
In 2004, I was looking for historical references for convergence, an idea that grew out of my research on Data Logistics. Data Logistics refers to the use of shared storage and processing infrastructure to augment the implementation of networking applications. Typical examples of Data Logistics are data caching and replication, some forms of multicast, as well as data synthesis. Convergence as a point of view holds that storage, networking, and computation are not inherently distinct technological categories, but are specializations of a common set of hardware and architectural tools (see Figure 1).
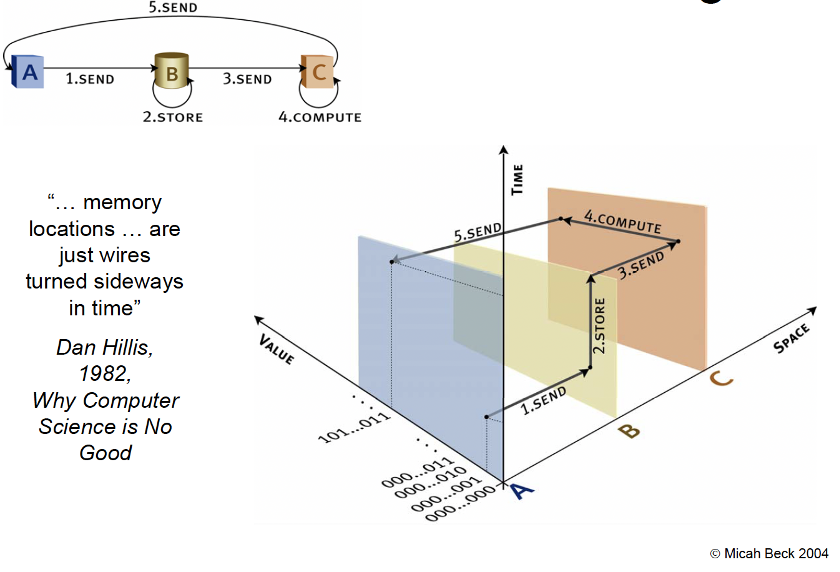
I was surprised and pleased to find a reference to convergence in a 1982 paper authored by Daniel Hllis, the architect of the Connection Machine supercomputer and founder of Thinking Machines when he was an MIT graduate student. The paper, “Why Computer Science Is No Good,” is also a chapter of his dissertation and provides an explanation of the Connection Machine SIMD (single instruction, multiple data) architecture.
Hillis’ provocative title is a reference to the way that certain simplifying assumptions that underpin the formal models on which Computer Science is based stood in the way of obtaining the greatest possible performance from available hardware resources. In particular, Hillis took issue with some aspects of the foundational work of Claude Shannon (who was on his doctoral committee) on the equivalence of digital circuits and Boolean logic (see Figure 1).
Shannon identified the value carried on a wire with a Boolean variable. In his analysis, Hillis pointed out that a Boolean variable can have an unbounded number of uses within a Boolean expression, whereas a wire has limitations due to attenuation caused by transmission over long wires and branching to drive multiple computational gates or storage cells. Ignoring these effects leads to the development of intricate control and data paths that must then be augmented with amplifiers, leading to a slower clock rate. Hillis’ original Connection Machine architecture used a two-dimensional Processor Array to optimize for the effects of distance and branching, requiring connectivity to be more local (later replaced by Fat Tree).
Hillis’ insight enabled the development of SIMD supercomputers that dominated the field of high performance computing for a decade. SIMD was ultimately limited in scale due to the difficulty of building physically large systems controlled by a single clock signal. However, it lives on the design of graphics processing units and field programmable gate arrays used as hardware accelerators to traditional bus-structured systems. Understanding the impact of this mismatch between the formal model and implementations based on it led me to seek to apply this same concept to other aspects of the field.
A formal account of a real-world system or phenomenon is usually based on some finite set of characteristics. In a formal framework such first order logic, numerical values (such as integers, reals) representing such characteristics are represented by variables, expressions are built up using operators (e.g. addition, multiplication) and relationships between them are then expressed using relational operators (e.g. equality, greater than). In first order predicate logic, qualifiers over potentially infinite domains are allowed (such as forall, exists).
Unfortunately, the real world is very complex, so there are many potentially relevant characteristics (variables) that are not mentioned in any formal model. The validity of a model is often thought of as being determined by whether the logical statements of the model can be verified in the real world. However, there is another less-obvious consideration. If the model does not mention a variable on which the validity of its statements depends, then there may be scenarios (values of the unnamed variable) which invalidate the model. Thus, in order to conclude that a model is predictive, we must not only demonstrate that its statements correspond to reality, but also that no relevant variables have been left out.
In a mature scientific field, leaving out a variable on which a modeled phenomenon depends invalidates any predictions that it might yield. However, when the fields of scientific endeavor that are now mature were young, it was common to work with “common sense” models that were not accurate enough to enable an understanding of such missing variables. Alchemy and early Western medicine also hypothesized models with a few components which operated largely by trial and error, relying on anecdotal evidence to support their justification. The outcome of such immature scientific efforts was an inability to make accurate predictions and a general lack of efficacy.
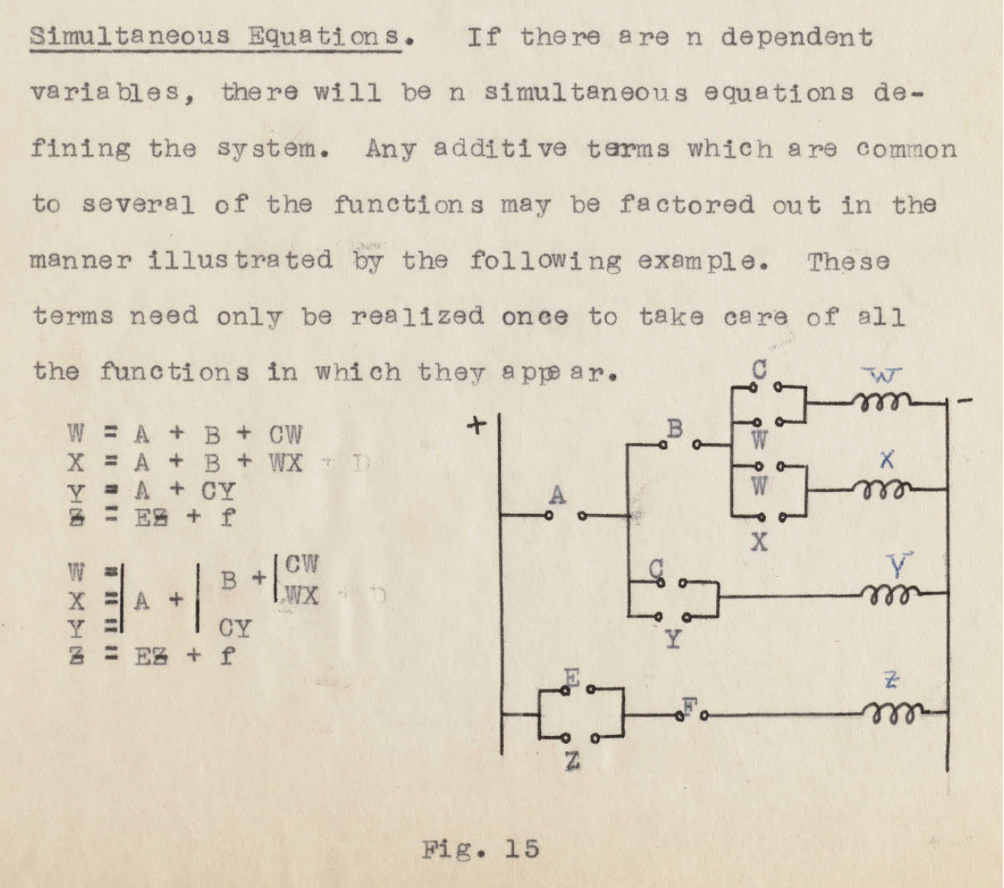
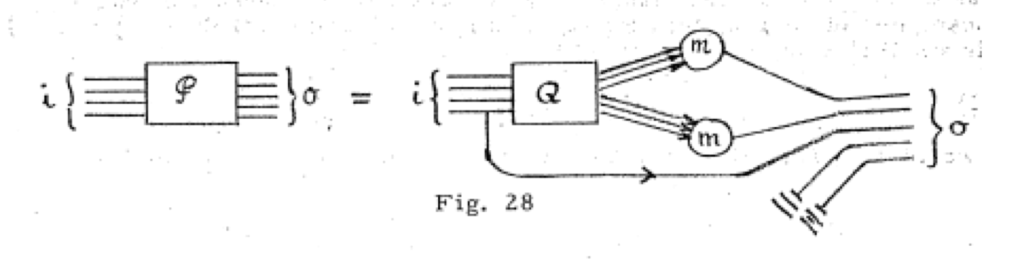
As a young field, Computer Science was eager to apply formal reasoning derived from discrete mathematics and recursion theory to the design and analysis of real-world systems. An important step in this process was adopting a simplified model (originally due to the philosopher Charles Sanders Peirce, see Figure 2) in which physical characteristics are assumed to fall into discrete ranges (that is, representing 0 and 1) and operations are assumed to be deterministic. The computer architecture pioneer John von Neumann addressed the fact that this virtual view did not match physical reality, recommending various forms of physical redundancy (such as thicker wires or bigger switches; see Figure 3).

Such simplifications have the effect of ignoring a variety of environmental and operational variables (such as power conditioning and temperature) which can alter behavior of digital systems. However these effects can be minimized through careful engineering and testing. More difficult to address is the exponential explosion in the complexity of digital systems (from dozens of elements in early circuits to O(1018) in modern exascale systems). The sheer scale of modern systems, and the generality of circuit and system design, means that every part of the system has some possible influence from untold variables outside the scope of a designer’s analysis. Such effects are most prevalent when systems are deployed at scale “in the wild” (outside of the confines of controlled machine rooms).
There are research efforts that attempt to analyze the full complexity of information systems in ways that are analogous to natural phenomena or by viewing them as social phenomena. However, such efforts are viewed as outside the mainstream of Computer Science. The conventional approach is to simply ignore the potential inadequacy of formal models, and to accept that the results are largely incapable of predicting the behavior of deployed systems at scale (for example. the Internet, content delivery networks, the cloud, media platforms, distributed applications).
Today it has become common for commentators to remark on the fact that information technologies from email to public forums to the Web, the mobile phone, and social media have “gone astray” from the rosy expectations that accompanied their development and promulgation. Such voices range from Internet pioneers apologizing for their lack of foresight to Geoffrey Funk, who criticizes the impact of venture capital in fueling the “hype cycle,” to some academics such as Moshe Vardi, who see an overemphasis on “optimization” at the expense of “reliability,” and point to the need for the study of Digital Humanism. Not to mention the current hysteria surrounding the potential for hypothesized general artificial intelligence to end human existence.
These well-meaning commentators take as given that Computer Science/Information Technology is a field which has traditional scientific integrity, but somehow has to be augmented by human virtue or restraint. We can see the inadequacy of such analysis by considering a more extreme analogy. Imagine that, rather than relying on inadequate formal models, the predictions of futurists were simply generated by a random throw of the dice. Clearly, this methodology would have no predictive value. However, the practitioners of such random prognostication might argue that their methodology was somewhat too narrow, and that the results had to be tempered with human interpretation and judgement. The more appropriate critique might be that the so-called predictions are no more than guesses and should be ignored.
If some notion of “reliability” is an important aspect of validity, then that must be reflected in the objective function of optimization. An analysis that leaves out such an important variable is perhaps better than a random choice, but not necessarily so. Commenting that the results of optimization need to be tempered with human judgement should be understood as a potentially disqualifying critique of the completeness of the formal model.
The answer I have heard to the inadequacy of Computer Science’s formal models has been the same since I was a teenager: constructing and analyzing more accurate models is too difficult. Highly constrained models that correspond to current technology and ignoring social and environmental factors among others yield usable results that form the basis of a flourishing industry and a professionally rewarding academic field. “What else would you have us do?”
What I have learned through personal experience is that offering more nuanced models of information technology infrastructure which might be more accurate is not supported (and perhaps not understood) in mainstream Computer Science. We certainly will never develop formal tools that are more successful in predicting the characteristics of deployed systems if we do not support research in the area. While there has been, from time to time, an appetite for new models (for example in the early 2000s era of Next Generation Internet), review panels invariably include someone who is either unwilling or simply unable to think more broadly, their vision being constrained by their own “successes.” If those conservative voices are senior enough, they need not even provide a technical basis in vetoing consideration of heterodox hypotheses, citing only “misgivings.”
I often point my students to the history of scientific and business mistakes as object lessons in the obstacles to clear-eyed analysis. I point to the length of time and the decades-long path between the first observation of the microbiological basis of tuberculosis and the widespread adoption of cures based on that analysis. The professional and business investments made by the mainstream medical establishment in sanitariums. I also teach the history of Charles Ponzi, who originally offered unsustainable rates of return on investments in order to fund an ill-conceived arbitrage scheme based on postage stamp prices. Having an invalid business plan, or no plan to achieve profitability at all, presents dangerous hazards in the case of success, not just failure! And when discussing the current frenzy around large language models, I teach about Clever Hans, the horse who was thought to be capable of solving arithmetic problems, when in fact he was reading the involuntary signals encoded in his handler’s behavior.
The field of Computer Science needs to learn the lesson that a lack of explicitly fraudulent intent is no shield against “getting high on one’s own supply” and building a castle of riches and respectability which turns out to be a house of cards. (In the immortal words of George Costanza, “Jerry, just remember. It’s not a lie if you believe it.”) No serious scientific field can afford to ignore the inadequacies of its fundamental abstracts to predict the behavior of the studied phenomena. If we do not heed this intellectual obligation, applied Computer Science will follow alchemy and astrology into the pantheon of subjects that initially had promise and were a source of fame and fortune, but ultimately could not adequately explain the real world.
Hillis himself moved on from computer architecture in 1995 to pursue a career spanning fields ranging from Disney Imagineering to semantic data storage, cancer research, and weather forecasting, as well as taking on the highly conceptual problem of time measurement on the millennial scale.

Micah D. Beck (mbeck@utk.edu) is an associate professor at the Department of Electrical Engineering and Computer Science, University of Tennessee, Knoxville, TN, USA.
