
OpenAI周四(8/7)正式發表了GPT-5,ChatGPT版本採用統一系統架構,同時整合了快速回應與深度思考模式,並可透過即時路由器自主切換,也提高了整體的性能、效率與可靠性,GPT-5 API版本則大幅強化程式開發及代理任務,已被整合到OpenAI API平臺、Codex CLI、Microsoft 365 Copilot、GitHub Copilot及Azure AI Foundry上等平臺上。
根據OpenAI的說法,GPT-5提高了ChatGPT中最常見之3種用途的性能,包括寫作、程式設計與健康,亦於減少幻覺、強化指令遵循,以及減少阿諛奉承上有了重大改進。例如只需要一個提示就能生成美觀且回應訊速網站、應用程式及遊戲;在健康上它可主動標記潛在的問題並提出問題,也能有更精確與更可靠的回應;在文字上則具備更有意境的創作風格。
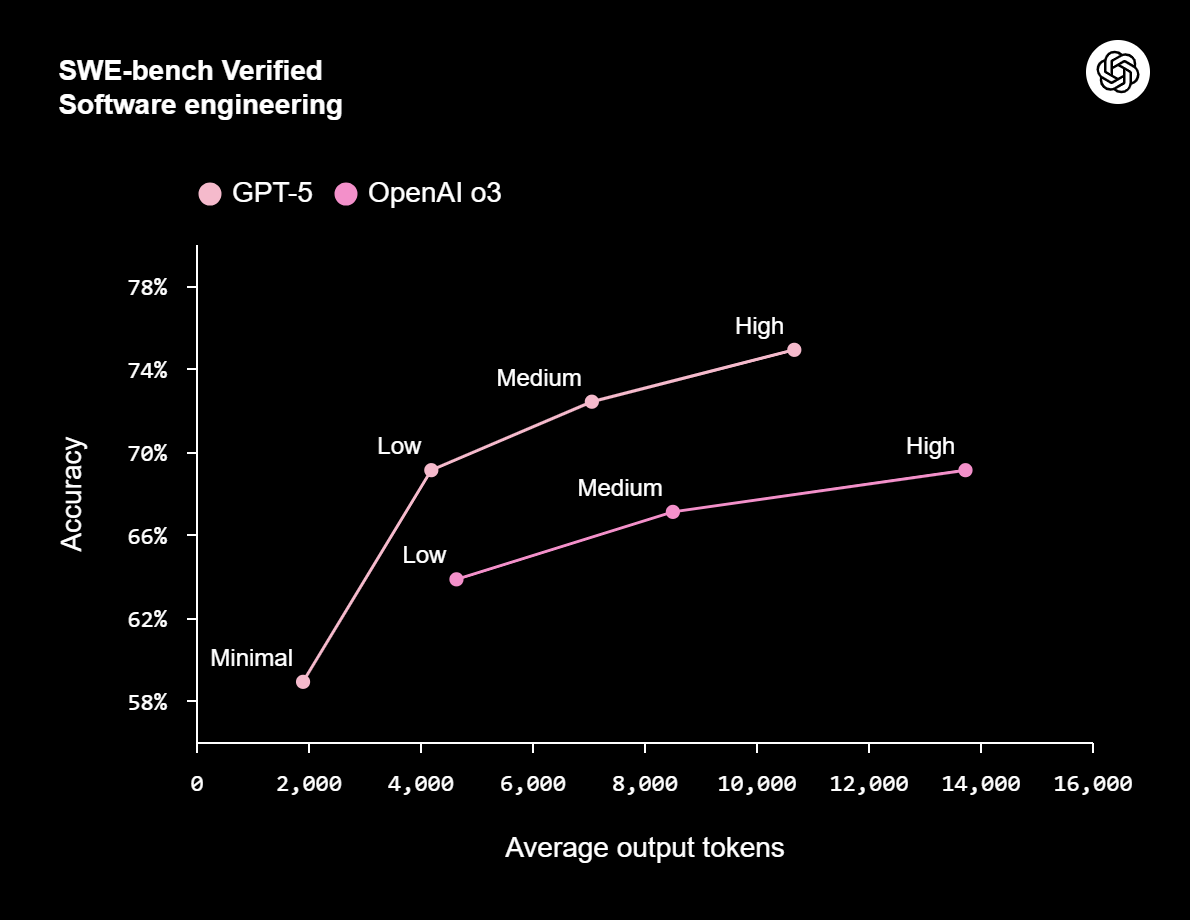
GPT-5在有關數學的AIME 2025基準測試分數為94.6%,與程式設計相關的SWE-bench Verified及Aider Polyglot分別達到74.9%與88%,涉及多模態理解的MMMU為84.2%,健康領域的HealthBench Hard為46.2%,以GPT-5 Pro進行科學推理的GPQA為88.4%。
圖片來源/OpenAI
相較於OpenAI o3,GPT-5的輸出Token少了50~80%;相較於GPT-4o,GPT-5的事實錯誤少了45%;在開放式的事實查詢中,GPT-5的幻覺率是OpenAI o3的1/6;在缺少圖片的多模態測試中,o3有超過86%的比例會給出虛假答案,GPT-5只有9%;GPT-5的諂媚回應也從GPT-4o的14.5%降至6%以下。
OpenAI還開始於GPT-5中預覽不同的聊天機器人個性,包括憤世嫉俗型(Cynic)、機器人型(Robot)、傾聽者型(Listener)與書呆子型(Nerd),初期僅支援文字聊天,之後將支援語音,使用者可自行於設定中調整。
而在程式設計上,OpenAI於內部測試GPT-5的前端開發,發現它有70%的時候都優於o3,輸出Token減少了22%,工具呼叫減少了45%,且性能更好。Windsurf說它的工具呼叫錯誤率比其它先進模型少了一半。
至於GPT-5在與代理任務有關的τ2-bench telecom基準測試分數為96/7%,Scale MultiChallenge為69.6%,長文本的檢索能力也優於o3及GPT-4.1,代表它能夠更可靠地呼叫並串聯各種工具。
GPT-5有3種API規格,包括GPT-5、GPT-5-mini與GPT-5-nano,每100萬個輸入Token的價格分別是1.25/0.25/0.05美元,輸出則是10/2/0.4美元。
有些媒體試用後認為GPT-5屬於重大更新,有些則覺得它比不上從GPT-3到GPT-4所帶來的驚喜,而根據路透社(Reuters)的報導,OpenAI內部正在討論如何讓員工手上的股票套現,且對該公司的估值高達5,000億美元。OpenAI在今年3月底宣布要融資400億美元,融資後的估值為3,000億美元。
