
在游戏开发工作室中,动画师常常面临这样的困扰:为了让角色能更自然的“走路”“转圈”,不得不反复微调骨骼或者逐帧手动摆出几十个姿势。
如果只需一句指令,比如“一个人走两步,然后跳起来”,就能自动生成流畅逼真的3D动作,动画制作的方式将被彻底改写。
为此,北京大学提出了ReMoMask:一种全新的基于检索增强生成的Text-to-Motion框架。它是一个集成三项关键创新的统一框架:(1)基于动量的双向文本-动作模型,通过动量队列将负样本的尺度与批次大小解耦,显著提高了跨模态检索精度;(2)语义时空注意力机制,在部件级融合过程中强制执行生物力学约束,消除异步伪影;(3)RAG-无分类器引导结合轻微的无条件生成以增强泛化能力。
基于MoMask的RVQ-VAE,ReMoMask在最少步骤内高效生成时间连贯的动作。
在标准基准测试上的大量实验表明,ReMoMask达到了最先进的性能,与之前的SOTA方法RAG-T2M相比,在HumanML3D和KIT-ML上分别实现了3.88%和10.97%的FID分数提升。
ReMoMask整体架构
人体运动生成因其广泛适用于游戏、电影制作、虚拟现实和机器人等领域而备受关注。近年来,相关研究致力于合成多样且逼真的运动,以降低手动动画成本并提升内容创作效率。传统方法包括两个方向,t2m模型和RAG-t2m模型。
虽然传统的t2m模型能够生成较为精确的动作,而RAG-t2m模型则进一步提升了生成的动作的多样性,但这两类方法仍然面临两个核心挑战(如图1):
问题一:负样本太少。因为动作检索器是用小批量数据训练的,模型见到的“错误样本”太有限,学到的表示就不够稳健。
问题二:信息融合太粗糙。将动作序列离散化为1Dtoken,并将文本条件和检索知识直接拼接到1Dtoken上,模型没法深度理解文字-时空-检索知识之间的联系。
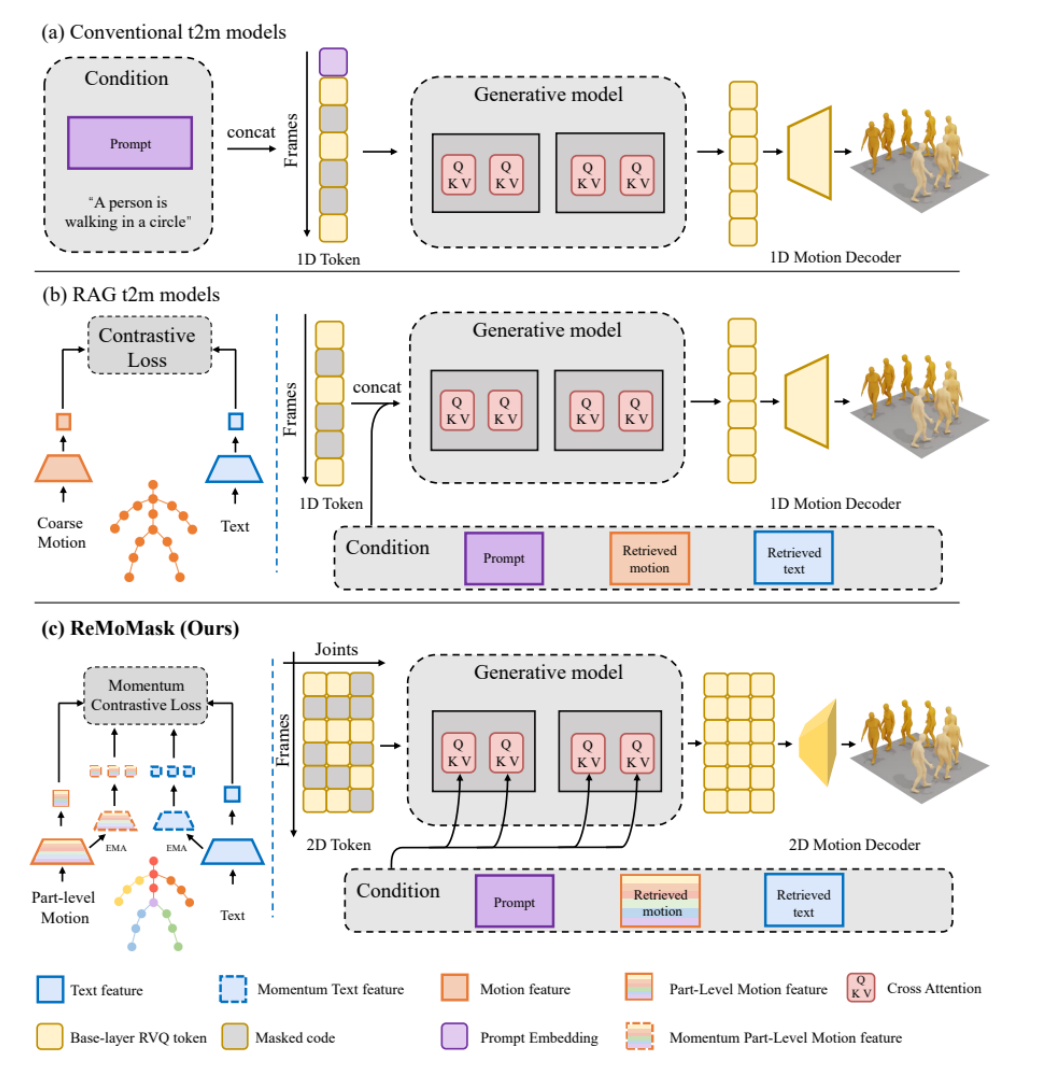
△图1 现有t2m方法对比
团队基于以上问题,研究新的RAG-t2m训练范式,既能支持更大规模的负样本,又能实现更强的信息融合机制。
核心方法
为了同时保证动作的时间动态和空间结构质量,团队首先通过2D RVQ-VAE编码器将整段动作量化为二维时空token map。
生成过程中,从全掩码的二维token map开始,ReMoMask使用细粒度双向动量文本-动作检索器(Part-Level BMM Retriever)提取相关的文本与动作特征。
该检索器通过双向动量建模(BMM)训练,从而构建了一个大规模的负样本池,提升了检索效果。
这些检索到的特征被输入到掩码Transformer中,并通过语义时空注意力(SSTA)融合,实现强语义对齐,为核心动作结构的重建提供指导。
最后,残差Transformer对动作细节进行精修,生成的隐空间动作向量再通过2D RVQ-VAE解码器恢复为最终的动作序列。
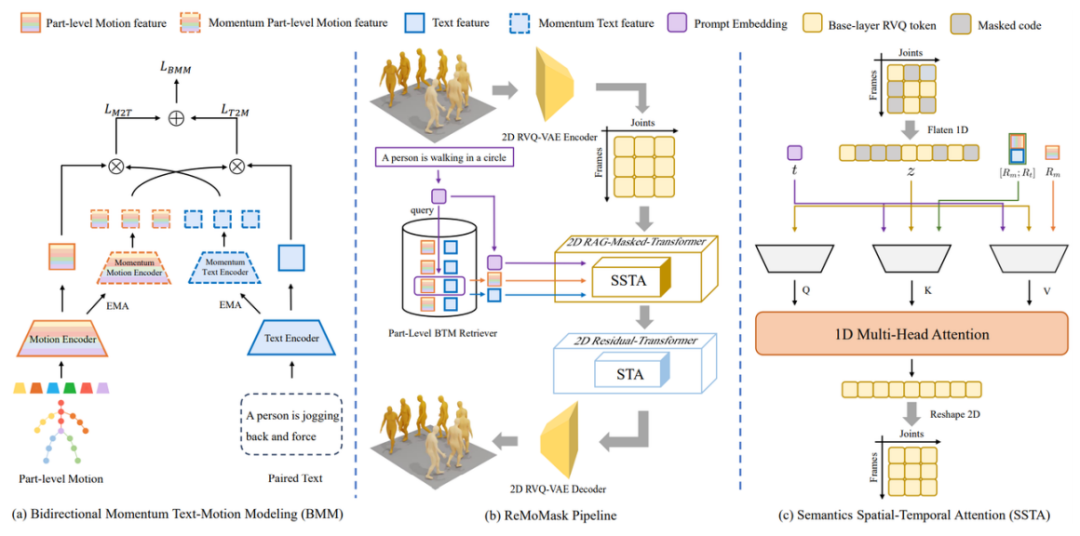
△图2 ReMoMask框架图
双向动量建模(BMM)
BMM采用两套动量编码器,分别维护两个负样本队列,用于存放文本和动作的负样本。
在训练的每一步,当前小批量样本通过动量编码器编码得到的负样本会被加入队列,同时最早的样本则从队列中移除。这样的设计将负样本池的规模与小批量大小解耦,允许对比学习利用更大规模的负样本集。
此外,这两套动量编码器通过对对应的在线编码器进行指数移动平均更新,从而保证负样本在时间上的一致性和稳定性。
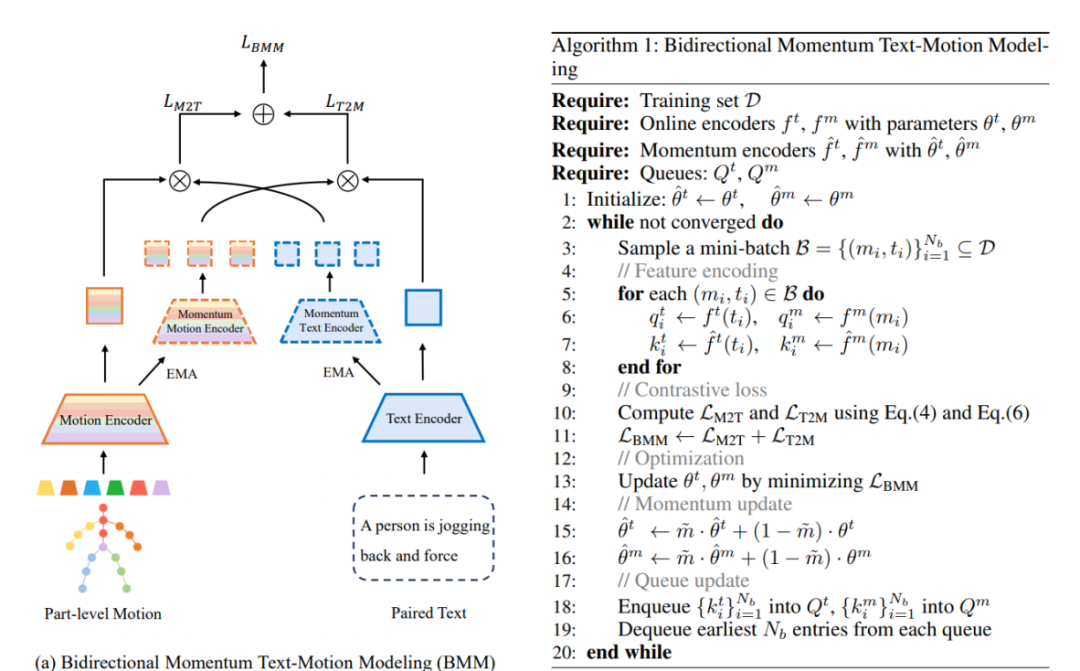
△图3 BMM示意图与伪算法
语义时空注意力(SSTA)
语义时空注意力(SSTA)机制区别于以往仅生成一维token map、忽视关节间空间关系的VQ量化方法。SSTA通过二维RVQ-VAE将运动序列编码为二维token map,同时捕捉时间动态特征并聚合空间信息。
在后续的生成阶段,该二维token map会被展平,并通过重新定义Transformer层中的Q、K、V矩阵,与文本嵌入、检索到的文本特征以及检索到的运动特征进行融合。
与简单的条件拼接方式相比,这一高效的信息融合机制能够在文本引导、检索知识、运动的时间动态及空间结构之间实现更全面的对齐,从而同时提升生成的精确性与泛化能力。
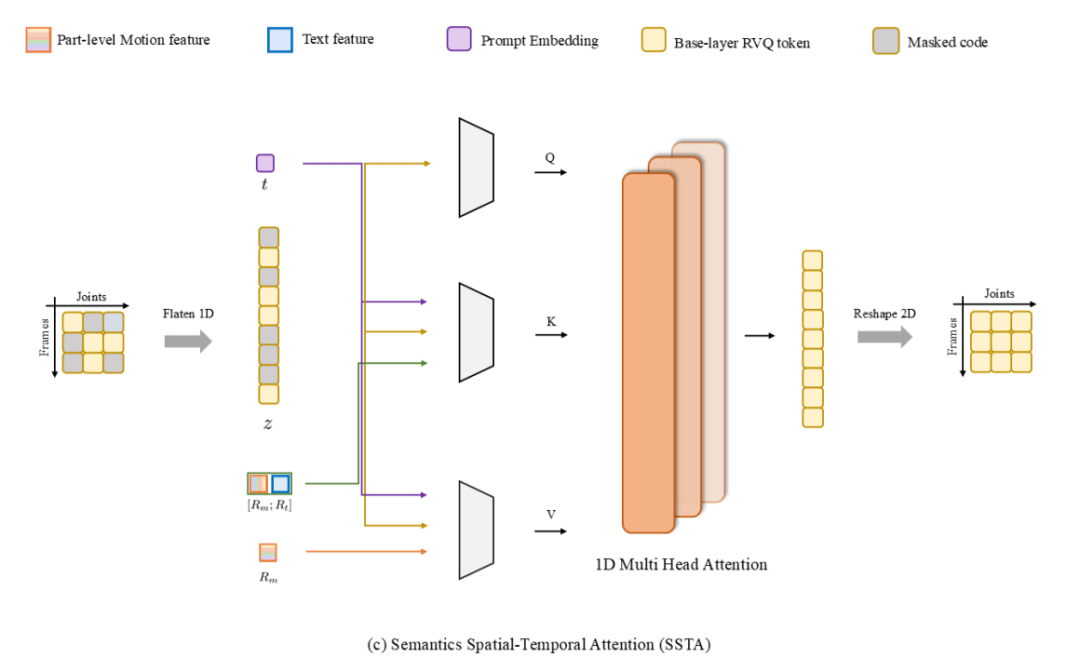
△图4 SSTA示意图
性能与效果
性能优势
研究团队在生成和检索两大方向上对方法进行了验证,并在主流基准数据集HumanML3D和KIT-ML上开展了全面评测。
在动作生成任务中,ReMoMask框架在R-Precision和FID等核心指标上均取得了优异表现:在HumanML3D上生成动作的MM DIST为2.865,超过当前先进的传统T2M方法;在KIT-ML上生成动作的FID达到0.138,优于现有的SOTA RAG-T2M方法。
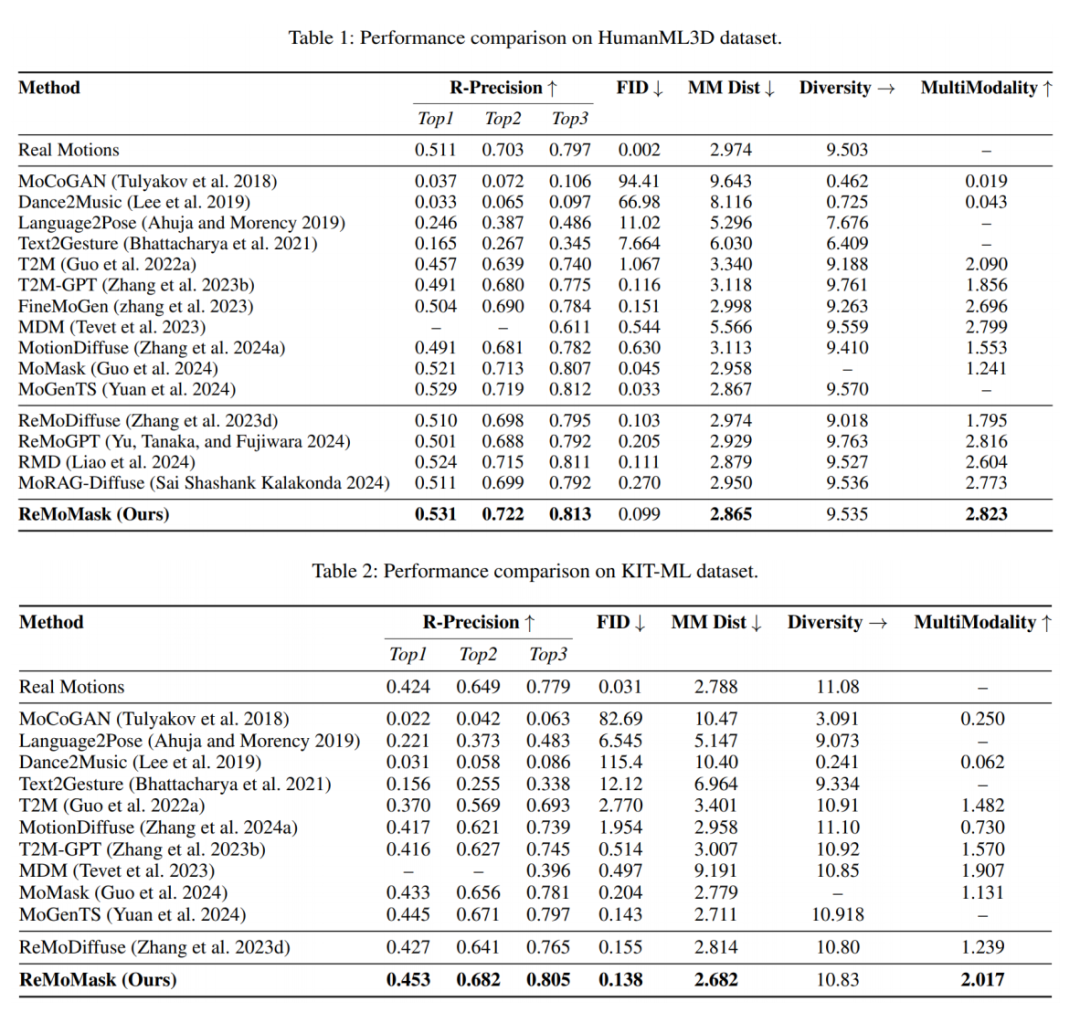
△表1 动作生成实验-实验结果
在两个检索任务中,R1、R2、R3指标都取得了SOTA水平,说明ReMoMask的跨模态检索能力表现出色。
△表2 动作-文本跨模态检索实验-实验结果
效果展示
图5是ReMoMask生成的一些动作示例,可以观察到ReMoMask生成的动作序列连贯且符合指令要求。
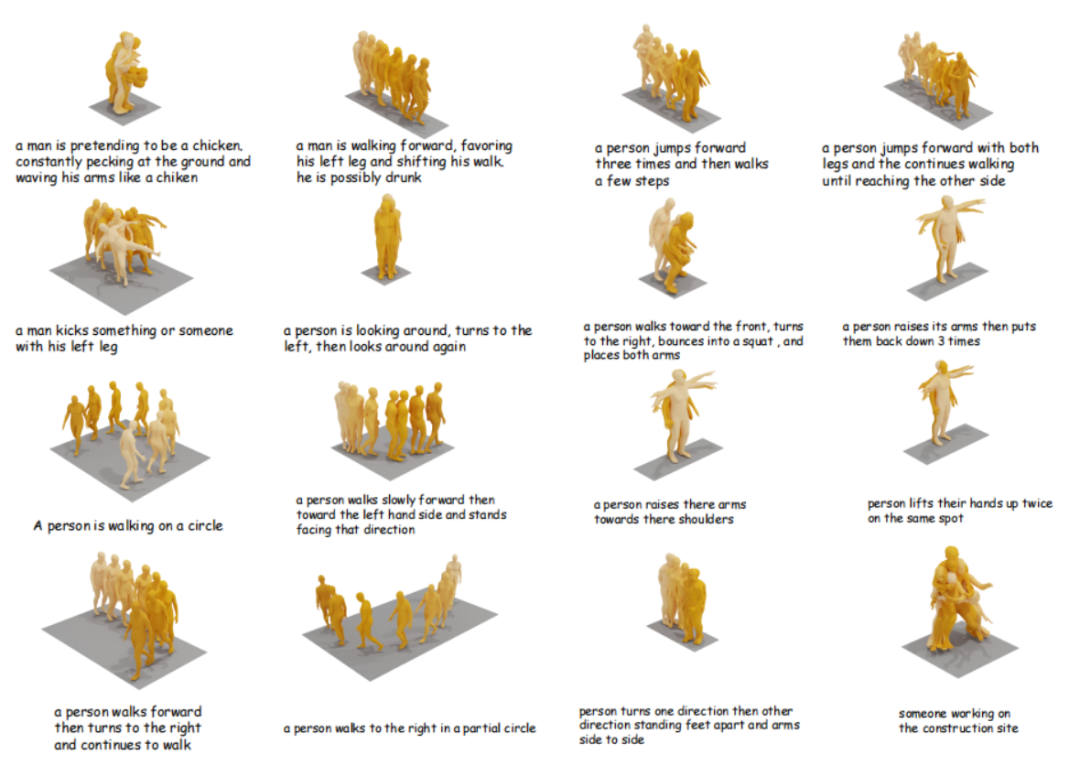
△图5 ReMoMask生成的动作的可视化效果
研究团队还将其ReMoMask的可视化效果与其他主流模型进行比较,并以问卷形式收集了测试参与者的意见。图6和图7结果显示较多的测试者认为ReMoMask所生成的动作序列质量较高且符合文本描述。
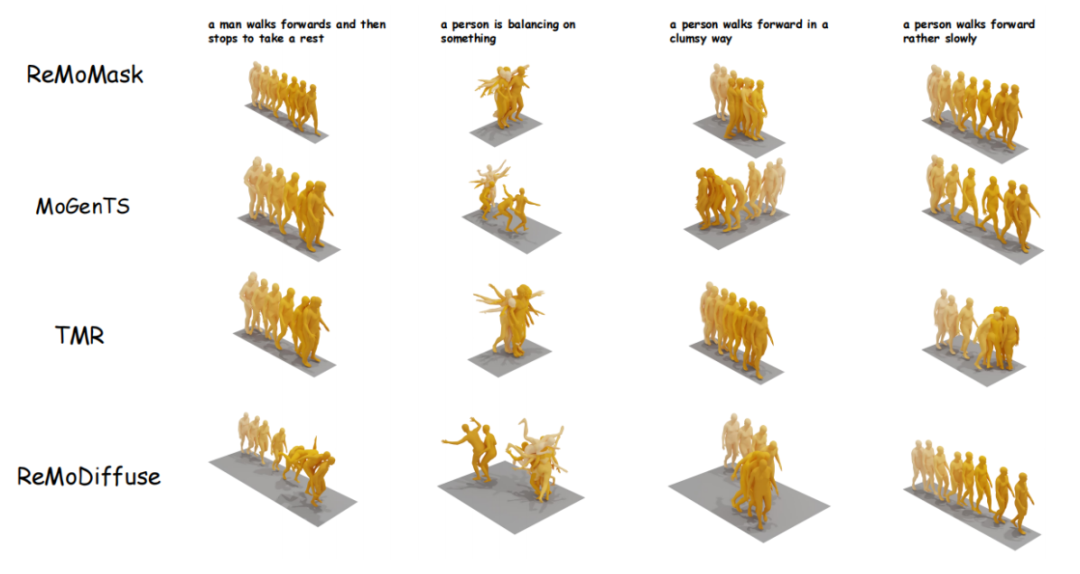
△图6 ReMoMask与主流模型的可视化效果对比
△图7 用户研究结果,左图为动作-质量用户研究,右图为文本-动作相关性用户研究
论文链接:https://arxiv.org/abs/2508.02605
GitHub:https://github.com/AIGeeksGroup/ReMoMask
项目主页:https://aigeeksgroup.github.io/ReMoMask
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
