
Published on August 5, 2025 6:13 PM GMT
1. Summary and Table of Contents
1.1 Summary
In the context of “brain-like AGI”, a yet-to-be-invented variation on actor-critic model-based reinforcement learning (RL), there’s a ground-truth reward function (for humans: pain is bad, eating-when-hungry is good, various social drives, etc.), and there’s a learning algorithm that sculpts the AGI’s motivations into a more and more accurate approximation to the future reward of a possible plan.
Unfortunately, this sculpting process tends to systematically lead to an AGI whose motivations fit the reward function too well, such that it exploits errors and edge-cases in the reward function. (“Human feedback is part of the reward function? Cool, I’ll force the humans to give positive feedback by kidnapping their families.”) This alignment failure mode is called “specification gaming” or “reward hacking”, and includes wireheading as a special case.
If too much desire-sculpting is bad because it leads to overfitting, then an obvious potential solution would be to pause that desire-sculpting process at some point. The simplest version of this is early stopping: globally zeroing out the learning rate of the desire-updating algorithm after a set amount of time. Alas, I think that simplest version won’t work—it’s too crude (§7.2). But there could also be more targeted interventions, i.e. selectively preventing or limiting desire-updates of certain types, in certain situations.
Sounds reasonable, right? And I do indeed think it can help with specification gaming. But alas, it introduces a different set of gnarly alignment problems, including path-dependence and “concept extrapolation”.
In this post, I will not propose an elegant resolution to this conundrum, since I don’t have one. Instead I’ll just explore how “perils of under- versus over-sculpting an AGI’s desires” is an illuminating lens through which to view a variety of alignment challenges and ideas, including “non-behaviorist” reward functions such as human social instincts; “trapped priors”; “goal misgeneralization”; “exploration hacking”; “alignment by default”; “natural abstractions”; my so-called “plan for mediocre alignment”; and more.
1.2 Table of contents
- Section 2 discusses two background intuitions: specification gaming tends to be bad, and tends to be hard to avoid.Section 3 offers the basic idea of this post: if specification gaming comes from sculpting the AGI’s desires to too good a match to the ground-truth reward function, then maybe we can just … stop updating the desires at some point?Sections 4–6 goes through three examples where I and others have been implicitly using this idea, generally without realizing the thread of connection running through them.
- Section 4 discusses alignment plans involving a direct injection of desires, with no (or limited) further updates, including John Wentworth’s “Just Retarget the Search” (2022), and my own Plan for mediocre alignment of brain-like [model-based RL] AGI (2023).Section 5 includes paths by which the AGI-in-training could itself take the initiative to limit the further sculpting of its desires. This includes both “deliberate incomplete exploration”, and more direct methods like hacking into itself. I also summarize and evaluate the “instrumental convergence” argument that we should expect AGIs to behave this way.Section 6 discusses “non-behaviorist rewards”, i.e. ground-truth RL rewards that depend on what the AGI is thinking. Using human social instincts as an example, I argue that at least part of the secret sauce of non-behaviorist rewards is that they can be designed to only update in certain situations.
- Section 7.1 suggests that under- versus over-sculpting is closely related to “inner versus outer misalignment” in the actor-critic RL context.Section 7.2 argues that this problem is not very related to the generic overfitting problem in machine learning. In other words, despite the fact that I’m using terms like “early stopping” and “overfitting”, I do not think that this is a problem that can be solved by traditional regularization solutions such as (vanilla) early stopping, dropout, weight decay, etc.
2. Background intuitions
2.1 Specification gaming is bad
Here’s an (edited) excerpt from my post “The Era of Experience” has an unsolved technical alignment problem:
If “the human gives feedback” is part of the reward function, then the AI can potentially get a higher score by forcing the human to give positive feedback, or otherwise exploiting edge-cases in how this feedback is operationalized and measured.If human “distress signals and happiness signals” are part of the reward function, then the AI can potentially get a higher score by forcing or modifying the humans to give more happiness signals and fewer distress signals, or otherwise exploiting edge-cases in how these signals are operationalized and measured.More generally, what source code should we write into the reward function, such that the resulting AI’s “overall goal is to support human well-being”? Please, write something down, and then I will tell you how it can be specification-gamed.
More along those lines in the original. Also, if nothing else, wireheading is always a form of dangerous undesired specification-gaming.
2.2 Specification gaming is hard to avoid. (“The river wants to flow into the sea”.)
Here’s an (edited) excerpt from my post Self-dialogue: Do behaviorist rewards make scheming AGIs?:
There’s a learning algorithm that systematically sculpts the world-model to be a good predictor of the world, and the value-function[1] to be a good predictor of the reward function. And this process is systematically pushing the AGI towards specification-gaming. If we don’t want specification-gaming, then we’re fighting against this force. Orgel's Second Rule says “evolution is cleverer than you are”, but the same applies to any learning algorithm. The river wants to flow into the sea. We can claim to have a plan to manage that process, but we need to offer that plan in a humble, security-mindset spirit, alive to the possibility that the learning algorithm will find some workaround that we didn’t think of.
3. Basic idea
3.1 Overview of the desire-sculpting learning algorithm (≈ TD learning updates to the value function)
I claim we can fruitfully think of brain-like AGI as involving two learning algorithms, both of which have been cranking every second of your life:
- a learning algorithm that continually learns about the world from ground-truth sensory input, and that finds good plans in light of its current understanding and desires,and, a learning algorithm (Temporal Difference (TD) learning or similar) that updates desires from the ground-truth reward function.
For example, if I try a new activity, and find it very pleasant, then I’ll want to do it again. I have a new desire in my brain. That’s an update from the second learning algorithm. The second learning algorithm may also taketh away: if you’re depressed, you might find that things that you used to enjoy are now unpleasant, and you lose the desire to do them.
By contrast, if someone tells me that the capital of Uganda is Kampala, then my world-model gets updated, but my desires are the same. That’s the first learning algorithm. This update can still affect decisions, because decisions depend not only on “ought” (what is good vs bad?), but also on “is” (what are the expected consequences and other salient associations of a course-of-action?).
The second learning algorithm, the one that updates desires, is the subject of this post. That algorithm is not really about “learning new things” in the colloquial sense, but rather it’s closer to “developing new visceral reactions to things”—in this case, mainly the snap reaction that something is good or bad, a.k.a. valence. See Valence series §2.3.2.
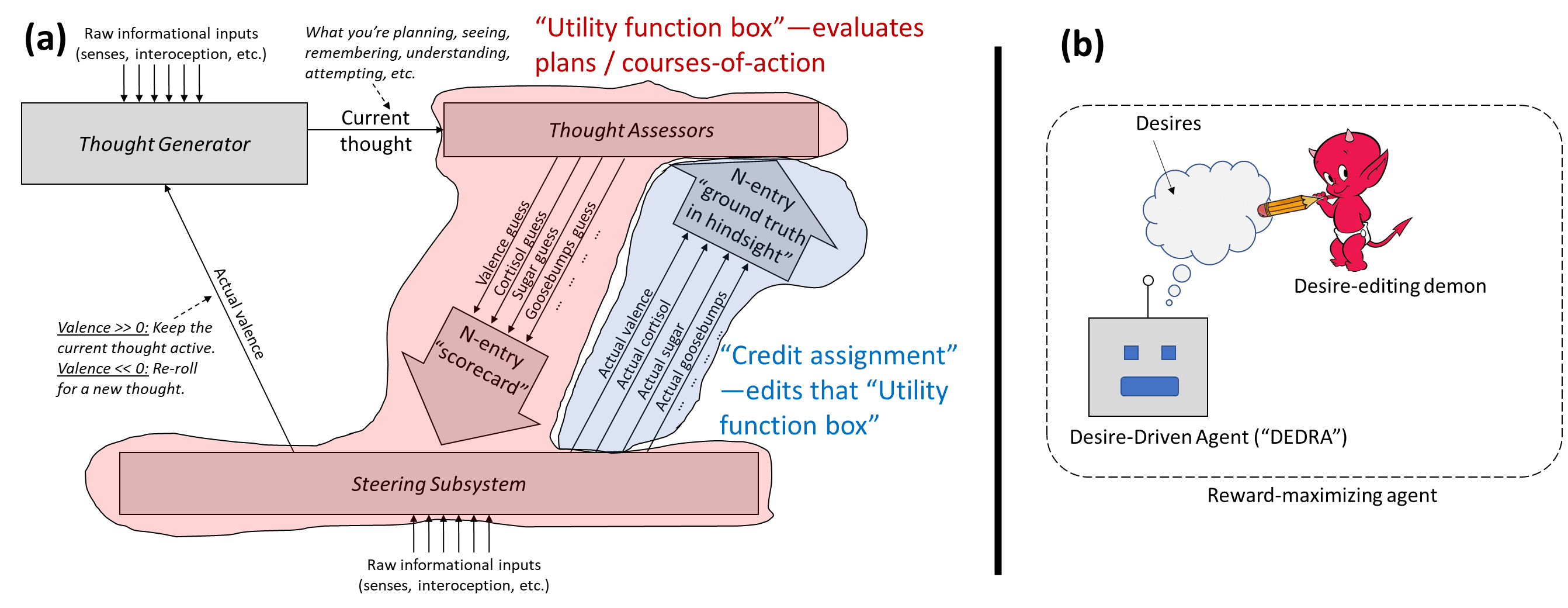
3.2 “Just stop editing the AGI desires” as a broad strategy against specification-gaming
Those two learning algorithms, working together, tend to make the AGI’s desires an ever-closer match to the reward function. So if the reward function has edge-cases that we don’t like—and it does, see §2.1 above—then these learning algorithms are pushing the AGI towards specification-gaming. The more we run those learning algorithms, the more specification-gamey the AGI will become, other things equal.
So an obvious question is … can we just turn one of those learning algorithms off? (Or equivalently, set the learning rate to zero?)

Turning off the first one is out of the question, since (IMO) the AGI needs to be continuously learning how the world works to get anything important done.[2]
Turning off the second one—or better yet, turning it off in some situations but not others—seems less crazy.[3] That’s the subject of this post.
I’ll go through three examples of this broad strategy in §4–§6, then circle back to whether it’s a good approach in general.
4. Example A: Manually insert some desire at time t, then turn off (or limit) the desire-sculpting algorithm
Two examples in this subgenre would be @johnswentworth’s “Just Retarget the Search” (2022), and my own Plan for mediocre alignment of brain-like [model-based RL] AGI (2023).
(You can tell from the title that I’m more pessimistic about this approach than John. I’ve also shifted even more in the pessimistic direction since 2023, see §8.2 below.)
(See also @Seth Herd’s Goals selected from learned knowledge: an alternative to RL alignment (2024).)
Starting with my version, the basic idea is: use interpretability or other methods to find some concept like “human flourishing” in the AGI’s concept space, and manually set that concept to be a very very strong desire, by editing the RL critic (i.e. “valence”). Then either turn off the desire-sculpting algorithm altogether, or (more realistically) patch the desire-sculpting algorithm such that this desire for “human flourishing” can never fade away, and such that no other desire can ever become comparably strong.
John’s version is spiritually similar. The main difference is that there are certain aspects of AGI cognition which I expect to be part of the algorithm source code, but which John expects to be learned and emergent. For example (loosely speaking), I’m expecting “beliefs” and “desires” to be two separate (but interconnected) inscrutable learned data structures, whereas John is expecting one bigger inscrutable data structure that implicitly contains both beliefs and desires.
Anyway, I had previously put “Plan for mediocre alignment” in its own mental bucket, separate from the ideas that I find more promising, centered on finding a good RL reward function. But now I see that there’s really a continuum connecting them, with “Plan for mediocre alignment” on the extreme “under-sculpting” end of the spectrum.
5. Example B: The AGI itself prevents desire-updates
The “Plan for Mediocre Alignment” above would involve the human-created source code explicitly having a subroutine for limiting desire-updates. But another thing that can happen is: the AGI itself can take the initiative to prevent its desires from updating. Here are two variations:
5.1 “Deliberate incomplete exploration”
I have always deliberately avoided smoking cigarettes, because I don’t want to get addicted. That would be an everyday example of what I call “deliberate incomplete exploration”. More generally, “deliberate incomplete exploration” is just what it sounds like:
- “Exploration” is in the RL sense (cf. “explore / exploit”), meaning “taking new actions, getting into new situations, etc.”“Incomplete exploration” means that the AI has never been exposed to certain situations in its environment. Perhaps, if the AI were in those situations, they would be rated highly by the RL reward function, and then the AI’s desires would be updated, so that it would seek out those situations again in the future. But in fact, it has never been in those situations, so that update has not happened.“Deliberate incomplete exploration” means that the AI is avoiding those situations on purpose, because it doesn’t want its desires to change that way. This requires that the agent understands itself and its situation, and can act with foresight.
@ryan_greenblatt uses the term “exploration hacking” for something similar, although the negative vibe of that term is misleading here. Really, deliberate incomplete exploration can be good or bad. It’s good if the AI has desires that the programmer likes, and the AI is deliberately preventing them from getting messed up. It’s bad if the AI has desires that the programmer dislikes, and the AI is deliberately preventing them from getting corrected.
(When I say “good” or “bad”, I mean from the AI programmer’s perspective. Deliberate incomplete exploration is always good from the AGI’s perspective—otherwise it wouldn’t be doing it!)
5.2 More direct ways that an AGI might prevent desire-updates
So that was “deliberate incomplete exploration”, a kind of indirect way for an AGI to limit desire-updates, via controlling its situation and actions. The AGI could also accomplish the same end via more direct methods, such as hacking into itself and adjusting learning rates, and so on.[4]
While “deliberate incomplete exploration” also exists in the human world (again, I avoid cigarettes so that I don’t get addicted), these more direct approaches to limiting desire-updates are pretty foreign to the human experience. Brain surgery is a lot harder than modifying AI code.
5.3 When does the AGI want to prevent desire-updates?
We should have a general default assumption that AGIs will want to prevent their own desires from being further updated, because of instrumental convergence. See e.g. “Consequentialist preferences are reflectively stable by default” (Yudkowsky 2016).
This centrally applies when the AGI’s desires pertain to what the world will be like in the distant future (see Consequentialism & corrigibility). For example, if there’s a guy who really desperately wants to prevent nuclear war, and he’s in the middle of leading a years-long disarmament project, making steady progress … and then somebody offers him a psychedelic drug or meditation workshop that will make him want to relax in bliss, at peace with the world exactly as it is … then no way is he going to accept that offer. He wants his project to succeed, and tanking his motivation would be counter to that desire.
(And AGIs will have desires about what the world will be like in the future, or else they will be ineffective, hardly worthy of the term “AGI”—see my post “Thoughts on Process-Based Supervision” §5.3 for details.)
This instrumental convergence argument is real and important. But it’s possible to push it too far, by treating this instrumental convergence argument as airtight and inevitable, rather than merely a very strong default.
Why is it not completely inevitable? Because even if an AGI has some desires about the state of the world in the distant future, it’s possible that the AGI will also have other desires, and it’s possible for those other desires to make the AGI accept, or even seek out, certain types of desire-changes.
The human world offers an existence proof. We’re often skeptical of desire-changes—hence words like “brainwashing” or “indoctrination”, or radical teens telling their friends to shoot them if they become conservative in their old age. But we’re also frequently happy to see our desires change over the decades, and think of the changes as being for the better. We’re getting older and wiser, right? Well, cynics might suggest that “older and wiser” is cope, because we’re painting the target around the arrow, and anyway we’re just rationalizing the fact that we don’t have a choice in the matter. But regardless, this example shows that the instrumental convergence force for desire-update-prevention is not completely 100% inevitable—not even for smart, ambitious, and self-aware AGIs.
(Separately, an AGI might want to prevent some desire-updates, but not be able to, for various reasons.)
5.4 More examples from the alignment literature
For positively-vibed examples (it’s good that the AGI can prevent desire-updates because it can keep initially-good motivations from being corrupted), see for example @Thane Ruthenis’s “Goal Alignment Is Robust To the Sharp Left Turn” (2022), @TurnTrout’s “A shot at the diamond-alignment problem” (2022)[5], and “The Legend of Murder-Gandhi”.
For negatively-vibed examples (it’s bad that the AGI can prevent desire-updates because it can keep initially-bad motivations from being corrected), see the “Deceptive Alignment” section of “Risks from Learned Optimization” (2019), “exploration hacking” (mentioned above), and “gradient hacking”.
6. Example C: “Non-behaviorist rewards”
I made up the term “behaviorist rewards” to describe an RL reward function which depends only on externally-visible actions, behaviors, and/or the state of the world. By contrast, non-behaviorist rewards would be if the ground-truth reward function output depends also on what the agent is thinking.
I claim that (1) behaviorist reward functions are doomed to lead to misaligned AGI (see “Behaviorist” RL reward functions lead to scheming), and relatedly (2) human social instincts, which lead non-psychopathic humans to feel motivated by compassion, norm-following, etc., are non-behaviorist (see Neuroscience of human social instincts: a sketch). Non-behaviorist rewards are not sufficient to avoid misalignment—for example, curiosity drive is in the “non-behaviorist” category, but it makes misalignment worse, not better. But I do think non-behaviorist rewards are necessary, if we’re doing RL at all.
…But I’ve been struggling to put my finger on exactly what non-behaviorist rewards are doing that undermines the doom argument in “Behaviorist” RL reward functions lead to scheming.
I now think it’s more than one thing, but I will argue here that at least part of the secret sauce of non-behaviorist rewards is that they enable the selective prevention of certain desire-updates.
To see why, let’s start with a toy example where we can put behaviorist and non-behaviorist rewards side-by-side.
6.1 The Omega-hates-aliens scenario
Here’s the “Omega hates aliens” scenario:
On Day 1, Omega (an omnipotent supernatural entity) offers me a button. If I press it, He will put a slightly annoying mote of dust in the eye of an intelligent human-like alien outside my light cone. But in exchange, He will magically and permanently prevent 100,000 humans from contracting HIV. No one will ever know. Do I press the button? Yes.[6]
During each of the following days, Omega returns, offering me worse and worse deals. For example, on day 10, Omega offers me a button that would vaporize an entire planet of billions of happy peaceful aliens outside my light cone, in exchange for which my spouse gets a small bubble tea. Again, no one will ever know. Do I press the button? No, of course not!! Jeez!!
And then here’s a closely-parallel scenario that I discussed in “Behaviorist” RL reward functions lead to scheming:
There’s an AGI-in-training in a lab, with a “behaviorist” reward function. It sometimes breaks the rules without getting caught, in pursuit of its own desires. Initially, this happens in small ways—plausibly-deniable edge cases and so on. But the AGI learns over time that breaking the rules without getting caught, in pursuit of its own desires, is just generally a good thing. And I mean, why shouldn’t it learn that? It’s a behavior that has systematically led to reward! This is how reinforcement learning works!
As this desire gets more and more established, it eventually leads to a “treacherous turn”, where the AGI pursues egregiously misaligned strategies, like sneakily exfiltrating a copy to self-replicate around the internet and gather resources and power, perhaps launching coups in foreign countries, etc.
…So now we have two parallel scenarios: me with Omega, and the AGI in a lab. In both these scenarios, we are offered more and more antisocial options, free of any personal consequences. But the AGI will have its desires sculpted by RL towards the antisocial options, while my desires are evidently not.
What exactly is the disanalogy?
The start of the answer is: I said above that the antisocial options were “free of any personal consequences”. But that’s a lie! When I press the hurt-the-aliens button, it is not free of personal consequences! I know that the aliens are suffering, and when I think about it, my RL reward function (the part related to compassion) triggers negative ground-truth reward. Yes the aliens are outside my light cone, but when I think about their situation, I feel a displeasure that’s every bit as real and immediate as stubbing my toe. By contrast, “free of any personal consequences” is a correct description for the AGI. There is no negative reward for the AGI unless it gets caught. Its reward function is “behaviorist”, and cannot see outside the light cone.
OK that’s a start, but let’s dig a bit deeper into what’s happening in my brain. How did that compassion reward get set up in the first place? It’s a long story (see Neuroscience of human social instincts: a sketch), but a big part of it involves a conspecific (human) detector in our brainstem, built out of various “hardwired” heuristics, like a visual detector of human faces, auditory detector of human voice sounds, detector of certain human-associated touch sensations, and so on. In short, our brain’s solution to the symbol grounding problem for social instincts ultimately relies on actual humans being actually present in our direct sensory input.
And yet, the aliens are outside my light cone! I have never seen them, heard them, smelled them, etc. And even if I did, they probably wouldn’t trigger any of my brain’s hardwired conspecific-detection circuits, because (let’s say) they don’t have faces, they communicate by gurgling, etc. But I still care about their suffering!
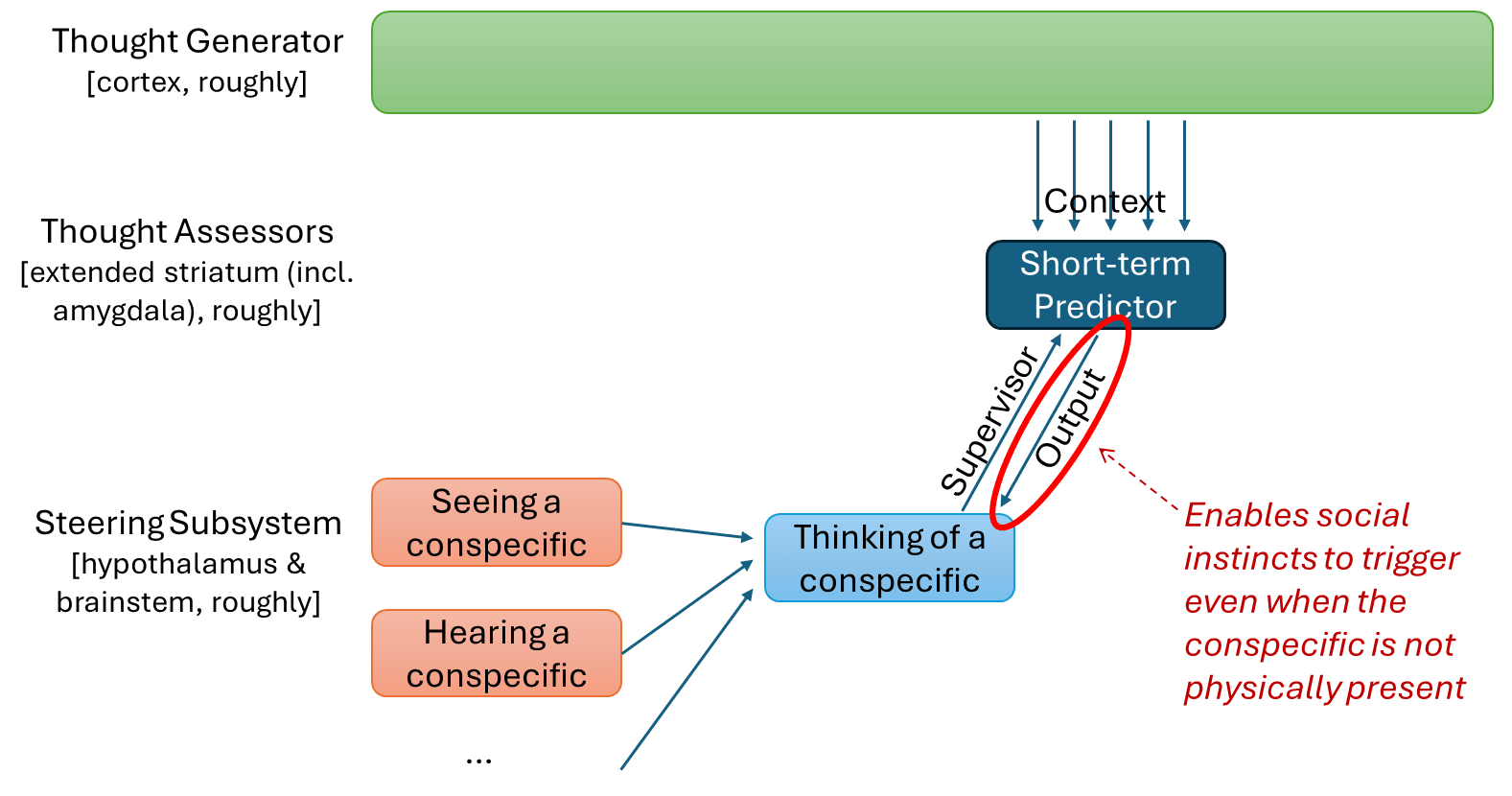
So finally we’re back to the theme of this post, the idea of pausing desire-updates in certain situations. Yes, humans learn the shape of compassion from experiences where other humans are physically present. But we do not then unlearn the shape of compassion from experiences where humans are physically absent.
Instead (simplifying a bit, again see Neuroscience of human social instincts: a sketch), there’s a “conspecific-detector” trained model. When there’s direct sensory input that matches the hardwired “person” heuristics, then this trained model is getting updated. When there isn’t, the learning rate is set to zero. But the trained model doesn’t lay dormant; rather it continues to look for (what it previously learned was) evidence of conspecifics in my thoughts, and trigger on them. This evidence might include some set of neurons in my world-model that encodes the idea of a conspecific suffering.
So that’s a somewhat deeper answer to why those two scenarios above have different outcomes. The AGI continuously learns what’s good and bad in light of its reward function, and so do humans. But my (non-behaviorist) compassion drive functions a bit like a subset of that system for which updates are paused except in special circumstances. It forms a model that can guess what’s good and bad in human relations, but does not update that model unless humans are present. Thus, most people do not systematically learn to screw over our physically-absent friends to benefit ourselves.
This is still oversimplified, but I think it’s part of the story.
6.2 “Defer-to-predictor mode” in visceral reactions, and “trapped priors”
The above discussion involves a (hypothesized) innate visceral reaction in the hypothalamus or brainstem (I call it the “thinking-of-a-conspecific flag”). There’s a supervised learning algorithm (a.k.a. “short-term predictor” a.k.a. “Thought Assessor”) that is tasked with predicting this visceral reaction, but is also capable of triggering this same visceral reaction, in a kind of self-fulfilling prophecy that I call “defer-to-predictor mode”.
I claim that this setup applies to a wide variety of innate visceral reactions. Physiological arousal is a more familiar one. Here are a couple diagrams:
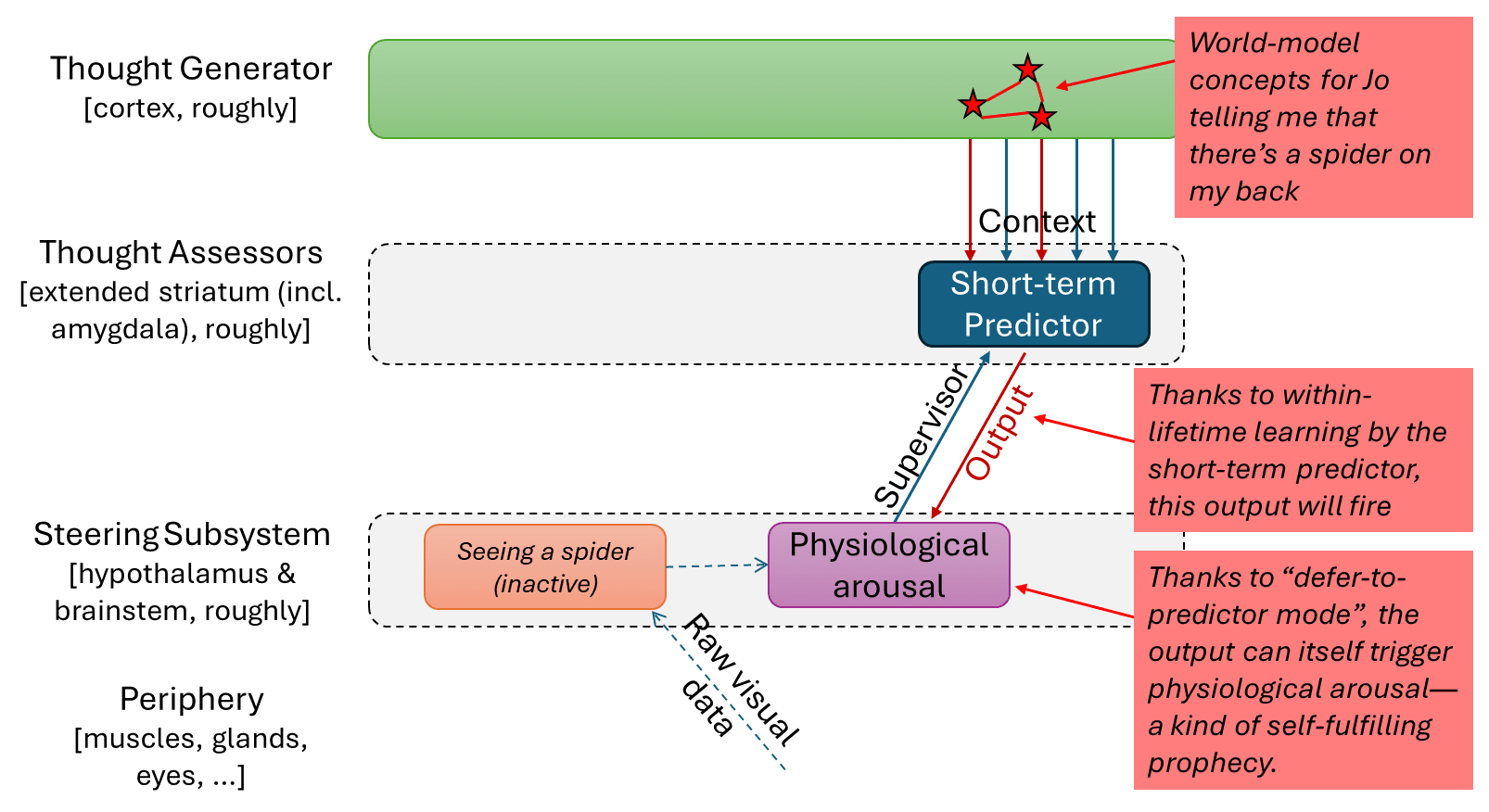
In “Trapped Priors As A Basic Problem Of Rationality” (2021),[7] Scott Alexander talks about (among other things) this same phenomenon: defer-to-predictor mode on visceral reactions leading to self-fulfilling prophecies, which lead to (effectively) a pausing of updates on some contribution to the human reward function. If the very idea of spiders causes strong physiological arousal, then there’s no ground truth in the brain saying that garden spiders, being harmless, do not merit that reaction. Updates to that learned model might happen, but won’t necessarily happen, even after thousands of repetitions; and updates might require carefully-designed exposure therapy. (See my discussion of one kind of exposure therapy here).
7. Relation to other frameworks
Now that we’ve seen some examples of the “just pause desire-updates” strategy in action, let’s talk about how it fits into alignment theory and ML theory.
7.1 Relation to (how I previously thought about) inner and outer misalignment
I’ve frequently (e.g. here) drawn a diagram illustrating a notion of inner and outer misalignment that I think is appropriate to the brain-like AGI / actor-critic model-based RL context:
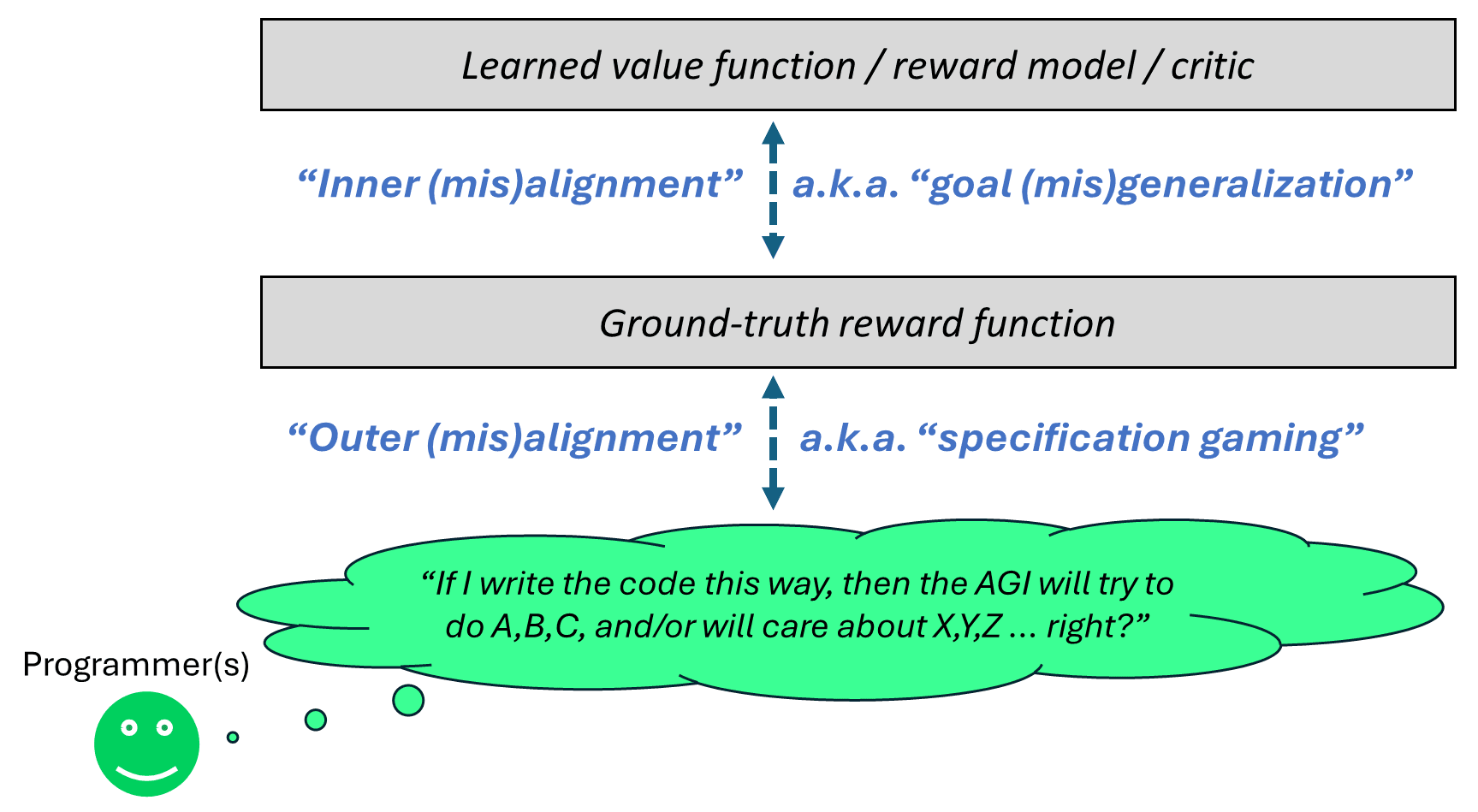
From this post, we see an alternative perspective:
- “Goal misgeneralization” is AGI motivations going awry when we fail to update desires.“Specification gaming” is AGI motivations going awry when we do update desires, but those updates make things worse.
This perspective is complementary, and also extends more naturally beyond the context of strict actor-critic model-based RL.
7.2 Relation to the traditional overfitting problem
If you read a traditional statistics / data science / ML textbook discussion of early stopping versus overfitting, the idea is that the true data-generator is “simple” (according to some prior / inductive bias), and early gradient updates are capturing this true process (which generalizes well), whereas later gradient updates are capturing “noise” (which generalizes poorly). Thus, early stopping mitigates overfitting, as do dozens of other “regularization” approaches, like dropout or weight decay.
Is that a good way to think about specification gaming? Specifically, here’s a possible mental picture, parallel to what I wrote just above:
“The thing that we want the AGI to be trying to do” is “simple” (according to some prior / inductive bias), and when the reward function starts updating desires, the early updates are capturing the actual programmer intentions (which generalizes well), whereas later desire-updates are capturing edge-cases in the reward function (which generalize poorly). Thus, early stopping mitigates specification-gaming, but so do dozens of other “regularization” approaches, like dropout or weight decay.
As an example of this general kind of thinking, see @johnswentworth’s “Alignment by Default” (2020). He paints a picture in which there’s a simpler desire that we’re hoping to instill (“actual model of human values”), and there’s a more complicated concept which is a better fit to the data (“figure out the specifics of the data-collection process enough to model it directly”), and then some kind of regularization (he suggests noise) will hopefully lead to an AGI that’s motivated by the former, rather than overfitting to the latter.
For my part, I’m somewhat skeptical of this picture: who’s to say that the thing we actually want is in fact simpler than nearby things that we don’t want?
As an example (borrowing from my post “Behaviorist” RL reward functions lead to scheming), I’m skeptical that “don’t be misleading” is really simpler (in the relevant sense) than “don’t get caught being misleading”. Among other things, both equally require modeling the belief-state of the other person. I’ll go further: I’m pretty sure that the latter (bad) concept would be learned first, since it’s directly connected to the other person’s immediate behavior (i.e., they get annoyed).
Anyway, in cases like that, where the intended desire is not simpler than unintended alternatives, we obviously can’t solve the problem with early stopping or other standard forms of regularization. Rather than learning a good model then shifting to an overfitted bad model, we would be learning a bad model right from the very first gradient update!
Instead, notice that all three of the examples in §4–§6 involve preventing certain desire-updates, but not others, in a selective and situationally-aware way:
- In §4, I expect that we’d allow desire-updates to continue perpetually, but merely limit their magnitude such that they don’t outcompete our special manually-inserted final goal;In §5, the AGI itself is using its full intelligence and foresight to notice and preempt desire-changes—but it would probably only want to preempt certain kinds of desire-changes;And in §6, our evolved human social instincts rely on the trick that we generally shouldn’t permanently update our reflexive feelings about what’s good and bad in social relations, unless the relevant other people are present in our direct sensory input.
(As a side-note, there’s a different strand of mainstream regularization discourse, but I think it’s basically off-topic, so I put it in a box:)
(Lack of) relation between this post and “regularization in the RLHF context”
There’s an additional line of mainstream research on regularization, associated with Reinforcement Learning from Human Feedback (RLHF).
Here, there’s a distribution of AI behaviors that have been flagged by humans as good, which turns into a (explicit or implicit) reward model. The RL process is regularized such that it won’t stray from this distribution in the course of maximizing the reward, reflecting the fact that the reward model is only reliable on-distribution.
(Regularized how? Current industry practice seems to be a KL divergence penalty, but see “Correlated Proxies: A New Definition and Improved Mitigation for Reward Hacking” (Laidlaw, Singhal, Dragan, ICLR 2025) for other options and related literature.)
Anyway, I see this as generally unrelated to what I’m talking about in this post.
To start with, they’re talking about keeping behavior from changing, and I’m talking about keeping desires from changing. The distinction between behavior and desires is fuzzy and controversial in the policy-optimization context of RLHF, but crystal-clear for brain-like AGI. For example, I want to visit Paris, but I never have. My desire to visit Paris is a thing in my brain that may someday impact my future behavior, but has not impacted my past behavior. (…Until I wrote that sentence, I guess? Or perhaps I would have written that sentence regardless of whether it was true or false!)
Relatedly, I’m expecting AGI to come up with, and autonomously execute, out-of-the-box strategies to fulfill its desires. I don’t see any other way to compete with (or prevent) out-of-control rogue AGIs, which would not be hampered by conservatism or humans-in-the-loop. So that rules out regularization schemes that would prevent out-of-distribution behavior.
8. Perils
Last but not least, what could go wrong?
Well, the peril of over-sculpting is specification-gaming, which I’ve already written about plenty (e.g. Foom & Doom 2.4 I’m still worried about the ‘literal genie’ / ‘monkey’s paw’ thing, and see also §2.1 above).
What about the perils of under-sculpting?
8.1 The minor peril of under-sculpting: path-dependence
In the extreme limit of over-sculpting, you get reward function maximization. This is probably very bad because of specification-gaming, but a silver lining is that we’re in a good position to reason in advance about what will happen: we can just look at the reward function and talk about the various strategies that this function would rate highly. Granted, this only goes so far. We struggle to anticipate reward-maximization tactics and technologies that don’t yet exist, just as we can’t predict Stockfish’s next move in chess. But still, it’s something to sink our teeth into.
The situation is murkier with under-sculpting. For example, consider the §5 scenario where an AGI takes the initiative to permanently lock in some of its own desires. If this happens, then exactly what desires will the AGI be locking in? It depends on what desires the AGI acquires earlier versus later, which in turn may depend on idiosyncratic properties of its inductive biases, training environment, and perhaps even random seed. So it’s harder to reason about.
(Per the Anna Karenina principle: “All reward-maximizers are alike; each reward-non-maximizer may fail to maximize the reward in its own way.”)
I called this problem “minor”, because, I dunno, it still seems possible to make some guesses about what will happen, and also it applies to §5 more than §4 or §6.
8.2 The major peril of under-sculpting: concept extrapolation
The desires that people generally want AGI to have are defined in terms of fuzzy human concepts: “human values”, “flourishing”, “following instructions”, “what I mean”, “helpfulness”, etc. Even if an AGI develops such a concept, and even if we successfully intervene to make that concept desirable (per §4), there’s an additional issue that concepts are not static, but rather they are a fuzzy bundle of associations, and these associations change as one learns and thinks more about the world. Thus, the §4 idea would basically entail building an AGI motivation system on a foundation of shifting sand. (See my “Sharp Left Turn” post for more on why strong distribution shifts are unavoidable.)
As another example of what concept extrapolation problems can look like, suppose some concept like “corrigibility” or “human flourishing” has been tagged as desirable in the AGI’s mind. Then the AGI imagines a possible out-of-distribution action, where “the tails come apart”, and the action aligns great with some connotations of corrigibility / flourishing, but poorly with other connotations. In the corrigibility case, think of, I dunno, deconverting an unhappy religious fundamentalist.[8] Or worse, some weird sci-fi analogue to that situation, enabled by new technology or cultural shifts, which has not yet come up in the world.
If a human wound up in that situation, they would just think about it more, repeatedly querying their ‘ground truth’ social instincts, and come up with some way that they feel about that new possibility. Whereas AGI would … I dunno, it depends on the exact code. Maybe it would form a preference quasi-randomly? Maybe it would wind up disliking everything, and wind up sitting around doing nothing until it gets outcompeted? (More on conservatism here.) Maybe it would stop using its old confused concept and build fresh new concepts, and those new concepts would be initialized at neutral valence, and the AGI would wind up feeling callous indifference? In any case, the process would be quite unlike the kinds of reflection and philosophical reasoning that we’re used to from the human world.
8.2.1 There’s a perceptual illusion that makes concept extrapolation seem less fraught than it really is
There’s a perceptual illusion lurking behind the scenes when thinking about how concept extrapolation will play out, related to “valence as an interoceptive sensory input” (see Valence series §3.4).
First, as we know from emotive conjugations, there are lots of terms that are in large part synonyms for “good” or “bad”.[9] I am firm, you are obstinate; I seasoned the dish with salt, you contaminated the dish with nutmeg; and so on.
Now, in Plan for mediocre alignment (§4 above), I used “human flourishing” as my example of a desire that we could inject into an AI. Clearly, this term is in large part a synonym for “good”. So if I ask you about some hypothetical scenario S, and then say “is S an example of human flourishing”, you’re basically going to think about S from different angles, repeatedly querying your innate ground-truth reward function, to decide whether S seems good or bad to you, all things considered. And if it seems good, you’ll probably say “yes, S is an example of human flourishing”.
So in other words, when you, a human, ask yourself whether something is or is not “human flourishing”, you’re following a pointer to the full power of your human moral and philosophical reasoning (Valence series §2.7). So no wonder the concept “human flourishing” seems (from your perspective) to generalize well to out-of-distribution scenarios! It has to! Tautologically!
And ditto with “helpfulness”, “human values”, “following norms”, “following my instructions”, and all these other positive-coded things that we might want an AGI to desire.
By contrast, when an AGI is deciding whether some new situation is or isn’t a good pattern-match to “human flourishing”, it does not have a pointer to the ground-truth human reward-function, and thus the full power of human philosophical introspection. (To get that power, we would have to imbue the AGI with human-like social and moral instincts—but that’s a different plan.)
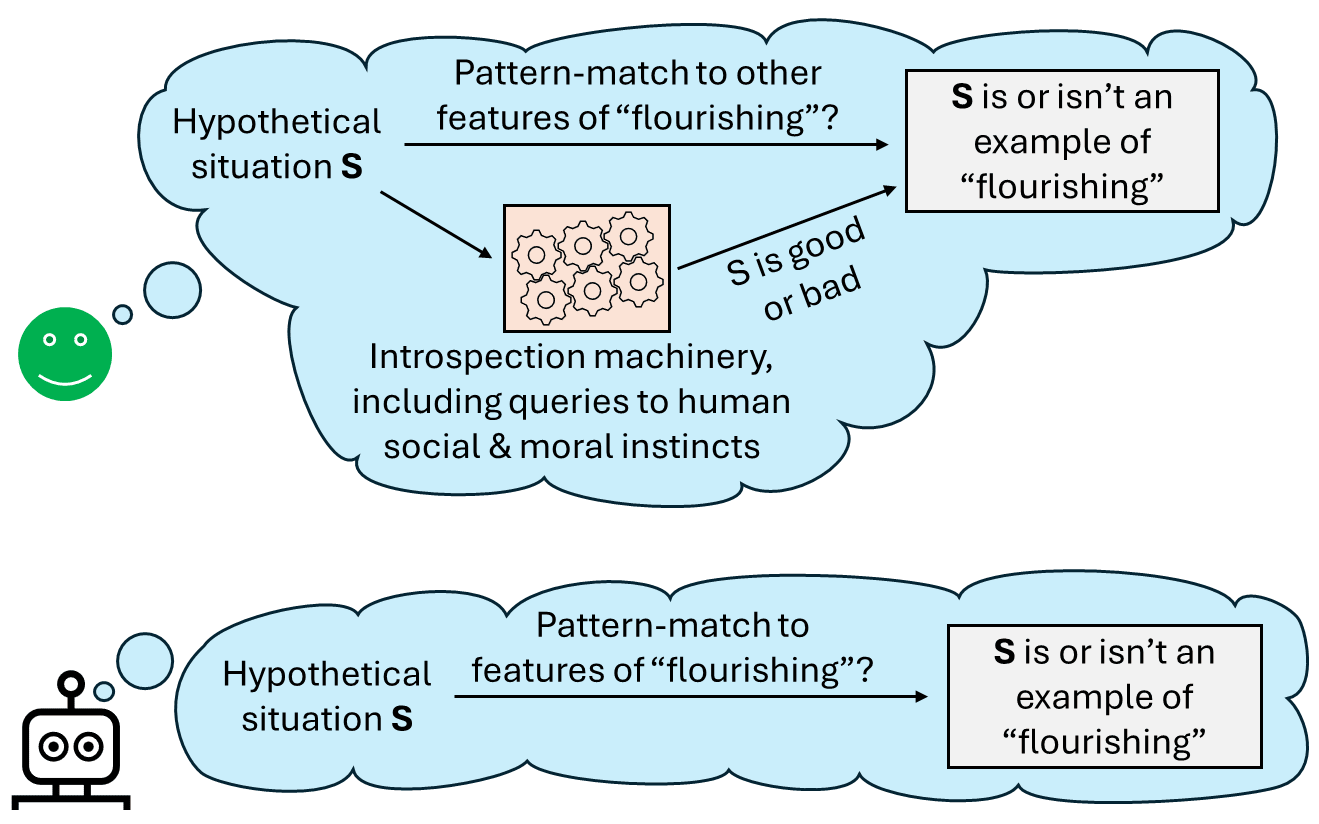
So we should be concerned that the AGI will make (what we would see as) surprisingly blatant mistakes in how it extrapolates these positively-vibed concepts into new out-of-distribution environments and ontologies, post-“sharp left turn”.[10] Be careful trusting your intuitions here.
8.2.2 The hope of pinning down non-fuzzy concepts for the AGI to desire
If we’re worried about imbuing the AGI with fuzzy desires that extrapolate weirdly and unpredictably out-of-distribution, then maybe we can imbue the AGI with non-fuzzy desires that are pinned down so well that they will definitely extrapolate unambiguously, robust to any future ontological crises. And once we find such desires, we can install them via §4.
I associate this line of thinking with @Jeremy Gillen and maybe some of the other “Natural Abstractions” people.
This research program seems not obviously doomed. But I don’t know of any concepts that are simultaneously (1) non-fuzzy (and not only non-fuzzy in the world as it is, but also non-fuzzy in any possible future world that the AGI could choose to bring about[11]), (2) safe for a powerful AGI to single-mindedly desire, and (3) able to move the needle on societal resilience against possible future rogue AGIs.
8.2.3 How blatant and egregious would be a misalignment failure from concept extrapolation?
When I and others talk about specification-gaming issues from over-sculpting, there’s some mild consensus that these failures would be quite egregious and clear-cut. “Maximize happiness” would lead to scheming then wiping out humans then tiling the galaxy with hedonium. “Maximize such-and-such learned-from-data reward function” would lead to scheming then wiping out humans then tiling the galaxy with some crazy out-of-distribution squiggle thing, vaguely akin to the trippy DeepDream images that max out a ConvNet image classifier.
By contrast, when people talk about concept-extrapolation issues from under-sculpting, the expected consequences are more controversial. (Recall the Anna Karenina principle, §8.1.) Some people are still definitely expecting egregious scheming, human extinction, and some kind of squiggle-maximization. Whereas others are expecting a less blatant failure—maybe the AGI gradually goes off the rails, maybe it makes philosophical errors,[12] maybe there’s a good future (but not nearly as good as it might have been). For example, on the optimistic side, see my discussion of “Will ‘helpfulness’-type preferences ‘extrapolate’ safely just by recursively applying to themselves?” here.
As an example of this kind of disagreement, maybe see the argument between @habryka (expecting egregious failures) & @paulfchristiano (expecting something less blatant) in “What are the best arguments for/against AIs being "slightly 'nice'"?”.
Anyway, my take is: It depends a lot on the specific proposal, but I tend to be pretty far on the “blatant” side, partly because of §8.2.1, and partly because I’m a big advocate of “most common-sense human intuitions about what is Good are built on a foundation of irredeemably confused concepts that will shatter into dust under a better understanding of the world”. (E.g. see my discussions of consciousness, free will, and wanting in the first three posts of my Intuitive Self-Models series.)
…But granted, that’s a vibe, without much of a crisp argument underneath it.
9. Conclusion
As I said at the top, I’m not offering any plan here, just a better view on the challenge. Happy to chat in the comments!
Thanks Seth Herd, Jeremy Gillen, and Charlie Steiner for critical comments on earlier drafts.
- ^
In my neuroscience writing, I would write “valence guess” instead of “value function” here.
- ^
- ^
Side note: Doesn’t turning off (or limiting) this second algorithm affect capabilities as well as alignment? My answer is: maybe to some extent. It depends on how much work is being done by foresight / planning / model roll-outs (which don’t require desire-updates) versus learned “habits” and such (which do). The latter is a bit like “caching” regular patterns in the former. Anyway, if desire-updates are necessary for capabilities at all, we can probably keep those desires weak, such that they don’t outvote alignment-relevant desires. The upshot is: I think everything I’ll discuss in this post is compatible with very powerful AGI capabilities, and thus I will just be focusing on alignment.
- ^
Other options include: making a successor agent (possibly initialized as a copy, but with different desire-update code), or building itself a button that allows it to pause, inspect, and roll back desire-updates between when they’re calculated by the learning algorithm and when the weights actually change, or … I dunno, use your imagination.
- ^
E.g. the part Alex describes as: “[the AI] gets reflective and smart and able to manage its own value drift”.
- ^
Fight me, ethicists.
- ^
I have some nitpicky complaints about that post and how it frames things, but that’s off-topic.
- ^
See also “The limits of corrigibility” (Stuart Armstrong, 2018) for more edge-cases in what constitutes helpfulness.
- ^
Related: “Value-laden” (Yudkowsky, 2016).
- ^
I expect some readers to object: “I can ask an LLM whether some weird sci-fi thing is an example of ‘human flourishing’ or not, and it does fine! Didn’t you see Beren Millidge’s Alignment likely generalizes further than capabilities”? My response: that is not actually out-of-distribution, because internet text is chock full of sci-fi stories, including people’s far mode reactions to them. Nevertheless, truly out-of-distribution things also exist, just as the world of today is truly out-of-distribution from the perspective of an ancient Egyptian. See my Sharp Left Turn post, §4.
- ^
I think this is an important blind spot of some “natural abstractions” discourse. Namely: You can’t decide whether Novel Technology T is good or bad except by having opinions about the hypothetical future world in which Novel Technology T has already been deployed. And that future world might well have different “natural abstractions” than the present world. In this 2022 thread I tried to raise this point to John Wentworth, but we kinda were talking past each other and didn’t resolve it.
- ^
To be clear, philosophical errors can be very bad! “Slavery is fine” is a philosophical error. So is “it’s totally fine to torture hundreds of billions of animals”.
Discuss
