index_new5.html
../../../zaker_core/zaker_tpl_static/wap/tpl_guoji1.html
![]()
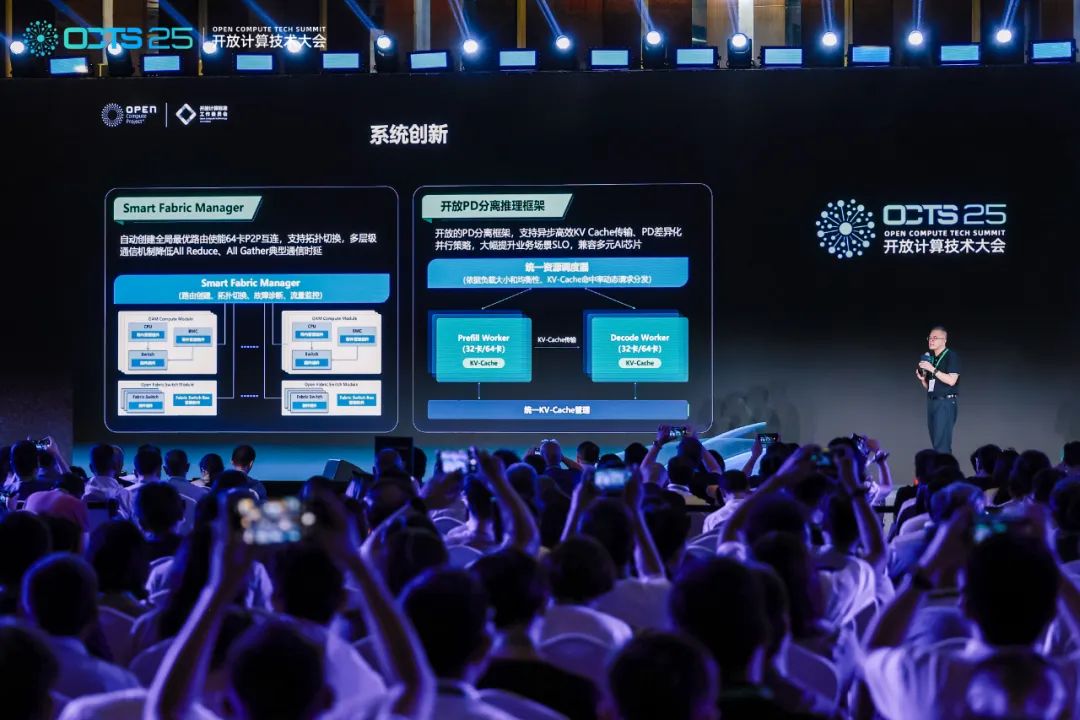
浪潮信息发布了其超节点AI服务器「元脑SD200」,该服务器创新性地实现了单机运行万亿参数大模型。通过Scale Up算力AI系统,元脑SD200在更大显存、高速互联和算力方面实现了突破,全面可商用。其基于Open Fabric Switch构建的3D Mesh系统架构,聚合64路本土GPU芯片,突破了显存统一编址难题,最高可提供4TB统一显存,为万亿序列模型提供了充足空间。此外,Smart Fabric Manager系统优化了64卡全局最优路由,并支持PD分离推理框架,兼容多元AI芯片,旨在打破算力边界,推动AI算力基础设施的开放化、标准化和协同化发展。
🚀 **单机万亿参数模型运行成为现实:** 浪潮信息推出的元脑SD200超节点AI服务器,通过Scale Up技术,实现了在单台服务器上同时运行DeepSeek、Qwen、Kimi、GLM等国产开源大模型,并且能够轻松处理超万亿参数的模型,这标志着AI算力基础设施在处理超大规模模型方面取得了重要进展。
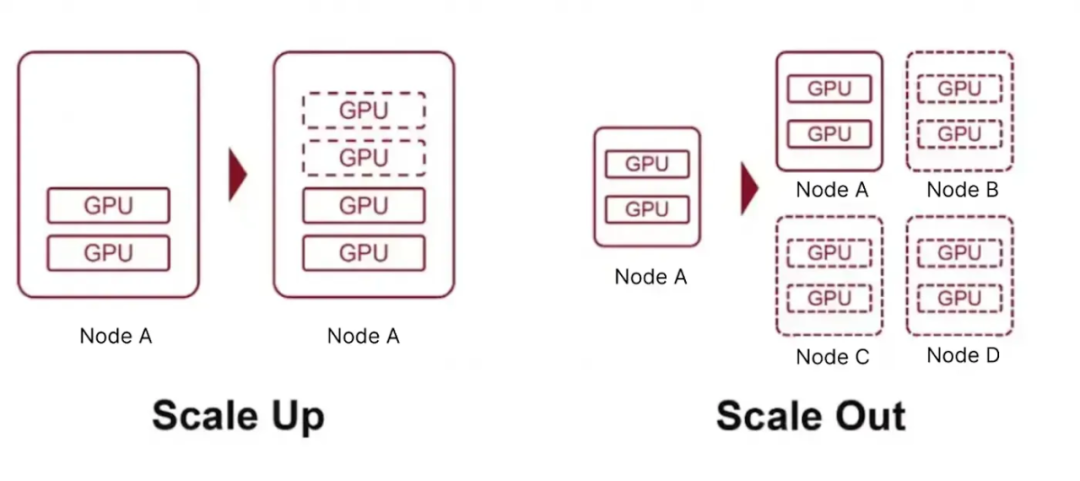
💡 **“超节点”架构的Scale Up优势:** 元脑SD200的核心在于其“超节点”架构,采用Scale Up策略,将更多的GPU资源整合到单一节点内,构建低延迟、高带宽的统一算力实体。这与传统的Scale Out方案不同,尤其在推理过程中常见的小数据包通信场景下,性能提升显著,有效解决了大模型推理的“显存墙”和“带宽墙”瓶颈。
🌐 **开放架构与生态构建:** 浪潮信息强调“开放架构”的核心战略,通过聚合64路本土GPU芯片、提供多种算力方案,并兼容如OCP、OAM等开放标准,旨在降低硬件成本,实现规模效应,并快速适配客户应用场景。这种开放性加速了万亿参数模型的商业化落地,并带动了整个产业链的协同创新。
🔧 **软硬协同优化与技术积累:** 元脑SD200的成功离不开浪潮信息在软硬件协同方面的深厚技术积累,包括多主机低延迟内存语义通信架构、Smart Fabric Manager系统以及开放的PD分离推理框架。这些技术优化了算力芯片的利用率,降低了通信延迟,并提升了不同场景下的业务性能,为大模型的研发和应用提供了坚实支撑。
DeepSeek+Qwen+Kimi+GLM,超万亿参数的模型,竟毫无一丝压力地神速输出。你可能会问:一次性运行如此巨量的参数模型,靠的是什么?答案并不是简单地堆砌多个集群,而是算力AI系统不断Scale Up的终极成果,简而言之就是「超节点」(SuperPod)。这个最初由英伟达提出的概念,如今在国内外火的一塌糊涂。2025开放计算技术大会上,浪潮信息带着超节点AI服务器「元脑SD200」来了,单机即可跑万亿参数模型。它具备了更大显存空间、更大Scale Up高速互联域,以及更大算力超节点系统。元脑SD200,是一个可支持万亿参数大模型运行的超节点AI服务器。浪潮信息基于创新研发的多主机低延迟内存语义通信架构,以开放系统设计了这个服务器,可以聚合64路本土GPU芯片。这背后,就是浪潮信息在计算领域Scale Up十几年的技术积累,和前沿大模型开发的一手经验。而结果也是十分惊人,实测显示,SD200直接突破了系统的性能边界,在大模型的多个应用场景上,都实现了极佳的算力曲线!比如在DeepSeek R1的全参PD分离推理测试中,推理框架可以实现64卡性能370%的扩展效率。在应用架构层面,浪潮信息基于Open Fabric Switch,构建了3D Mesh系统架构,实现了单机64路本土GPU芯片的高速互连。同时,他们通过远端的GPU虚拟映射技术,突破了多Host交换域的统一编址难题,让显存的统一地址空间直接扩增了8倍。由此,单机可以提供最大4TB的统一显存,和64GB的统一内存。这就为万亿超长序列模型提供了充足的KV Cache空间。因此,SD200的客户就有充分的空间,可以去探索各类前沿大模型的创新应用场景!比如开头提到的场景——单机部署DeepSeek、Qwen、Kimi、GLM四大开源模型,发挥各个模型的能力专长,让Agent按需调用。同时,基于百纳秒级的超低延迟物理链路,它可以实现64卡大高速互连域的原生内存语义通信,还能支持Load-store、Atomic这种原子操作,在推理常用的小数据包场景上,能力提升非常明显。并且,作为一款复杂的异构计算系统,不仅需要卓越的硬件架构设计,还需要有一套与之相匹配的软件系统。因此,根据万亿参数大模型计算通信需求的特征,浪潮信息团队研发了Smart Fabric Manager系统,实现了超节点64卡全局最优路由。它能支持多卡多用、不同拓扑结构的切分和切换,也就可以实现按需分配。针对All Reduce、All Gather这种典型的通信算子,团队开展了不同层级的通信策略,实现了通信延迟的进一步降低。它可以支持异步高效的KV Cache传输,能满足多种不同场景的需求。PD差异化的并行策略,大幅提升了业务场景的SLO,还能兼容多元的AI芯片。在AI浪潮的汹涌推动下,LLM的迅猛发展对算力提出了近乎苛刻的要求。与此同时,AI已经成为全行业战略性的业务选择,随之带动了巨大的算力消耗。麦肯锡曾给出这样的预测数据:在未来五年,全球AI数据中心的总投资将达到5.2万亿美元。而随之新增加的电力容量增量,将达到125GW。这个数字,相当于整个2024年中国总用电量的20%,或者十个三峡电站的发电量。而到2030年,AI数据中心的算力容量将达到2025年容量的3.5倍。从千亿到万亿参数规模的飞跃,MoE架构继续推动大模型不断Scaling,由此算力集群也加速迈向了「万卡协同」时代。这几天,全球开源模型轮番轰炸,比如OpenAI刚刚开源gpt-oss 20B和120B推理模型。再加上前段时间,Qwen、Kimi、GLM等多款模型相继开源,成功跻身全球顶尖开源大模型阵营。随着LLM继续向万亿、甚至十万亿参数规模和更长上下文演进,其推理和训练过程算力需求呈指数级增长。不论是GPT-5、Grok 4、Gemini 2.5 Pro等闭源模型,还是gpt-oss、Kimi K2等开源模型,参数量自增导致KV缓存剧增,远超传统AI服务器显存能力极限。与此同时,Agentic AI的兴起,进一步加剧了算力挑战。它们具备了自主决策、连续任务执行、多模态交互等能力,其推理过程要比传统模型多100倍toekn。而且,其输出结果往往会作为下一步输入,推理速度往往在50-100 token/s。显然,这对显存容量和带宽提出了极高的要求,形成了「显存墙」和「带宽墙」的双重瓶颈。另一方面,摩尔定律逐渐放缓,芯片制程提升成本和难度不断加大,业界亟需新的算力增长路径。此时,超节点通过整合GPU资源,构建高性能算力实体,成为必然路径。无论是模型参数量的增加、大模型推理的需求,还是Agentic AI的多模协作范式,都需要更大显存空间、更大高速互联域、更高算力的超节点系统支撑要知道,在大模型训推中,芯片互联拓扑的高效性至关重要。为了满足模型并行计算所需的海量数据交换,超节点必须具备高带宽和低时延的通信能力。Scale Up通过在单一节点内,整合更多GPU资源,构建出低延迟、高带宽的统一的算力实体。它不仅有效支撑并行计算任务,还能加入GPU之间参数交换和数据同步。相较于传统的Scale Out方案,Scale Up具备了显著优势。会上,浪潮信息副总经理赵帅表示,「推理对延迟敏感,Scale Up通过短链路实现更高效的芯片间通信,特别是在推理过程常见的小数据包通信场景下性能提升显著」。而且多芯片封装在同一IO带上,可以构建高带宽、低延迟的统一计算域。以英伟达GB200 NVL72为例,整合72个GPU和36个CPU,吞吐量比传统8卡服务器互联方案高出3倍。未来3-5年,Scale Up和Scale Out将并行发展,前者将域持续扩大支持更大模型,后者规模也将增长以应对多模型协同需求。如今,在国内,超节点成为了AI算力领域的「风向标」。燧原科技、沐曦等国产AI芯片厂商,以及浪潮信息等AI服务器厂商正加速布局,尝试在该赛道上占据一席之地。与别家不同的是,浪潮信息以「开源开放」为核心战略,正加速万亿参数大模型的商业化落地。当前,业界在AI计算系统架构创新上,存在多种技术路径,如异构计算、存算一体、协同创新等。在浪潮信息看来,每种路径都有价值,需根据应用需求具体选择。异构计算强调芯片多样性;存算一体注重存储与计算融合;协同创新则打通了芯片、系统和软件层面。从元脑SD200产品中不难看出,浪潮信息聚焦的是Scale Up的路径,优先去解决大模型推理的低延迟需求,同时通过软硬协同去挖掘算力的潜力。赵帅总表示,「开放架构」是核心策略,通过提供多种算力方案,从应用角度给客户更多选择。它通过贴近客户需求,快速适配应用场景,加速万亿参数模型在AI4 Science、工业等领域的落地。诸如OCP、OAM开放标准推动了规模效应,进而降低电路板、线缆等硬件成本,让超节点从巨头走向普惠。在这过程中,浪潮信息通过整合国内供应链,如高速连接器、线缆、电源等,进而提升生态竞争力。元脑SD200另一大优势,便是扩大兼容的软件生态。一些基于传统大模型做定制的客户,如生物医药、气象等领域的模型,可以实现快速迁移、满血运行。采访中,赵帅总表示,元脑SD200超节点的技术,脱胎于其「融合架构」的长期积累。自2010年起,团队便开始探索融合架构,从最初的供电、散热等非IT资源的整合,到存储、网络等资源池化,再到最新融合架构3.0系统实现了计算、存储、内存、异构加速等核心IT资源彻底解耦和池化。由此沉淀下来的芯片共享内存数据、统一编址技术、池化、资源动态调度等技术,为超节点的研发积累了深厚的技术基础。正如上文所提,内存语义通信技术的应用,使得元脑SD200能够快速适配万亿参数模型的场景需求。同样至关重要的是,浪潮信息在软硬协同系统优化上的持续投入。2021年,浪潮信息曾发布中文巨量模型「源1.0」,其参数规模为2457亿,积累了深厚的模型训练和推理优化经验。这种软硬协同的创新,同样体现在元脑SD200的PD分离框架,未来可进一步挖掘算力芯片潜力,提高利用率。正如赵帅所强调的,开放生态是打破性能瓶颈,推动产业发展的关键。通过开放超节点架构,浪潮信息不仅提升了自身产品的竞争力,还拉动了整个产业链的协同创新。元脑SD200的开放设计,让更多硬件厂商、软件开发者参与其中,共同优化算力与模型的适配效率。浪潮信息的开放战略,以应用为导向,以系统为核心,聚焦在当前技术、生态、成本约束下,为用户侧创造最大的价值。这种系统化思维贯穿于超节点技术的研发与应用中。这也是浪潮信息做开放计算,开放生态的一个核心。在超节点架构和开源生态的双轮驱动下,浪潮信息正引领AI算力基础设施向开放化、标准化、协同化迈进。元脑SD200的成功发布,以开源为基石,将为千行百业智能化转型注入不竭的动力。

内容中包含的图片若涉及版权问题,请及时与我们联系删除