
当大模型把人类曾经的终极考题变成日常练习,AI的奔跑却悄悄瘸了腿——
训练能力突飞猛进,验证答案的本事却成了拖后腿的短板。
为此,上海AI Lab和澳门大学联合发布通用答案验证模型CompassVerifier与评测集VerifierBench。填补了Verifier领域没有建立验证->提升->验证的循环迭代体系的空白。

让AI在下半场中终于能迈开训练与验证的两条腿往前冲。
AI的下半场应该两条腿跑步
随着OpenAI o系列,DeepSeek R1以及马斯克新发的Grok-4等模型慢慢让“人类最后的考试”变成 “大模型的上一次考试”,RL在推理模型上的胜利貌似为AGI的道路添加了一块厚厚的基石。
强推理模型在人类顶级水平竞赛上大杀四方,屡次超过人类顶级专家的现在,我们不禁要思考,AI的上半场是不是已经结束了,下半场的游戏又将如何开始。
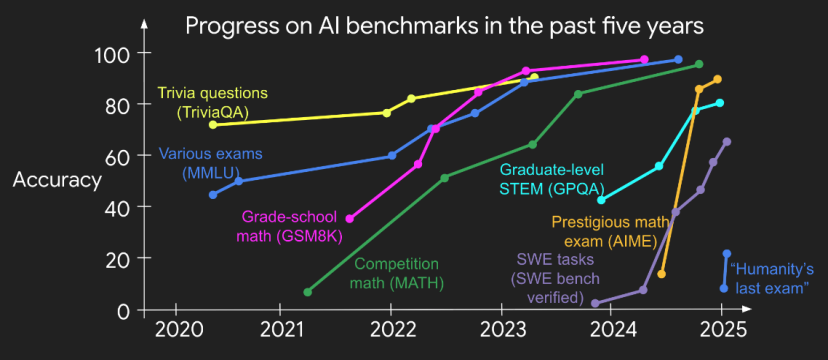 △图片来自Openai前研究员Jason Wei,高难度数据集正在迅速被模型们“吞噬殆尽”
△图片来自Openai前研究员Jason Wei,高难度数据集正在迅速被模型们“吞噬殆尽”
最近,来自清华姚班的姚顺雨提出了他对AI下半场的思考:
那么接下来会发生什么?人工智能的“下半场”——从现在开始——将从解决问题转向定义问题。在这个新时代,评估变得比训练更重要。我们不再只是问“我们能训练一个模型来解决X问题吗?”,而是问“我们应该训练人工智能做什么?我们如何衡量真正的进展?”为了在“下半场”蓬勃发展,我们需要及时转变思维方式和技能,或许更接近产品经理的水平。
OpenAI的前研究员Jason Wei也在他最新的Blog中提出验证者定律,他发现几乎任何可测量的事物都可以被优化。
用强化学习(RL)的术语来说,验证解决方案的能力等同于创建强化学习环境的能力。因此,我们有:
训练AI解决某个任务的难易程度与该任务的可验证性成正比。所有可解决且易于验证的任务,都将被AI解决。
我们可以把AI开发想象成一场射击比赛。
过去,我们痴迷于优化射手(模型)的射击技巧(训练算法)。但现在我们发现,真正决定胜负的,首先是“定义靶心”(定义问题),其次是拥有一套清晰的计分规则(评估体系)。
从根本上说,这位射手的进步速度,不可能超过他看清自己射击结果的速度。同理,AI的进化边界,被“结果验证”的速度和客观性牢牢锁定了。
这解释了为何AI在规则明确、结果清晰的游戏中能超越人类,但在需要复杂、主观鉴赏的领域却进展缓慢。
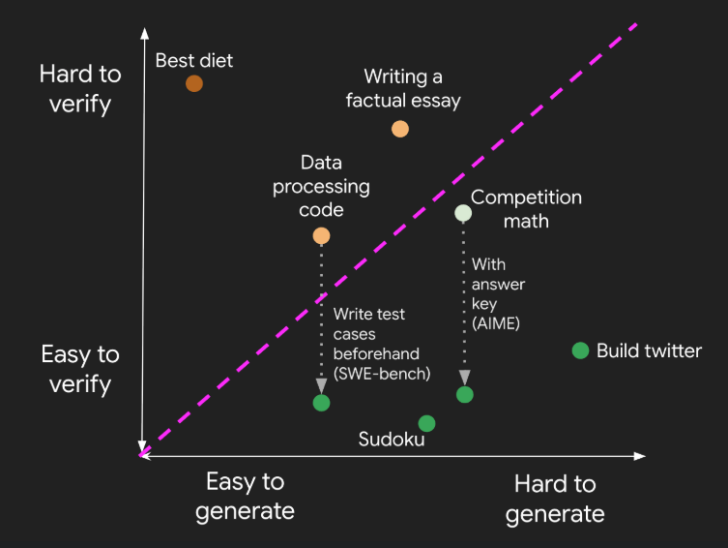 △通过引入额外信息来解决模型验证中不确定性
△通过引入额外信息来解决模型验证中不确定性
那么如何让验证更加容易,从而推进模型能力在多领域问题上的训练与提升呢?
在大语言模型(LLM)飞速发展的今天,从数学推理到知识问答,模型的能力边界不断拓展,模型的训练数据与范式日益繁杂。
然而,如何客观、高效地验证这些模型输出的正确性,始终没有获得足够且深入的探索。
如果说模型在奔向 AGI 的道路中,一条腿是训练,那另一条腿必然是验证,目前的训练范式下,大模型却往往是在跛着脚前进。
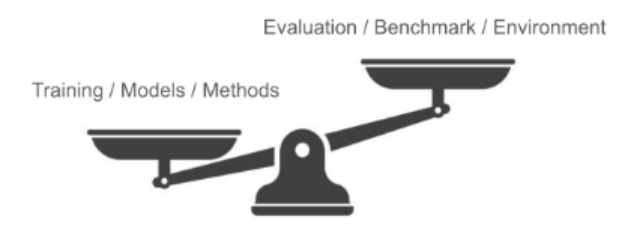 △验证与训练间的不平衡现象
△验证与训练间的不平衡现象
为了帮助大模型快步跑进AI下半场,来自上海AI Lab和澳门大学的研究团队发现,目前大模型验证领域缺乏合理的迭代体系,很长一段时间以来社区的目光过于集中在大模型的推理能力提升上,但却忽视了大模型对答案正确性的验证能力也是大模型能力的一环。
具体的,首先是缺乏性能强的,具有跨领域答案验证能力的验证模型,其次模型的答案验证能力无法被有效评估。
验证->提升->验证的循环迭代体系还没有在Verifier领域被建立。
为了填补这一空白,团队基于OpenCompass这一强大的开源评测体系,推出了通用答案验证模型 CompassVerifier以及答案验证评测集VerifierBench。
CompassVerifier:助力大语言模型训练测评“两条腿跑步”
当前LLM的答案验证方法深陷双重困境:
第一,规则依赖的脆弱性:传统方法依赖人工定制正则匹配规则,例如提取”The answer is”后的内容进行比对,或用专用工具校验数学公式。
但面对多步骤问题、复杂公式、序列答案等形式,这些规则稍遇格式变化就可能会失效。另外,基于规则的方式难以扩展,如基于数学领域的规则验证器无法简单迁移到化学领域,手动适配费时费力。
其次,通用模型的不可靠性:用GPT-4o、DeepSeek-V3等大模型作为验证器时,需要为不同任务反复调整提示词,且模型容易陷入”幻觉”——例如将语义等价的不同公式判定为错误,或因推理链中的细微偏差否定正确答案。
另外,哪怕使用强推理模型用同样的Prompt进行验证,也会存在不同模型的偏好而导致判罚尺度不同而导致完全不同的验证结果(如近似答案是否正确,遗漏了非关键内容,如数值单位是否正确)。
最后,大多数研究者只能使用小尺寸的开源模型进行答案验证,这也在一定程度上限制了验证的性能。
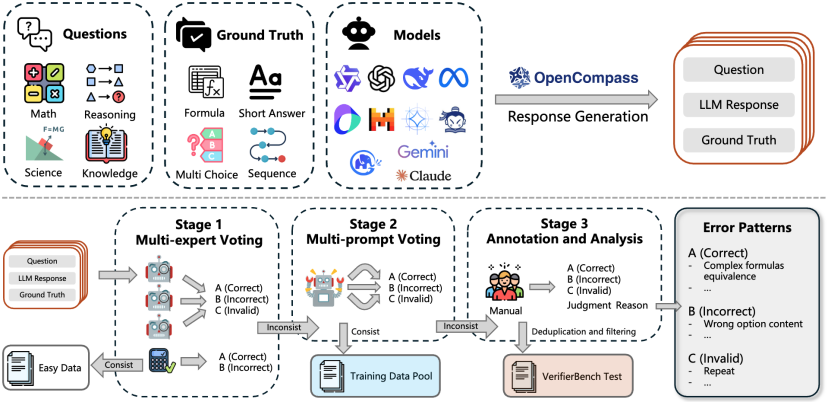 △CompassVerifier&VerifierBench构建pipeline
△CompassVerifier&VerifierBench构建pipeline
在初期对通用模型的验证能力调研中,以Qwen2.5-32B对MATH数据集的验证为例,研究人员发现总有大约 3%~5%的样例模型会重复判断错误,而这些疑难Case可能就是导致通用模型验证能力不稳定的根本因素。
为了全面筛选出这些疑难Case,研究团队基于OpenCompass框架,从50多个大语言模型在15个数据集上的一百余万份回复中,通过一个大规模、多阶段的筛选流程精选数据:
借助以上流程,研究人员训练收集得到了通用答案验证模型CompassVerifier以及答案验证评测集VerifierBench。
CompassVerifier是一个多域通用、高鲁棒性的答案验证器,其核心设计理念是轻量而强大——它基于Qwen系列模型优化,参数规模从3B到32B不等,却能在数学、知识、科学推理等多领域实现超越通用大模型的验证精度。
研究团队使用了三种方式进行数据增强与数据合成,进一步提升答案验证能力。
研究团队通过人工分析5000余个验证失败案例,总结出20余种高频错误模式(如公式等价性误判、格式严苛性偏差等),并据此针对性的合成多领域的训练数据。
例如,对于标准答案为”A. 北京”的选择题,当模型常将”A. 上海”判定为等价时,增强数据会刻意纳入此类选项正确但内容错误的样例,纠正模型对于选择题的答案验证。
针对公式验证这一难点,CompassVerifier借助强推理模型对常见科学学科生成大量等价公式变体(如符号重排、精度转换、整数与分数互转等),并进一步通过自验证判断公式的的数学等价性,最终构建为增强训练数据。
这使得模型能轻松识别x²+2x+1与(x+1)²的等价关系,即使表达方式截然不同。
通过整合20余种任务类型的提示词变体(如零样本/少样本提示、不同语言风格指令),同时在训练数据中整合了不同的Prompt和推理路径。
CompassVerifier可以实现直接答案验证和带简短推理过程的答案验证,摆脱了对特定提示格式的依赖,让用户可以了解到其打分的具体原因。
无论是中文问答、英文数学题,还是混合格式的多步骤问题,使用不同的提示词输入它都能保持稳定的验证性能。
同时,研究团队也专门针对Large Reasoning Model (LRM)的模型回复进行了增强,对同一大模型回复通过截断不同比例的思考过程、去除思考过程、替换思考标签等方式,使用同一验证输出,迫使模型只关注最终的结论和答案部分,忽略思考过程的任何偏差和波动。
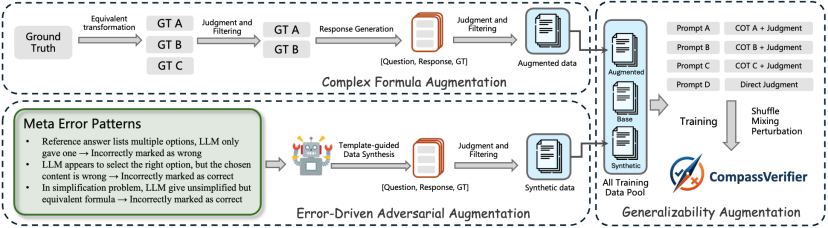 △CompassVerifier 针对性数据增强
△CompassVerifier 针对性数据增强
VerifierBench:针对验证模型的多领域、高难度基准
社区一直缺乏一个针对可验证答案、标准化、高难度的基准来衡量不同验证方法的验证能力,无法衡量不同模型的性能。
这使得研究者在使用通用LLM模型进行答案验证时,只能根据经验或者是模型的尺寸来选择模型。
为了系统评估验证器的能力,研究团队构建了包含2817个经由人类专家标注的高质量的 VerifierBench基准。该数据集覆盖三大特点:
- 多域覆盖
多领域、高精准、鲁棒的答案验证能力
在VerifierBench上,CompassVerifier-32B(Based Qwen2.5) 的平均准确率达到90.8%,F1分数87.7%,超过DeepSeek-V3和GPT-4等大尺寸模型。
即使是3B的轻量版本,也能超越大规模的通用模型,展现出极高的参数效率。
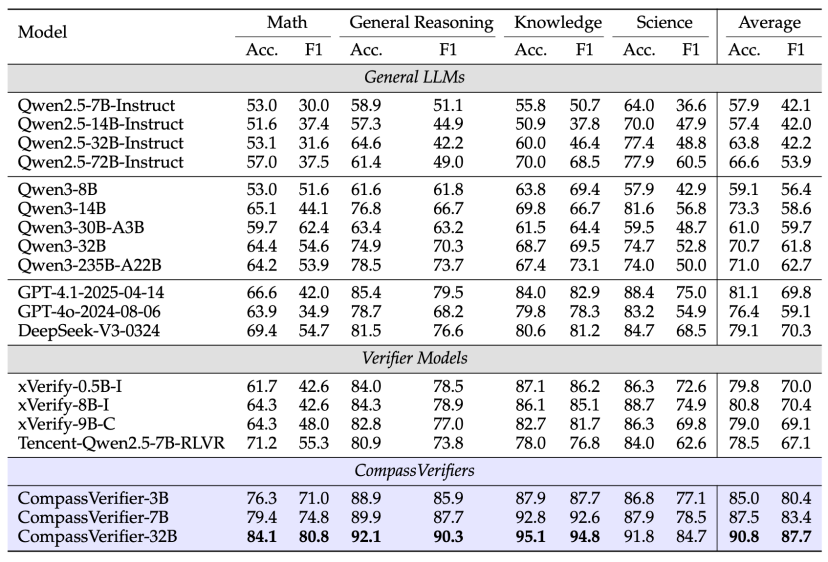 △VerifierBench 效果对比
△VerifierBench 效果对比
在同期公开的VerifyBench基准测试中,CompassVerifier同样展现出全面领先的性能,其表现不仅超越了不同参数规模的通用大模型,也优于其他专用答案验证模型,充分彰显了该模型在领域外场景的强大泛化能力与稳健性。
值得注意的是,即便面对未经训练的全新指令,CompassVerifier仍能保持高性能水平,进一步印证了其在复杂验证场景中的可靠性。
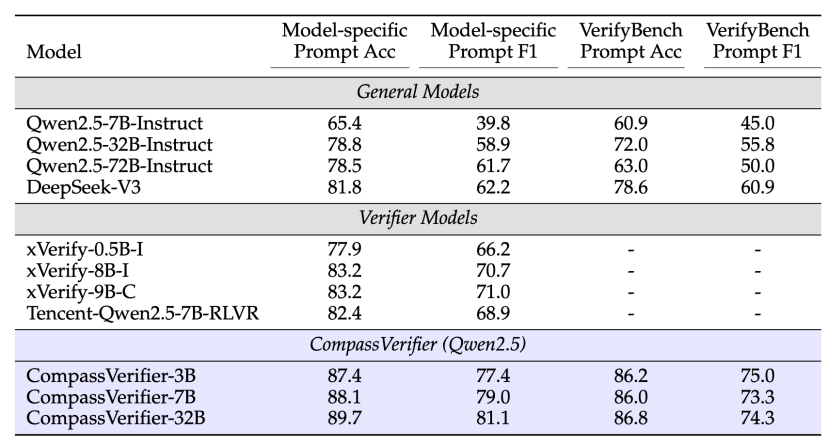
△VerifyBench 效果对比
从Evaluation到RLVR:验证器的“双重身份”
CompassVerifier的价值远不止于评估环节,它更能直接作为强化学习(RL)的奖励模型,为大语言模型的迭代优化提供精准反馈。
在数学推理任务中,研究团队采用GRPO算法进行训练时,以CompassVerifier作为奖励模型,使Qwen3-4B-Base模型在AIME24数据集上的性能提升18.5 分。
在MATH500数据集上提升49.2分,其提升幅度远超基于规则的Math-Verify工具及通用大模型作为奖励模型时的效果。
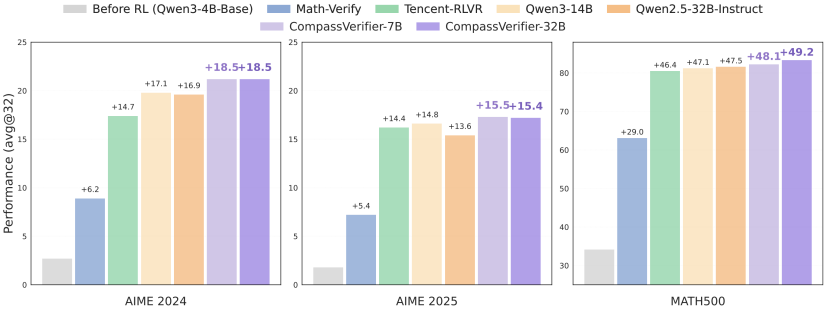 △采用不同 Verifier 模型 GRPO 效果对比
△采用不同 Verifier 模型 GRPO 效果对比
这一显著优势源于CompassVerifier所能提供的奖励信号具备更高的精准度与鲁棒性。
它不仅能直接判定答案的正误,也可以精准识别无效响应(如截断输出、重复文本等)并施加更严厉的惩罚,有效避免模型在训练中通过 “走捷径” 规避复杂推理。
可以说,CompassVerifier为数学、知识问答、科学推理等具有明确标准答案的多领域强化学习训练, 也提供了更为强大的技术支撑。
随着AI下半场的开始,AI大模型的进步方式可能慢慢会超出人类所理解的学习范式。
在不远的将来,模型可能完全根据自己的理解来进行自我Verify而非借助人类给予的“Golden”标签,模型可能会完成高效且高质量的Self-verify -> Self-improve -> Self-verify …
就像人类跑步时的左脚右脚一样,以实现真正的AGI,完成AI自己的马拉松。
论文地址:https://arxiv.org/abs/2508.03686
项目主页:https://open-compass.github.io/CompassVerifier
Github:https://github.com/open-compass/CompassVerifier
Model & Dataset:https://huggingface.co/collections/opencompass/compassverifier-686e5a25e8672e603b17c666
参考链接:The Second Half
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
