
Multimodal reasoning, where models integrate and interpret information from multiple sources such as text, images, and diagrams, is a frontier challenge in AI. VL-Cogito is a state-of-the-art Multimodal Large Language Model (MLLM) proposed by DAMO Academy (Alibaba Group) and partners, introducing a robust reinforcement learning pipeline that fundamentally upgrades the reasoning skills of large models across mathematics, science, logic, charts, and general understanding.
Core Innovations
VL-Cogito’s unique approach centers around the Progressive Curriculum Reinforcement Learning (PCuRL) framework, engineered to systematically overcome the instability and domain gaps endemic to multimodal reasoning. The framework includes two breakthrough innovations:
- Online Difficulty Soft Weighting (ODSW): This mechanism assigns dynamic weights to training samples according to their difficulty and the model’s evolving capabilities. Rather than rigidly filtering out “easy” or “hard” samples, ODSW ensures each prompt contributes appropriately to gradient updates—enabling the model to progress from clear cases to intricate, challenging ones through a continuous curriculum. Three variants tune the focus for easy, medium, or hard stages using a piecewise function based on rollout accuracy, guided by learnability theory and empirical distribution of task difficulty.Dynamic Length Reward (DyLR): Traditional length rewards in RL-based reasoning models set a static target, which fails to consider task complexity and encourages unnecessary verbosity. DyLR solves this by calculating an ideal target length per prompt, estimated via the average length of correct rollout samples for each question. Short, rapid reasoning is promoted for easy tasks, while complex ones incentivize deeper, multi-step exploration, perfectly balancing efficiency and correctness.
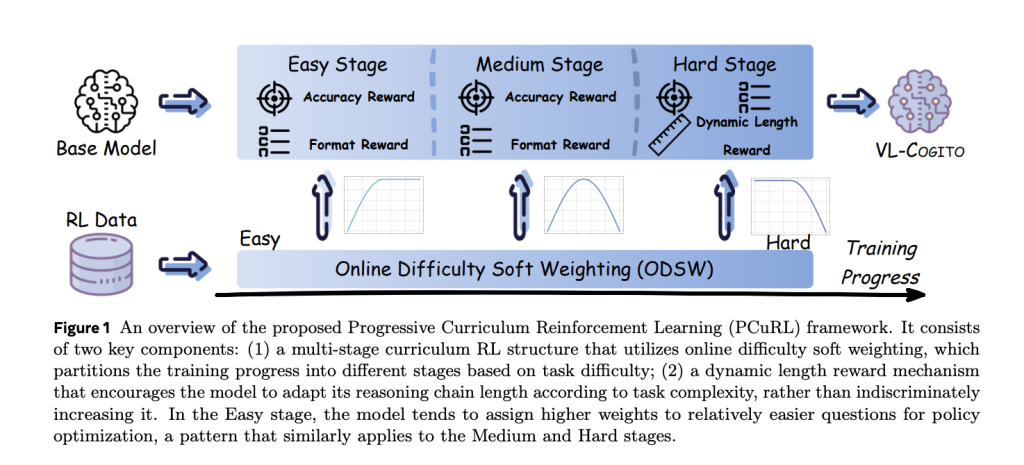
Training Pipeline
VL-Cogito’s RL post-training starts directly from the Qwen2.5-VL-Instruct-7B backbone, with no initial supervised fine-tuning (SFT) cold start required. The PCuRL process is explicitly divided into three sequential RL stages: easy, medium, and hard. In each stage:
- The same dataset is shuffled, exposing the model to various generalization challenges.ODSW’s weighting function for that stage biases gradient updates towards the target difficulty.In the hard stage, DyLR is triggered to encourage adaptive reasoning chain expansion.
Technical setup details:
- AdamW optimizer, LR=1e-6, DeepSpeed-ZeRO3.Rollout batch size: 512; global batch size: 128; sequence length: 4,096; KL divergence loss: 1e-3; 16 response samples per prompt; temperature: 1.0.Reward hyperparameters: α=1, β=0.5, γ=1, w=0.25 (penalty for zero-accuracy prompts).
Dataset Curation and RL Data Sampling
A meticulously curated training set covers 23 open-source multimodal datasets across six task categories: Mathematical Reasoning, Logical Reasoning, Counting, Science Reasoning, Chart Understanding, and General Image Understanding.
- All samples are reformulated to open-ended QA formats to prevent superficial multiple-choice cue exploitation.Difficulty sampling: Qwen2.5-VL-7B-Instruct is trialed; any sample passed by it with ≥50% accuracy over 8 runs is dropped, guaranteeing that only genuinely challenging tasks remain.
Evaluation and Benchmark Results
Performance Across Benchmarks
VL-Cogito is benchmarked against both general-purpose and reasoning-oriented MLLMs on a ten-task panel, including datasets like Geometry@3K, MathVerse, MathVista, ChartQA, ScienceQA, MMMU, EMMA, and MMStar.
- Absolute accuracy gains over the backbone: +7.6% on Geometry@3K, +5.5% on MathVista, +4.9% on LogicVista, +2.2% on ScienceQA, +4.5% on EMMA, +3.8% on MMStar.State-of-the-art results on 6/10 benchmarks: VL-Cogito either leads or matches top results, especially on rigorous math and scientific tasks. Models “cold-started” with SFT or forced rethinking strategies do not surpass its robust, curriculum-based RL.
| Model | Geo3K | MathVerse | MathVista | MathVision | LogicVista | ChartQA | SciQA | MMMU | EMMA | MMStar |
|---|---|---|---|---|---|---|---|---|---|---|
| VL-Cogito (7B) | 68.7 | 53.3 | 74.8 | 30.7 | 48.9 | 83.4 | 87.6 | 52.6 | 29.1 | 66.3 |
| VL-Rethinker (7B) | 67.7 | 54.6 | 73.7 | 30.1 | 45.7 | 83.5 | 86.7 | 52.9 | 28.6 | 64.2 |
| MM-Eureka (8B) | 67.2 | 52.3 | 73.4 | 29.4 | 47.1 | 82.7 | 86.4 | 52.3 | 27.4 | 64.7 |
| Qwen2.5-VL (7B) | 61.6 | 50.4 | 69.3 | 28.7 | 44.0 | 82.4 | 85.4 | 50.9 | 24.6 | 62.5 |
Component-wise Ablation
- Curriculum RL alone lifts average scores by +0.8% over vanilla GRPO.Dynamic length reward further boosts performance, especially in hard math domains.ODSW consistently outperforms binary hard sample filtering, especially when training data is imbalanced or skewed.
Reasoning Efficiency and Training Dynamics
- Dynamic rewards yield higher average accuracy and better token efficiency than fixed-length cosine rewards. Adaptive length emerges as longer for math and logic tasks, shorter for science and general understanding, precisely as intended.PCuRL’s hard stage induces a spike in reasoning length and validation accuracy, surpassing vanilla GRPO whose accuracy plateaus despite static output length.
Case Studies
VL-Cogito exhibits detailed, self-reflective, stepwise reasoning. For math, the model decomposes solutions into granular chains and actively corrects missteps, a behavior instilled by RL verification and advantage estimation[1, Figure 5]. On classification-style problems (e.g., identifying decomposers or skyscrapers in images), it methodically considers each option before boxing the answer, demonstrating strong multimodal comprehension and process reliability.

Insights and Impact
VL-Cogito’s systematic PCuRL pipeline validates several key insights:
- Learnability matters: Prompts with intermediate difficulty optimize model progress best.Exposure to challenge catalyzes deep reasoning: Over-emphasis on easy samples degenerates performance; progressive emphasis on harder samples builds durable analytic depth.Reward granularity is crucial: Combining correctness, format, and length facilitates nuanced, context-sensitive reasoning outputs.No-sft cold-start RL is feasible and highly effective: With PCuRL, models need not rely on expensive SFT warm-up.
Conclusion
VL-Cogito’s architecture and training innovations set a new standard for multimodal reasoning across diverse benchmarks. The design and empirical validation of progressive curriculum RL with dynamic length rewards point toward a general roadmap for robust reasoning in multimodal models.
 Discuss on Hacker News
Discuss on Hacker News  Join our ML Subreddit
Join our ML Subreddit  Sponsor us
Sponsor us Check out the Paper. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post VL-Cogito: Advancing Multimodal Reasoning with Progressive Curriculum Reinforcement Learning appeared first on MarkTechPost.
