

关键词:词嵌入,巴别塔
“囫囵吞枣。”他慢慢念出来,清晰地发出每一个音节。接着,他翻到刻着英语那一面,念道:“To accept without thinking.”
银条开始嗡嗡作响。
他的舌头立刻膨胀起来,堵住了呼吸道......甜腻滋味充斥着他的口腔......香气浓郁、口感黏糊的蜜枣,熟得令人反胃。他快要被蜜枣噎死了。
上述片段节选自匡灵秀的小说《巴别塔》。小说中将白银作为魔法“中介”。银条的正反两面刻有不同语言,但相近语义的词语。如其原文所述:
银条的魔力藏在词语之中......就是语言中无法用词语表达的部分,在我们从一种语言转换到另一种语言的过程中丢失的那一部分。白银能捕捉到丢失的语义,将它转化成真实的存在。
针对这种翻译中的语义丢失,我很喜欢赫塔·米勒的一句话——“每一句话语都坐着别的眼睛。”在对比她家乡的罗马尼亚语和德语时,她以燕子为例子:
罗语的燕子,rindunica,“小排排坐”,是一个全新的视角,其内涵比德语中的燕子要丰富得多。一个鸟的名字,同时为我们描绘出这样一幅图景:燕子们黑压压地并排坐在铁丝上。没有接触罗语前,每个夏天,我都会看到这样的风景。我为人们能如此美丽地称呼燕子而慨叹。
那么在中文的“燕”字中坐着的眼睛里看到的便是长而尖的翅膀,分叉的尾巴和高昂的鸟头。

燕字甲骨文
我曾经因此想过一个设定:一个侦探可以看到每一句话语背后的眼睛,并以此探案,直到一天她看到一段话语,背后有无数双眼睛在闪烁.......
作者手绘示意图
当然以上的设想还是充满着人类的某种别扭的自尊心。我相信给好数据,做好 fine tune,LLM 也可以生成“尸块”拼凑感不强,蕴含着独到视角和文化底蕴的文字。事实上,习惯于天天喂给 LLM 残骸的我,现在写的东西坐着的可能是 Gemini, deepseek, chatGPT 的眼睛。
(感兴趣的读者欢迎去两则“小说”更新的故事2中读读和这个设定类似的小说。)
回归正题,在我得知了以上两部作品后,一直想试试用代码实现“白银魔法”并捕捉“眼睛”的区别。
在代码的世界里,任何言语都可以都可以被嵌入到向量空间,细微的语义可以被不断增加的维数所度量。那么上述的想法“说人话”就是用词向量嵌入定义语言的加法和减法。虽然这几周我尝试了以后发现效果不佳,但是我还是决定写一篇博客把这个勉强完成的东西分享出来。

语义运算
想象语言由一些微小的基本语义元素构成,比如:
那么集合 (x, y) 就表示“女王”——同时包含“女性”和“君主”的语义。
1
数学定义

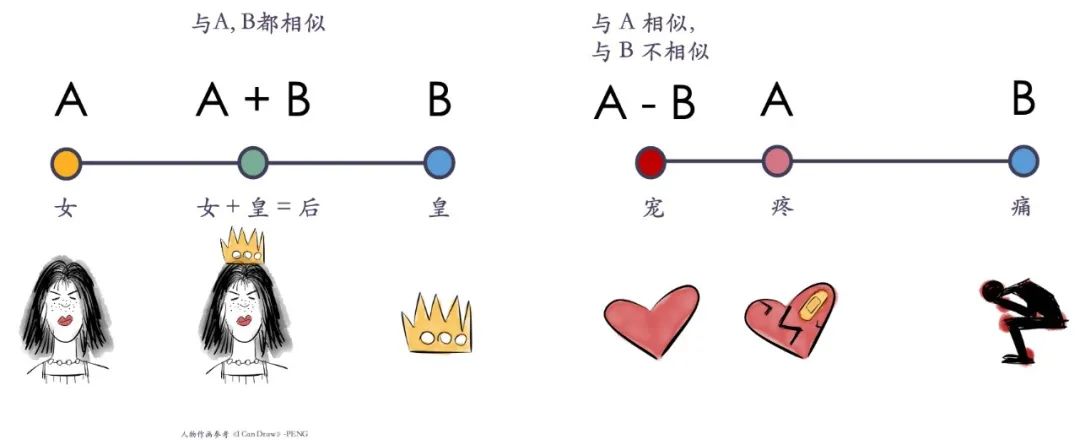
加法(A + B):语义的合并,即两者所有元素的集合(并集)。
例子:“女性”+“君主”=“女王”(包含两者的特征)。
减法(A - B):从 A 中移除 B 的元素(差集)。
例子:“女王”-“君主”≈“女性”。
2
词向量直接加减的局限性
直接用词向量加减(如经典的 king - man + woman ≈ queen)在某些例子中有效,但广义上效果不稳定。理论上,如果词向量中的每个数字都代表一个语义基元是否存在,那么并集更像是对每个对应的数字取最大值,而不是简单地相加。但这样仍然依赖词向量本身的物理意义。为了不依赖词向量的物理意义,可以使用基于相似性的语义运算。

基于相似性的语义运算
定义语义相似性(sim)为两词的交集元素数量除以并集元素数量(Jaccard 相似度)。基于此:
1
加法(A ∪ B)
寻找一个新词 C,使得:
C 与 A、B 的相似性尽可能接近(避免偏向某一方)。
在所有候选词中,C 与 A、B 的联合相似性最大。
数学表达:
在 A 和 B 大小一致的情况下,以上的优化目标中并集最大。一般情况下并集可以理解成两个集合的(加权)中点。
2
减法(A / B)
寻找一个新词 C,使得:
C 与 B 完全无关(相似性为零)。
在所有与 B 无关的词中,C 与 A 的相似性最高。
数学表达:
词向量模型选择与汉字语义运算
1
词向量模型的选择
我尝试了 Word2Vec、GloVe 等经典词嵌入模型,它们在经典例子(如 king - man + woman ≈ queen)上表现良好,但整体泛化效果一般。后来改用 BAAI/bge-large-en,效果有所提升,例如:
sun + moon = eclipse(日 + 月 = 日食)
earth - sky = soil(地 - 天 = 土)
sun + flower = sunflower(日 + 花 = 向日葵)
但仍有较多运算结果不合理,且由于英文词汇过多,因此我转向汉字运算。
2
汉字语义运算的优化

直接对汉字做 Embedding 效果一般,因为:
单个汉字可能对应多个语义(如“日”= sun/day)。
中文词嵌入通常基于词语而非单字,单字向量可能不够精准。
改进方法:
使用 peterolson/chinese-lexicon 获取汉字的多个英文定义(如“日” → ["sun", "day"])。
计算相似性时,取定义对的最大相似度(而非直接比较汉字向量)。
例如:比较“日”和“月”时,计算 max(sim("sun", "moon"), sim("day", "moon"), ...)。
运算结果定义采用了拆字(例如日+月=明)和基于相似性的语义运算的复合形式,最后的效果虽然仍然没有让人特别满意,但是也勉强可以接受。
作者手绘汉字运算示例
1
加法运算的例子(A + B)
除了“男+皇=君,女+皇=后”以外,
青+玉=碧(“青”是颜色,“玉”是质地,青绿色的玉石便是“碧”)
小+石=砾(“小”表示微小,“石”为石头,“砾”就是细碎的小石头)
思+慕=眷(“眷”的含义包含思慕,眷恋某人或某物)
2
减法运算的例子(A - B)
减法在语义上往往更加微妙,若 A、B、C 之间关联较弱,可能出现 A - B ≈ A - C 的情况,但若 A 与 B 高度相关,减法反而能精准提取差异,这是《巴别塔》里选择把翻译的误差具象化为魔法的原因。即使都是汉字,也会有如下有趣的例子:
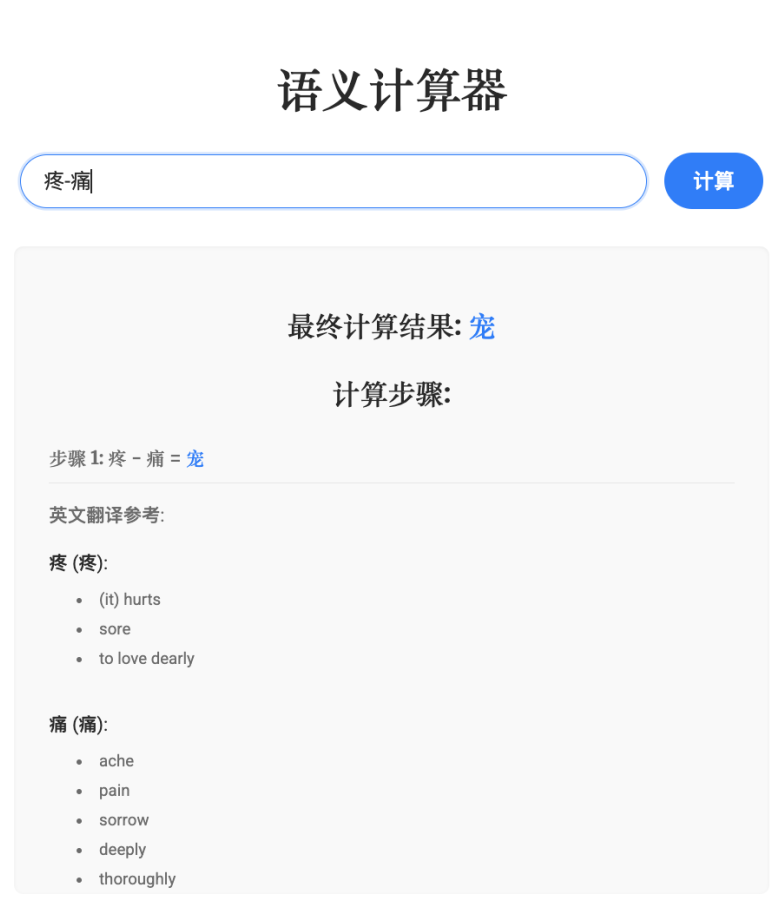
疼 - 痛 = 宠(和“痛”比起来,“疼”额外有怜惜,宠爱的意思)
闪 - 躲 = 荧(“闪”既有躲闪的意思,也有闪光的意思)
当然,并非所有衡量相似性的数值都合理,导致一些字对运算结果不尽理想。目前我只使用了3500个字,很多常用字并未包含在内。未来我可能会尝试使用闭源的 embedding,甚至直接通过 API 调用 LLM 来黑箱定义汉字加减。然而,黑箱方法的缺点在于缺乏可解释性且不够稳定,但是如果黑箱的结果更合理也可以用来微调。

基于汉字运算的衍生设计
合字成新:给定4个汉字和1个目标字,玩家需通过加减组合得到目标。例如:珠、光、宝、气 → 目标:晶
文字计算器:用户输入汉字运算表达式,如 算 - (语 + 义),返回最匹配的字。
合成叙事:玩家通过组合汉字解锁剧情。
大家有兴趣的话可以试试看❤️“合字成新”的每一道题,使用的四个字其实都是同一个成语。至于“合成叙事”里的两个故事脚本,是我先设计了情节框架,再交给 LLM 来写的——但我必须承认,它的文笔确实比我好太多了😓。“文字计算器”大家也可以玩一玩,比如输入自己的名字,或者随便加减一些字试试:例如“关+羽”、“王+者+荣+耀”、“英+雄+联+盟”、“力+宏”、“徐+坤”等等。不过说实话,对我个人而言,最有意思的还是“文字计算器”,其他部分……可能更多是我在制作中找到乐趣😓。
最后我要感谢各种 LLM 工具,开源的 embedding 模型和汉字翻译数据。不管怎么样,我在做这些东西的时候虽然因为效果问题,无数次都在放弃边缘,但是总得来说还有颇有乐趣的。在 LLM 老师的帮助下,我也“学会了”写网站————这是我最大的收获!
合字成新
尝试组合得到目标汉字
http://1844mcintyre.com/index.html
文字计算器
加一加你的名字
http://1844mcintyre.com/calculator/calculator.html
合成叙事
组合汉字解锁剧情
http://1844mcintyre.com/story/story.html


来源 | 孔雨晴,LLM 工具

— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

内容中包含的图片若涉及版权问题,请及时与我们联系删除
