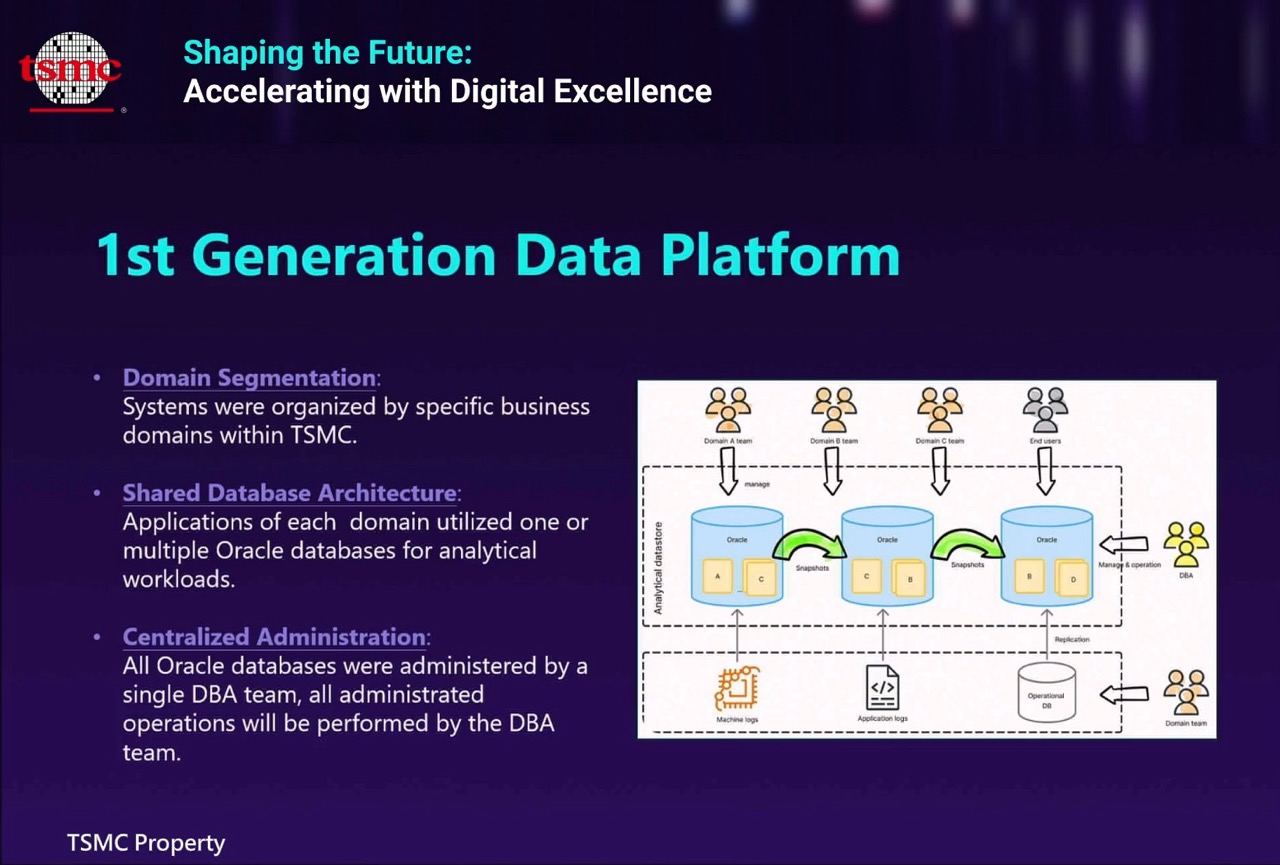
第一代資料平臺架構中採取共享式的資料架構,多個團隊共用一個資料庫系統,一隻AP也可能需要存取多個資料庫來分析。由用量最大的團隊負責管理,並搭配專門DBA,統一執行所有資料庫的操作。第一代資料架構的缺點是,產生了許多資料孤島,尤其要進行跨領域的分析,往往會涉及不同領域下多套資料庫系統內的資料整合,相當麻煩。再加上工廠的數據量越來越龐大,共享架構資料庫的查詢效能也受到影響。
後來,台積IT改採用了開源大數據分析平臺Hadoop,搭配開源的分散式NoSQL資料庫Cassandra,來打造分散式架構的資料平臺,這就是第二代資料平臺。不同於第一代採領域劃分資料庫的做法,Hadoop的超強擴充能力,可以將所有領域的資料集中到單一平臺,不用再受限於資料庫的儲存上限和效能負擔。第二代資料平臺同樣採取集中式的管理,由平臺工程師管理所有資料平臺架構面的維運,也統一了各領域的操作流程。
台積IT第二代資料平臺,採用開源大數據分析平臺Hadoop,搭配開源分散式NoSQL資料庫Cassandra,來打造分散式架構的資料平臺。(圖片來源/台灣積體電路製造股份有限公司)
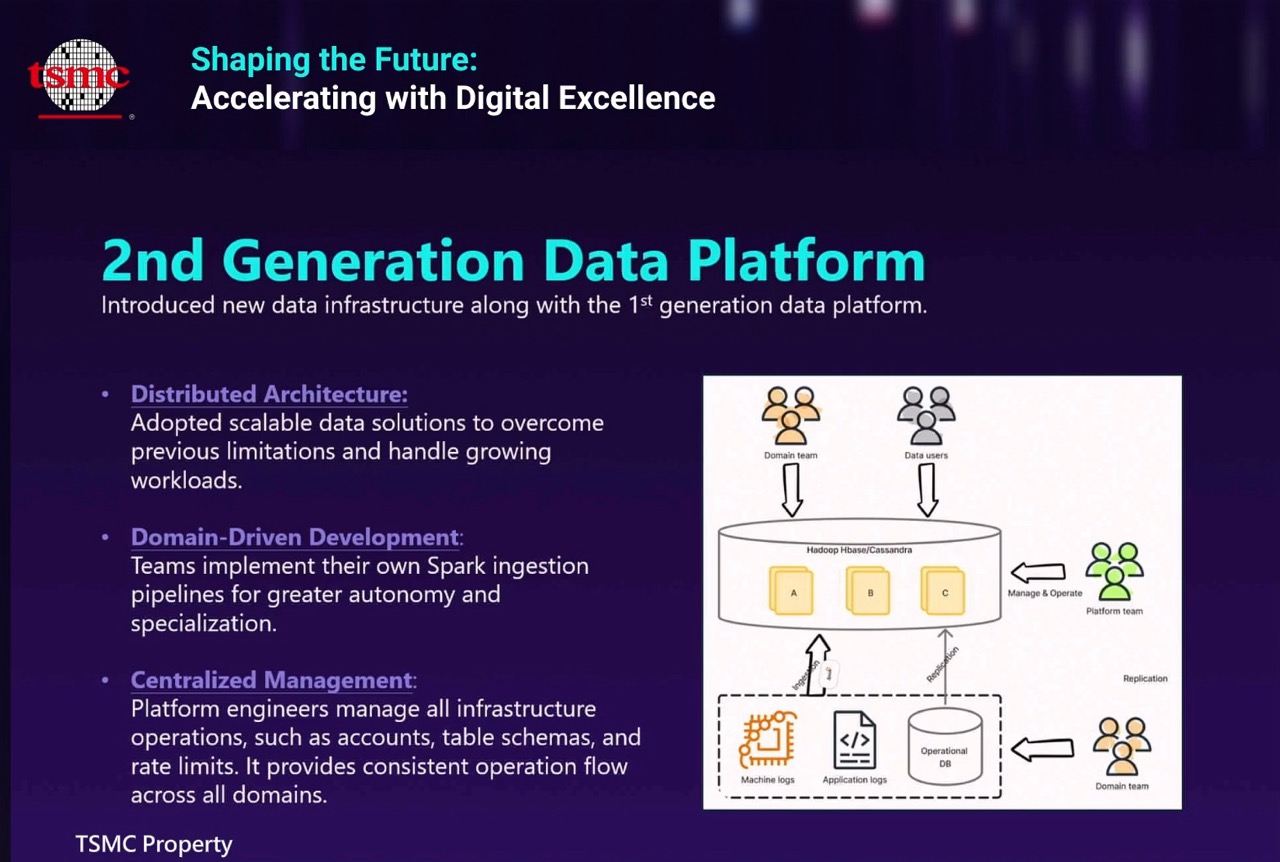
但是,第二代平臺的挑戰是,每個AP團隊得自己開發專門處理大數據資料的Spark程式,來支援自己的AP。不過,不是每個團隊都擅長這類分散式資料處理技術,有些團隊自製的Spark程式的效能不夠理想。
另一個挑戰是,不是所有第一代資料平臺上的分析應用,都能順利轉移到分散式架構的第二代資料平臺,像有不少複雜的SQL查詢,很難轉換成分散式架構,導致第一代資料平臺無法淘汰,兩代平臺必須並用。這不只讓維運工作更複雜,也增加了更多資料處理的瓶頸,資料孤島的問題還是沒有完全解決。
所以,台積IT打造了第三代資料平臺,採用了現代化湖倉架構(Lakehouse),這是以OLAP線上分析處理為主的設計架構,可以支援到PB級資料的處理能力,又能支援多樣化的資料查詢方式,包括SQL,同時來解決第一、二代資料平臺的問題。台積IT平臺團隊還將第三代資料平臺,打造成一個自助式的SaaS產品,使用者可以自己透過拖拉介面或透過命令列工具來操作資料平臺上的共用元件或資源,就像是公雲服務等級的友善自助式操作介面。
台積IT第三代資料平臺,採用現代化的湖倉架構,採取OLAP線上資料處理的設計,可以支援到PB級資料的處理能力,又能支援多樣化的資料查詢方式。(圖片來源/台灣積體電路製造股份有限公司)
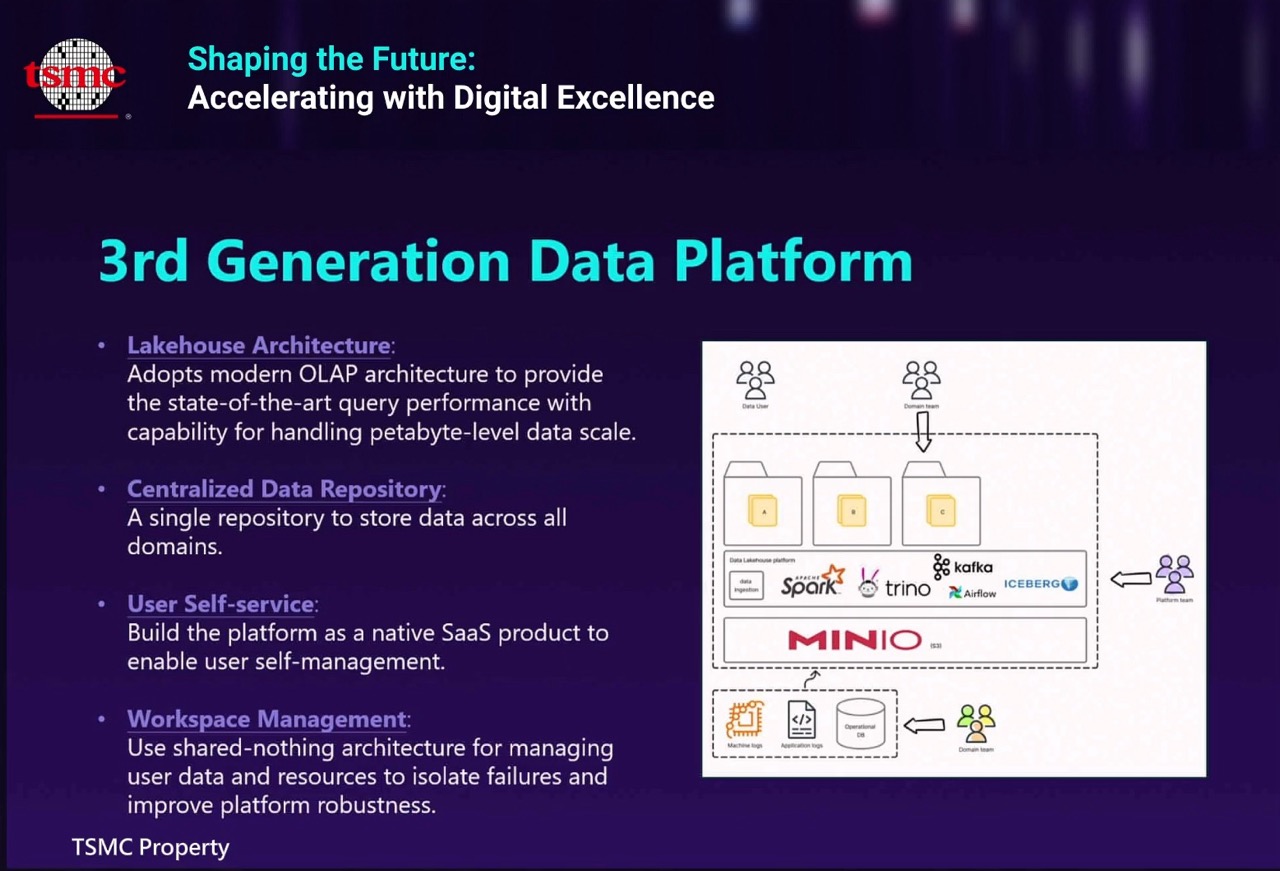
第三代平臺終於可以將所有領域的所有資料都集中到單一平臺中,不再有資料孤島問題。透過自助式服務,可以大幅提升DevOps開發團隊的生產力,開發人員自助取得需要的資料源,不用像過去得填寫申請工單,等待資料維運人員操作。因為採分散式設計的湖倉架構,可以實現不共享原則,讓每一個團隊建立自己的工作區,有自己的儲存和算力資源等,可以避免單一團隊出錯,影響到整套資料平臺的效能
台積IT資料平臺的未來發展目標是「資料民主化」
台積這套第三代資料平臺的發展還沒有結束,台積IT未來能實現「資料民主化」(Data Democratization)的願景,可以讓企業中的每一個資料使用者,不需要依靠資料工程團隊,也能探索、存取、了解和信任平臺上的資料。

為了實現資料民主化願景,台積IT接下來從四大方面來強化資料平臺,第一是資料探索和治理機制,像是集中式資料探索機制、資料血統分析、資料架構和所有權管理、資料安全控管等。其次是要打造自助式分析工具,提供如自助探索用的儀表板和視覺化工具,也要能支援重度分析者的程式化操作需求,第三個方向是提供資料建模和語意層,可用來將原始資料,轉換成貼近業務也容易重複使用的資料產品,最後一個面向是要有確保資料完整性的機制,像是資料可觀察性的處理流程,自動化的資料驗證機制等。
台積第三代資料平臺的願景,不只是要打造一套統一的平臺和工具鏈,更像是要發展一個讓台積所有人都能容易善用的資料生態系。
2023年初大力擁抱生成式AI,2025年要加碼發展AI
台積是臺灣很早就開始善用AI的企業之一,早在2011年,就將AI技術引進晶圓製造,積極發展各項大數據應用和平臺,資料平臺也不斷演進改版。2022年的台積IT數位轉型目標,更瞄準了全面智慧化挑戰,要強化資料處理、智識萃取、規模化(如AI服務平臺化、產品化,來擴大AI應用規模和廣度)以及AI應用的全球維運與安全。
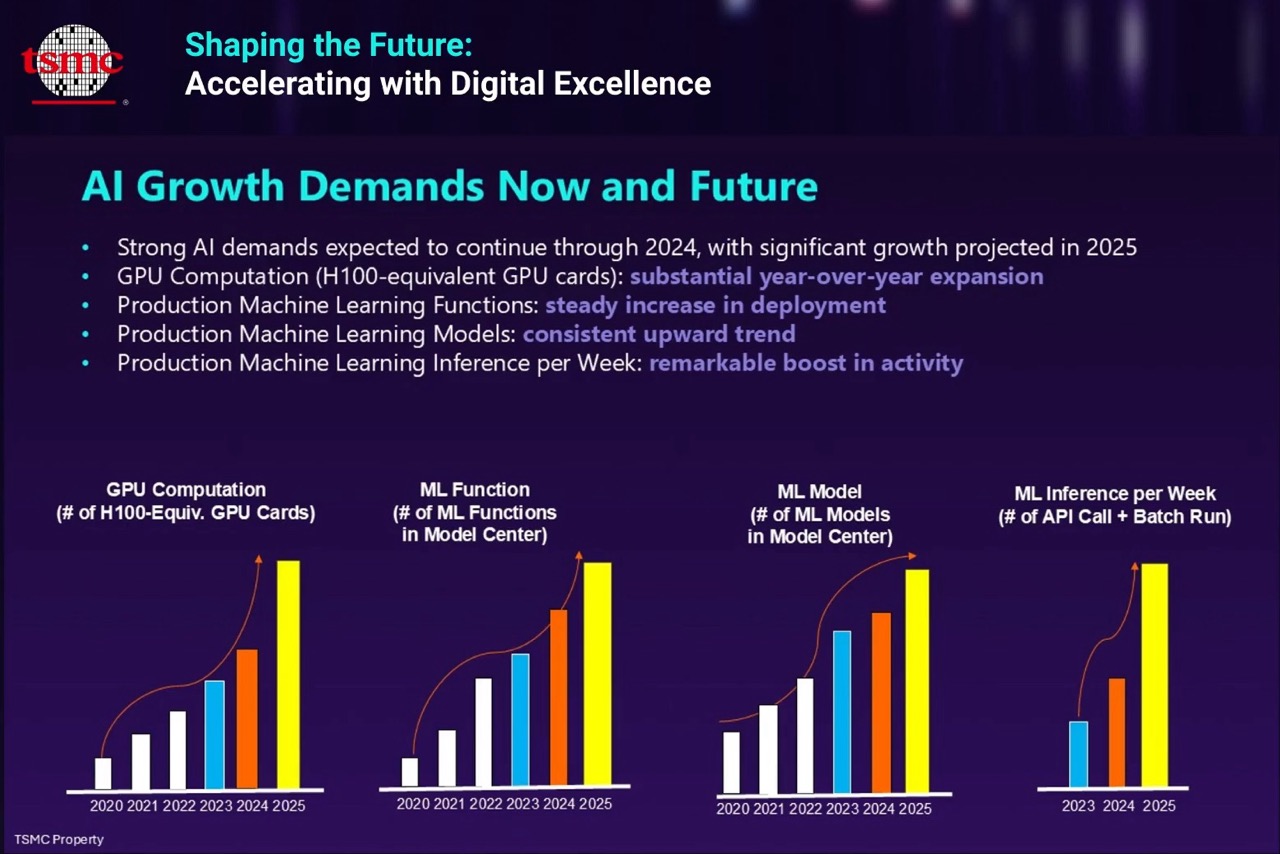
為了處理一年比一年增加的海量數據和大量AI需求,台積需要龐大的算力。台積IT這幾年的GPU卡用量年年成長,若以H100等級GPU的算力來估算,台積從2024年開始爆發強勁的算力需求,2025年的GPU算力需求是2020年的好幾倍之多。台積AI應用需求也是年年增加,從模型技術或機器學習功能的需求,都是一年比一年成長。2025年對AI推論需求更暴增,平均一周需要的模型推論需求,就比2024年的平均每周需求量,多了一倍,這些數據都反映出台積全力發展AI的力道。
台積IT過去六年AI算力需求變化,2025年預估是2020年前的好幾倍。(圖片來源/台灣積體電路製造股份有限公司)
生成式AI爆紅後,台積IT很快地在2023年初就引進這項技術,搭配一套內部機密資料保護機制,來避免資料外流的風險。像是台積曾在官方臉書專頁上分享,2023年5月推出了一款AI夥伴tGenie,可以回答問題、提供資訊,也能執行一些指令,或是設定提醒事項、翻譯語言、幫忙計算數學問題等。
台積接下來要雙倍加碼發展AI的戰略,也包括了生成式AI應用的發展。台積IT發展的內部AI,主要可以分為兩大類,一類是通用型AI(Generic AI),另一類則是領域型AI(Domain AI)。
台積IT雙倍加碼AI的發展焦點,可細分為通用型AI、領域知識型AI,領域技能型AI。(圖片來源/台灣積體電路製造股份有限公司)
台積IT所發展的通用型AI,採用了商用AI技術和企業級LLM,可以提供文件摘要,開發輔助等GAI運用,也會跟著模型改版,來升級台積自己的通用型AI。
另一類的領域型AI,本質上和通用型AI有很大的不同。通用型AI指的是,用通用性知識來訓練的AI模型,而非領域或產業專業知識,就像是在學校學到的知識所教出來的學生。但在一個產業工作數十年所累積的專業領域知識,遠遠超過了學校的通用型知識,企業需要有自己專業領域知識的AI,這也是台積想要打造領域型AI的原因。
台積IT還將領域型AI細分成兩類,一類是領域知識型AI(Domain Knowledge AI)和領域技能型AI(Domain Skills AI)。
領域知識型AI的模型會使用產業專業知識來訓練,也會整合內部大量的標準作業流程和做法,來訓練出內部專屬的客製化LLM。更特別的是,台積想要發展的領域知識型AI,所能生成的內容,要有能力即時更新到內部最新的知識內容,不用像通用型AI得等到商用版模型更新或重新訓練,才能更新模型知識內容的新穎程度。而領域技能型AI則是要發展更專門用途的AI,像是製造用AI、研發用AI和運籌物流用AI等。
首度公開!台積IT生成式AI應用發展路線圖
在今年IT Day活動中,台積更首度公開了自家生成式AI應用的發展路線圖,以LLM應用的發展區分出四個階段。
台積IT的生成式AI應用發展路線圖,以LLM進展分為四個階段,2025到2026年第四階段的發展目標是LLM和系統協作。(圖片來源/台灣積體電路製造股份有限公司)

2023年是第一階段,要借重全球LLM經驗,善用雲端LLM的知識和能力,快速打造出一般性的GAI應用,像是個人助理tGenie或程式碼開發助手。
2024年進入第二階段,要發展「量身定做專業知識的LLM」(LLM Tailored Expertise),結合了台積自己獨有的資料,開始建置本地端執行的專用型大型語言模型,來解決特定任務的需求,像是知識管理AI助手,數位客服,內部服務臺(Helpdesk)等。接著,2024年後續進入第三階段的發展,要讓「LLM與系統互動」,可以透過自然語言對多個系統下命令,來提高效率,像是用自然語言來輔助問題分析、故障排除等。
到了2025年到2026年,台積IT的LLM發展進入了第四階段,新的目標是「LLM和系統協作」,要善用LLM和台積的系統無縫協作,將複雜的任務,轉換成單一流暢的處理程序。現在當紅的代理型AI技術,正是台積GAI第四階段發展的重點。
代理型AI和傳統AI最大的不同是,傳統AI一次只能執行一項任務,但代理型AI具有自主能力,可以像人般的做決策,將複雜問題分解成可以管理的步驟,甚至可以透過NLP技術或大型語言模型來理解人類提出的問題,來提高解答的正確率。台積IT現在也聚焦代理型AI的研究,甚至開始思考如何將工作流程和代理型AI整合。 像是值班人員AI助理、故障排除AI助手、程式開發助手等,將這些人員例行複雜的任務系統化。
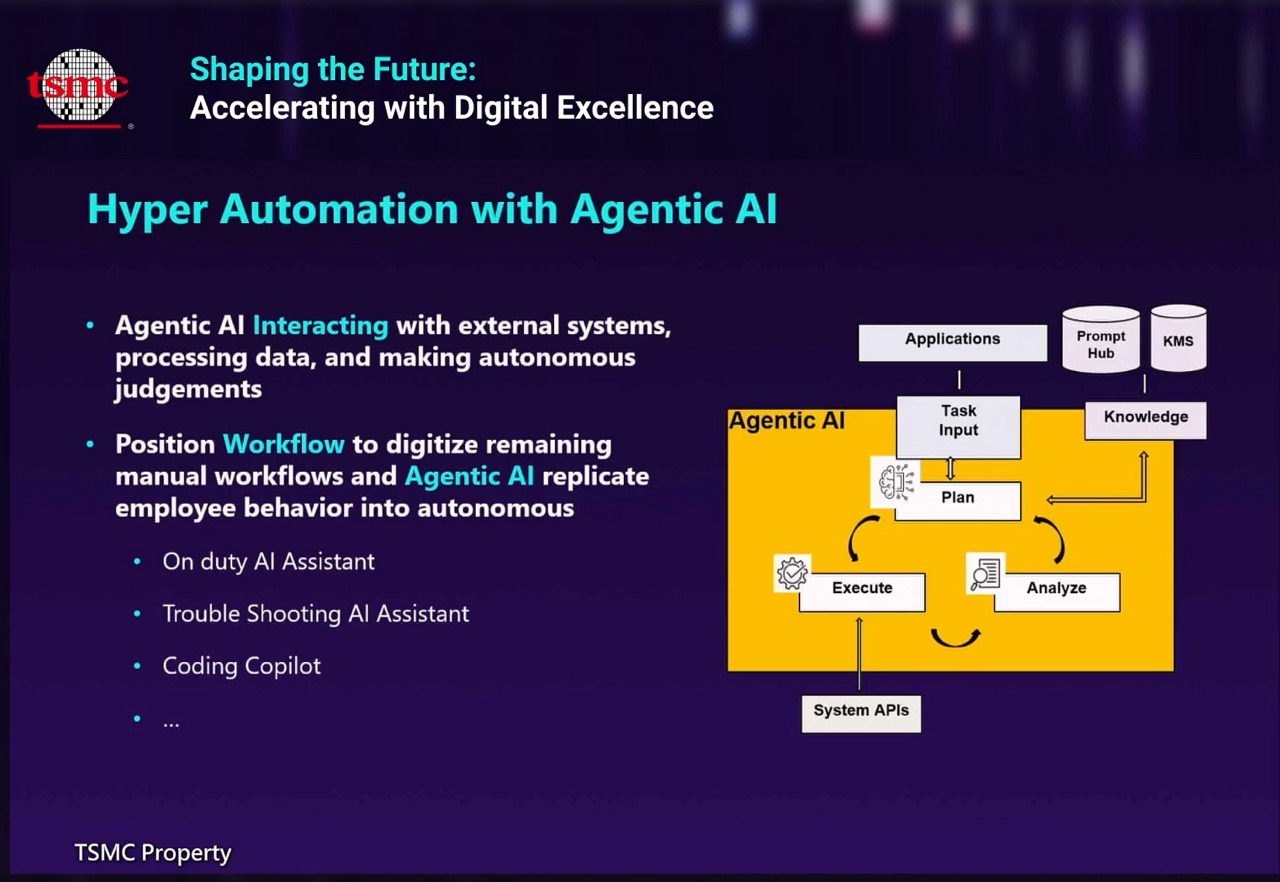
如何用代理型AI實現超級自動化,台積IT從兩大方向著手
台積IT想要用代理型AI來實現「超級自動化」(Hyper Automation),一方面讓代理型AI與外部系統互動,進行資料處理,甚至有能力自主判斷。另一方面,運用代理AI模仿真人員工的行為來行動,將目前仍需手動處理的流程盡可能數位化。
從「跑在程式碼上的晶圓廠」到「全面邁向數位卓越」發展戰略,過去兩年多來的數位轉型,IT成為台積電全球製造的核心關鍵,重要性更是年年不斷提高,GAI時代崛起,帶來了許多快速演進的新技術,像是代理型AI,成了台積IT解決全球化擴廠挑戰的新武器。IT可以對台積產生很大的影響力,若能用IT提升1%的效能,就可能帶來價值十億元的影響。
LLM模型年年升級,大廠激烈競賽下,各種GAI新興技術、工具,全新的軟體工程思維,紛紛出籠,幾個月就有很大的變革,許多IT人更湧出了一種,不趕上最新變化就落後的GAI焦慮感。
不斷追趕激烈的GAI浪潮同時,林宏達這位率領台積IT的舵手提醒,IT人可以暫時停下腳步,好好想一想。在今年台積IT Day開場演講最後,他提醒臺灣的IT人,有機會可以關掉電視、新聞牆,找個地方,好好思考,以現在的進步速度,五年後的世界會變成什麼模樣?工作模式如何改變?「你所想像的未來,許多要靠IT的努力來實現。身在這個時代的IT是非常幸運的事,這是非常好的時機。」
繼續看更多【台積電IT卓越新戰略】
【台積電IT卓越新戰略1】台積IT數位轉型下一步,四大原則加速邁向數位卓越
【台積電IT卓越新戰略2】台積IT怎麼用GenAI?生成式AI發展路線圖首度大公開
【台積電IT卓越新戰略3】全球擴廠三大難題,台積IT如何善用GenAI因應的關鍵(超長文)
