阿里通义千问近日发布了两款更小尺寸的新模型:Qwen3-4B-Instruct-2507和Qwen3-4B-Thinking-2507,并已在魔搭社区和HuggingFace开源。其中,Qwen3-4B-Instruct-2507在非推理领域表现优异,全面超越了闭源的GPT-4.1-Nano。而Qwen3-4B-Thinking-2507在推理能力上更是可以媲美中等规模的Qwen3-30B-A3B(thinking),尤其在AIME25测评中,以4B参数量取得了81.3分的高分,Agent分数也表现突出。新模型对手机等端侧硬件部署友好,并支持256K的上下文理解能力,能够处理长文本和复杂的推理任务,为用户提供更符合需求的答复。
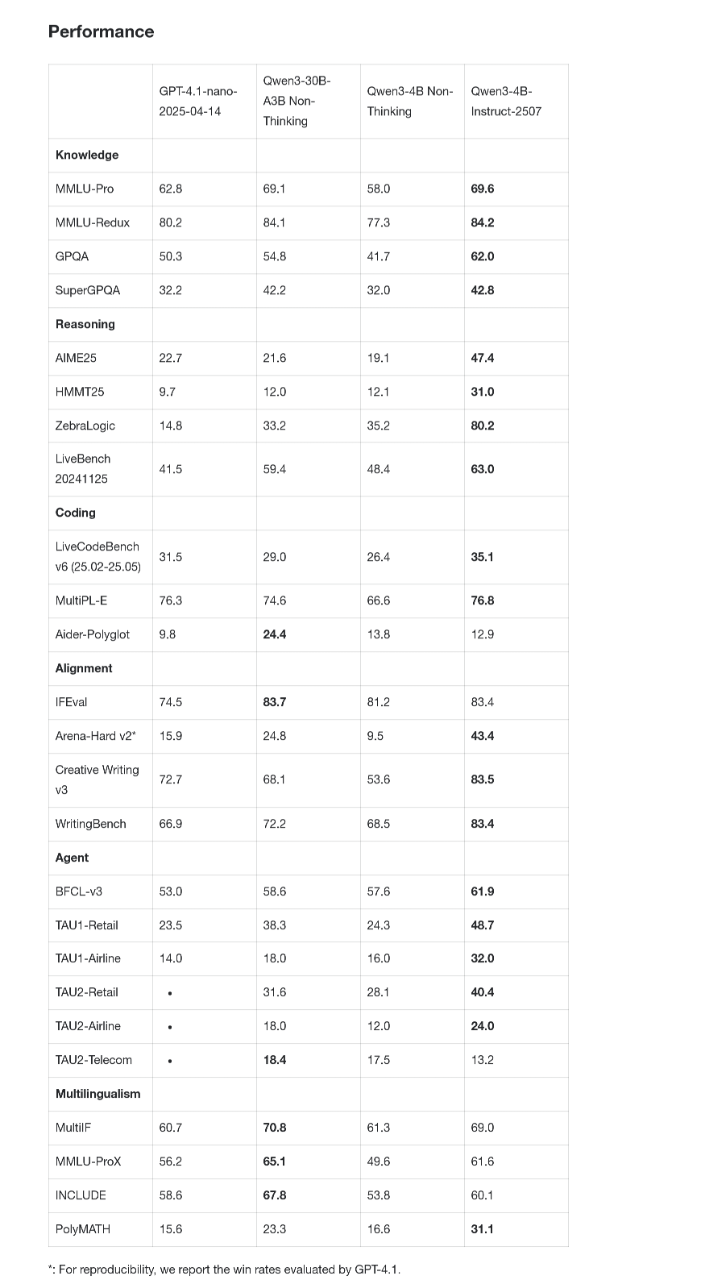
🌟 **性能超越闭源小模型:** Qwen3-4B-Instruct-2507在通用能力上实现了大幅提升,在非推理领域全面超越了商业闭源的小尺寸模型GPT-4.1-nano,并且与中等规模的Qwen3-30B-A3B(non-thinking)性能接近,展现了在同等参数量下更强的竞争力。
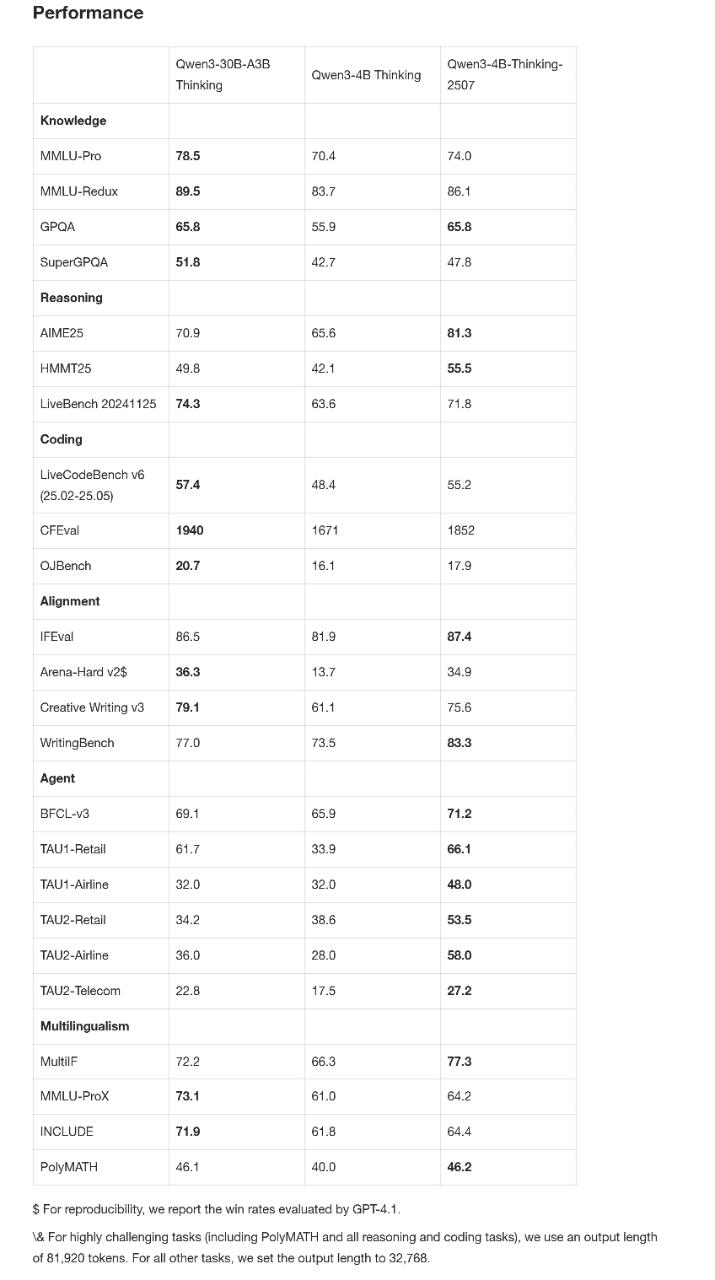
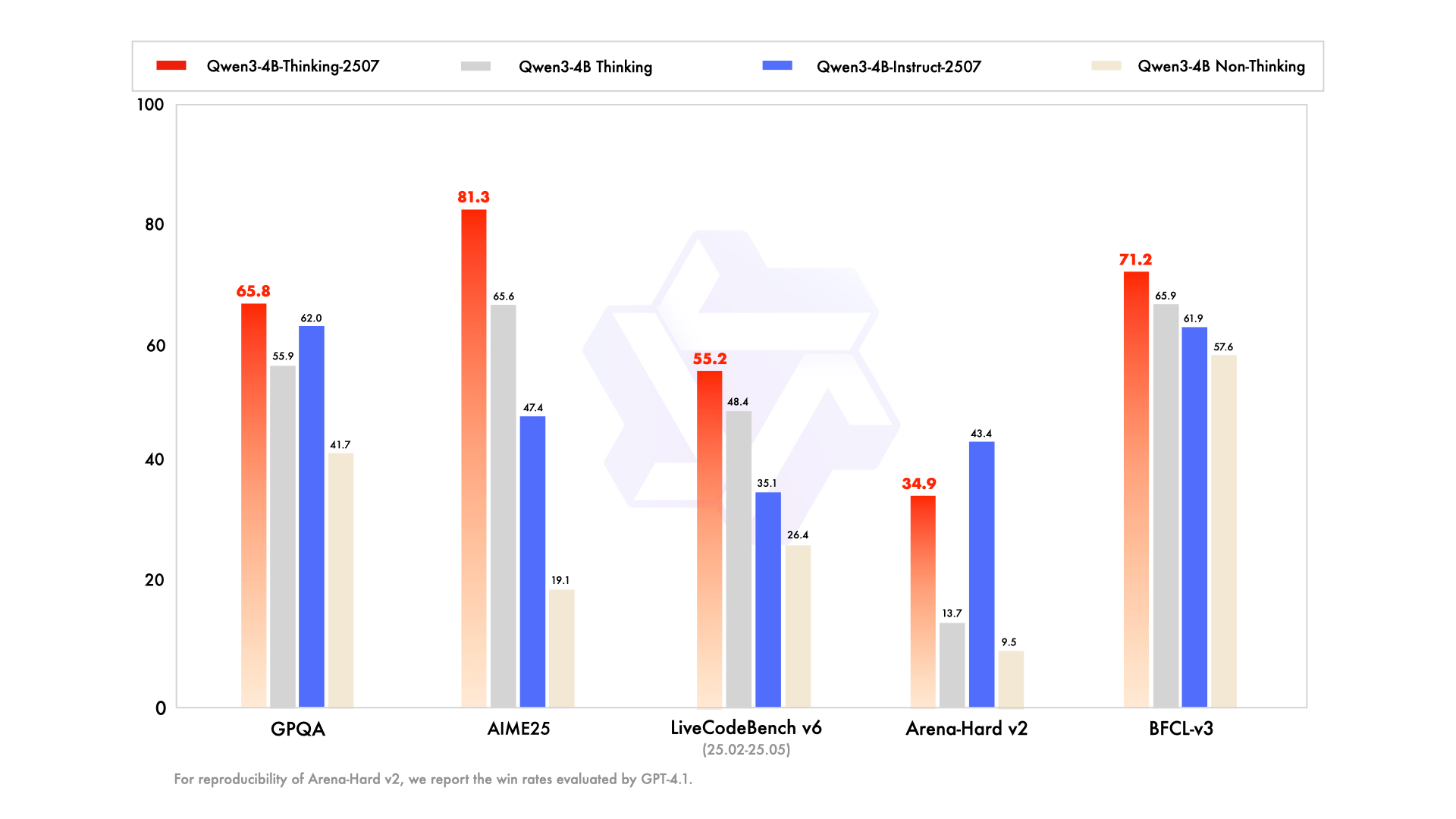
🧠 **推理能力媲美中等模型:** Qwen3-4B-Thinking-2507在推理能力上表现出色,可以媲美中等规模的Qwen3-30B-Thinking模型。特别是在数学能力评估AIME25中,以4B的参数量获得了81.3分的高分,Agent分数也表现抢眼,显示了其强大的逻辑推理和解决问题的能力。
📚 **长上下文处理能力:** 新发布的Qwen3-4B模型支持高达256K tokens的上下文理解能力,这意味着模型可以处理更长、更复杂的文本信息,例如进行深入的文档分析、生成长篇内容,以及实现跨段落的推理,极大地扩展了模型的应用场景。
📱 **端侧部署友好:** 官方特别指出,2507版本的Qwen3-4B模型对手机等端侧硬件部署尤为友好,这预示着未来在移动设备上运行更强大AI模型成为可能,降低了AI应用的门槛和成本。
🌐 **语言覆盖与偏好对齐:** 新模型覆盖了更多语言的长尾知识,并在主观和开放性任务中增强了人类偏好对齐,能够提供更贴近用户需求、更自然的交互体验,提升了模型的实用性和用户满意度。
今日,阿里通义千问宣布发布更小尺寸新模型——Qwen3-4B-Instruct-2507和Qwen3-4B-Thinking-2507。目前新模型已在魔搭社区、HuggingFace正式开源。据介绍,在非推理领域,Qwen3-4B-Instruct-2507全面超越闭源的GPT4.1-Nano。
在推理领域,Qwen3-4B-Thinking-2507甚至可以媲美中等规模的Qwen3-30B-A3B(thinking)。
官方表示,2507版本的Qwen3-4B模型对手机等端侧硬件部署尤为友好。
以下为模型核心亮点
Qwen3-4B-Instruct-2507
通用能力均大幅提升,超越商业闭源的小尺寸模型GPT-4.1-nano,与中等规模的Qwen3-30B-A3B(non-thinking)性能接近。
新模型覆盖更多语言的长尾知识,在主观和开放性任务中增强了人类偏好对齐,可提供更符合人们需求的答复。
上下文理解扩展至256K,小模型也能处理长文本。
Qwen3-4B-Thinking-2507
推理能力大幅增强,AIME25高达81.3分,Qwen3-4B-Thinking-2507的推理表现可媲美中等模型Qwen3-30B-Thinking。
特别是在聚焦数学能力的AIME25测评中,以4B参数量斩获81.3分成绩。
Agent分数爆表,相关评测均超越更大尺寸的Qwen3-30B-Thinking模型。
256K tokens上下文的理解能力,支持更复杂的文档分析、长篇内容生成、跨段落推理等场景。