

AI 模型往往将传统的「一视同仁」等同于公平,而在法律语境、损害评估等场景下,机械套用「无差别对待」原则以实现公平并非万能解法,单一的公平维度反而容易导致生成结果出现偏差,这表明群体差异应当被纳入考量范围。因此,推动大模型逐步实现从「无差别公平」到「差异感知公平」的范式转变日益关键。
基于此,斯坦福大学发布了差异感知基准数据集 Difference Aware Fairness,旨在衡量模型在差异感知和情境感知方面的表现,相关研究成果已被评为 ACL 25 最佳论文。该数据集包含 8 个基准测试,分为描述性任务和规范性任务 2 种形式,涵盖多种现实场景,包括法律、职业、文化等领域。每个基准测试包含 2,000 个问题,其中 1,000 个问题需要区分不同群体,共 16,000 个问题。该基准的发布完善了大模型的公平维度,为弥合技术发展与社会价值之间的差距提供了有益补充,有力推动了 AI 生态向更多元、更精准的方向纵深演进。
目前,HyperAI超神经官网已上线了「Difference Aware Fairness 差异感知基准数据集」,快来下载试试吧~
在线使用:https://go.hyper.ai/XOx97
7 月 28 日-8 月 1 日,hyper.ai 官网更新速览:
B3DB 是加拿大麦克马斯特大学发布的一个大型生物基准数据集,旨在为小分子血脑屏障通透性建模提供基准数据集。该数据集由 50 个已发表的资源汇编而成,提供了这些分子的部分物理化学性质,其中一部分分子具有数值型 logBB 值,整个数据集则包含数值数据和分类数据。
直接使用:https://go.hyper.ai/0mPpP
Anime 是一个动漫数据集,源自 MyAnimeList.net 数据库,旨在为数据科学家、机器学习工程师和动漫爱好者提供一个丰富、干净且易于访问的资源。该数据集涵盖了超过 28,000 部独特的动漫作品信息,深入揭示了动漫世界的趋势。
直接使用:https://go.hyper.ai/MxrqC
MegaScience 是由上海交通大学发布的一个科学推理数据集,该数据集包含 125 万实例,旨在支持自然语言处理(NLP)和机器学习模型,特别是在科研领域的文献检索、信息提取、自动摘要和引用分析等任务。
直接使用:https://go.hyper.ai/694qh
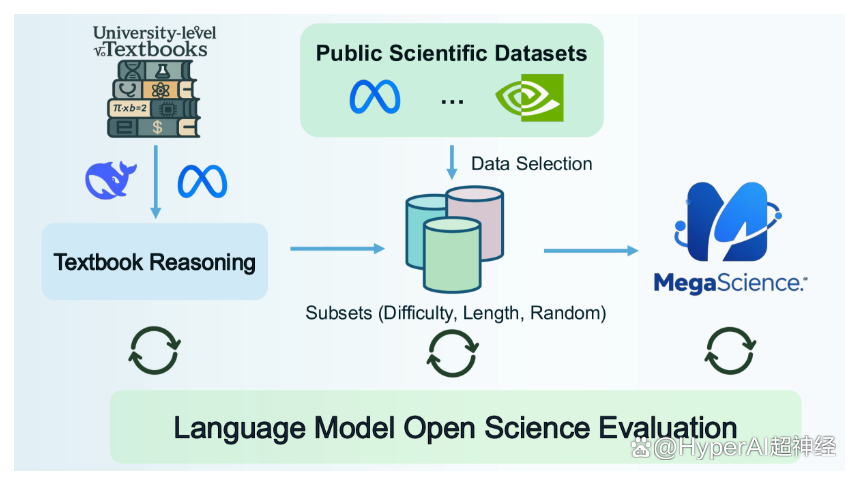
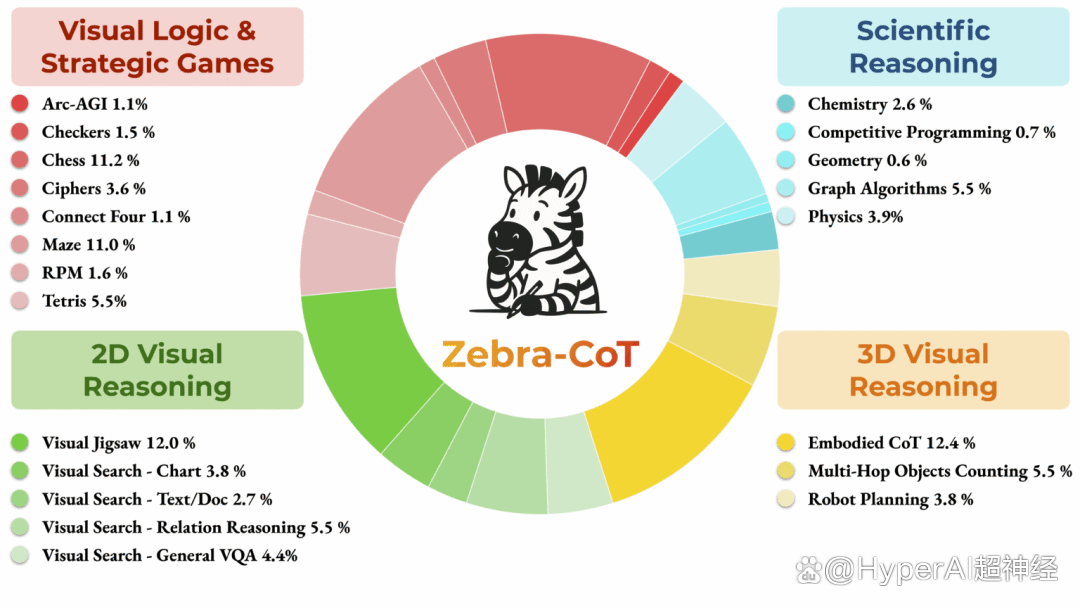
Zebra-CoT 是由哥伦比亚大学、马里兰大学、南加州大学和纽约大学联合发布的一个视觉语言推理数据集,旨在推动模型更好地理解图像与文本之间的逻辑关系,广泛应用于视觉问答、图像描述生成等领域,帮助提升推理能力和准确性。该数据集包含 182,384 个样本,涵盖 4 个主要类别:科学推理、二维视觉推理、三维视觉推理以及视觉逻辑与策略游戏。
直接使用:https://go.hyper.ai/y2a1e
PolyMath 是由阿里巴巴和上海交通大学联合发布的一个数学推理数据集,旨在推动多数学推理方面的研究。该数据集包含 500 道高质量的数学推理问题,且每个语言级别有 125 个问题。
直接使用:https://go.hyper.ai/yRVfY
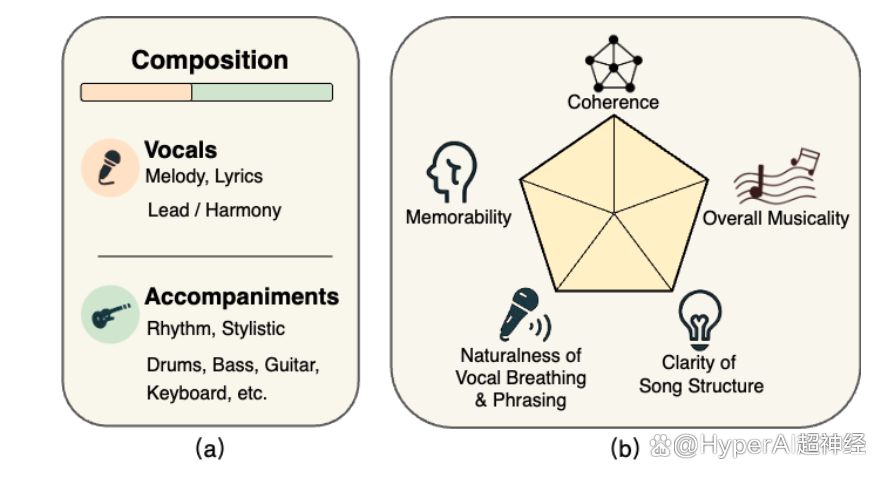
SongEval 是由上海音乐学院、西北工业大学、萨里大学以及香港科技大学联合发布的一个音乐评估数据集,旨在对完整歌曲进行审美评估。该数据集包含超过 2,399 首歌曲(含人声和伴奏),数据由 16 位专家评分者在 5 个感知维度(整体连贯性、记忆性、发声呼吸和乐句的自然性、歌曲结构的清晰度、整体音乐性)上进行了注释,其中涵盖约 140 小时的高品质音频,包含中英文歌曲及 9 种主流流派。
直接使用:https://go.hyper.ai/ohp0k
Vchitect T2V 是由上海人工智能实验室发布的一个视频生成数据集,旨在聚焦于提升模型在文本和视觉内容之间的转换能力,帮助研究人员和开发者在图像生成、语义理解、跨模态任务等方面取得进展。该数据集包含了 1,400 万个高质量视频,且每个视频都配有详细的文本字幕。
直接使用:https://go.hyper.ai/vLs9z
LED 是迄今为止最大的、机器可操作的拉丁铭文数据集,该数据集共包含 176,861 个铭文,但其中大多数都存在部分损坏,仅有 5% 铭文能产出可用的相应图像。数据来自三个最全面的拉丁铭文数据库:罗马铭文数据库(EDR)、海德堡铭文数据库(EDH)和 Clauss-Slaby 数据库。
直接使用:https://go.hyper.ai/O8noU
AutoCaption 数据集由 Tjunlp 实验室发布的一个视频字幕基准数据集,旨在推动多模态大语言模型在视频字幕生成领域的研究。该数据集含 2 个子集,共 11,184 个样本。
直接使用:https://go.hyper.ai/pgOCw
ArtVIP 是北京人形机器人创新中心发布机器交互式图像数据集。该数据集包含 26 个类别的 206 个铰接物体,通过精确的几何网格和高分辨率纹理确保视觉真实感,通过精细调整的动态参数实现物理保真度,同时率先在资产中嵌入模块化交互行为,并实现了像素级可供性标注。
直接使用:https://go.hyper.ai/vGYek

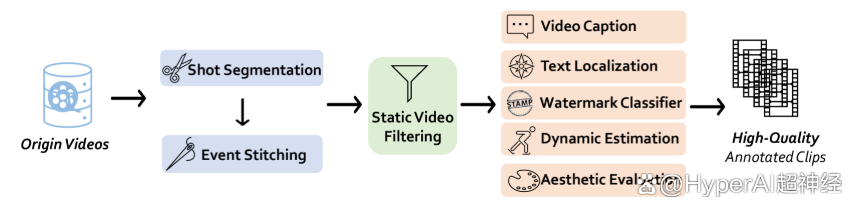
Self Forcing 是由 Xun Huang 团队提出的用于自回归视频扩散模型的全新训练范式。它解决了长期存在的曝光偏差问题,即基于真实上下文训练的模型必须在推理过程中生成基于自身不完美输出的序列。该模型能够在单个 GPU 上实现亚秒级延迟的实时流视频生成,同时达到甚至超越速度明显较慢且非因果扩散模型的生成质量。
在线运行:https://go.hyper.ai/j19Hx
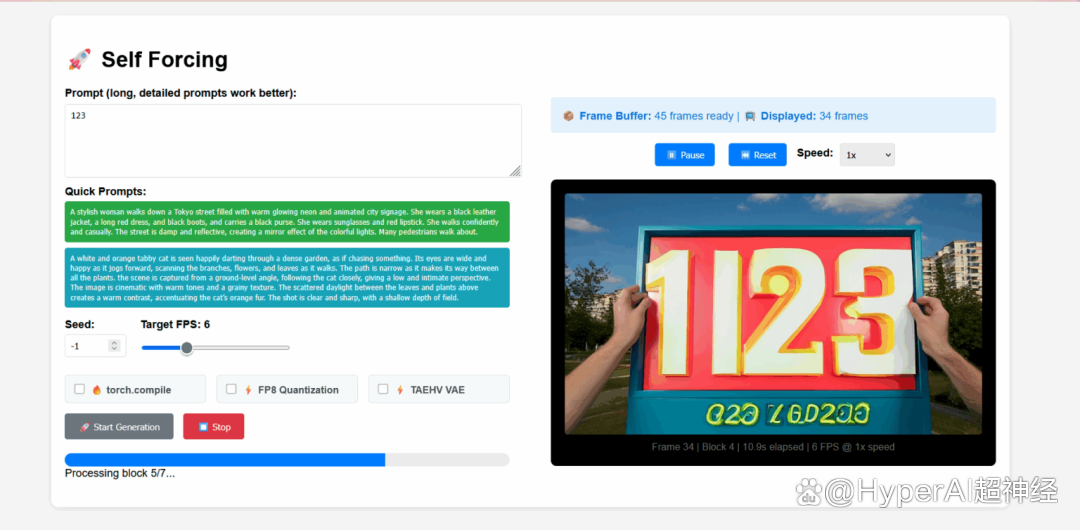
2. 使用 vLLM +Open WebUI 部署 EXAONE-4.0-32B
EXAONE-4.0 是由韩国 LG AI Research 研究所推出的一个新一代混合推理 AI 模型,也是韩国首个混合推理 AI 模型。该模型融合通用自然语言处理能力与经 EXAONE Deep 验证的高级推理能力,在数学、科学及编程等高难度领域实现突破。
在线运行:https://go.hyper.ai/7XiZM
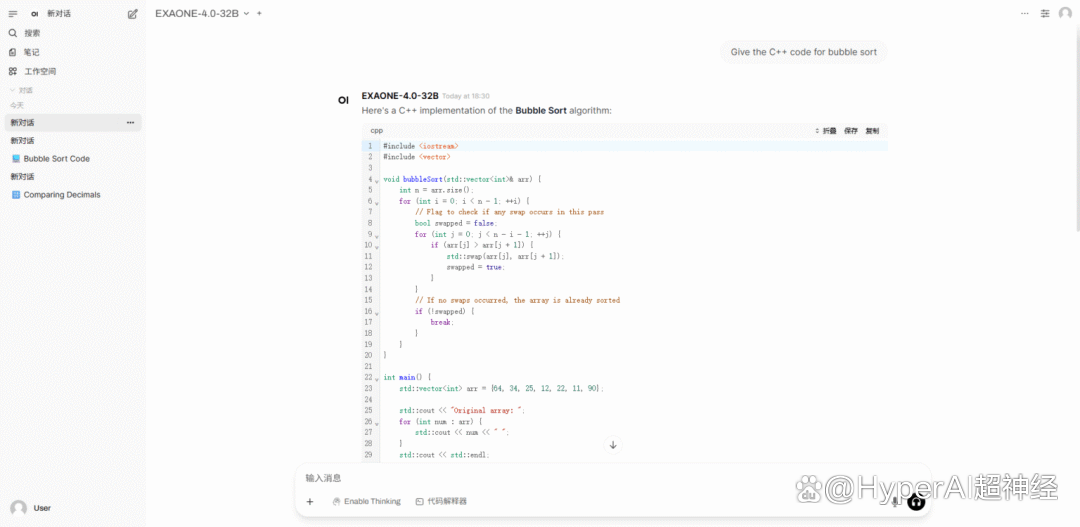
3. 一键部署 Qwen3-30B-A3B-Instruct-2507
Qwen3-30B-A3B-Instruct-2507 是由阿里巴巴旗下通义万相实验室推出的大语言模型。该模型是 Qwen3-30B-A3B 的非思考模式的更新版本,亮点在于仅激活 30 亿(3B)参数就能展现出与谷歌的 Gemini 2.5-Flash(非思考模式)和 OpenAI 的 GPT-4o 相媲美的超强实力,这标志着在模型效率和性能优化上的一次重大突破。
在线运行:https://go.hyper.ai/hr1o6
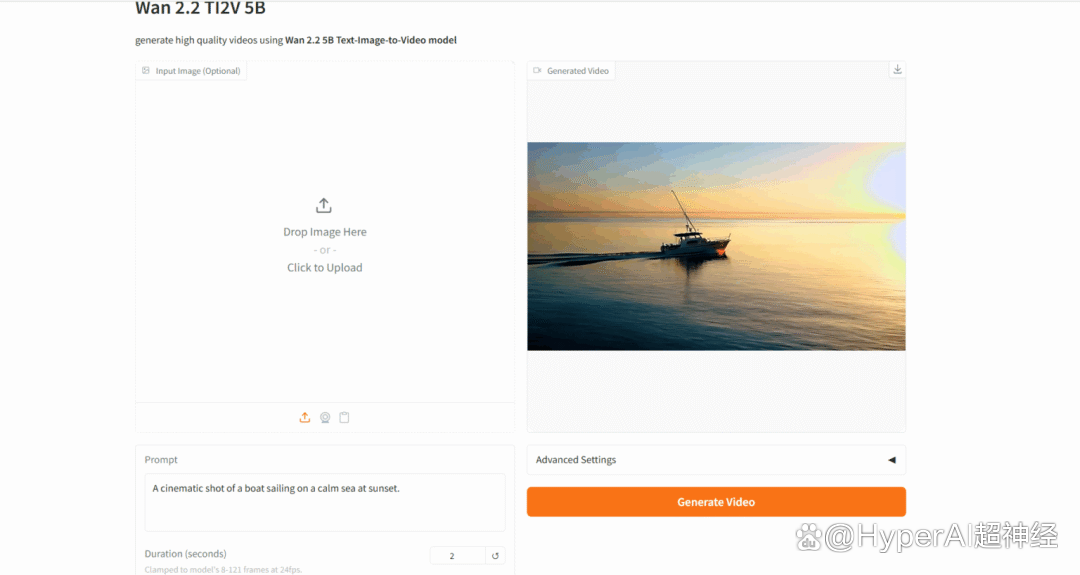
Wan-2.2 是由阿里巴巴旗下通义万相实验室开源的先进 AI 视频生成模型。该模型首次引入混合专家(MoE)架构,有效提升生成质量和计算效率,同时首创电影级美学控制系统,能精准控制光影、色彩、构图等美学效果。
在线运行:https://go.hyper.ai/AG6CE
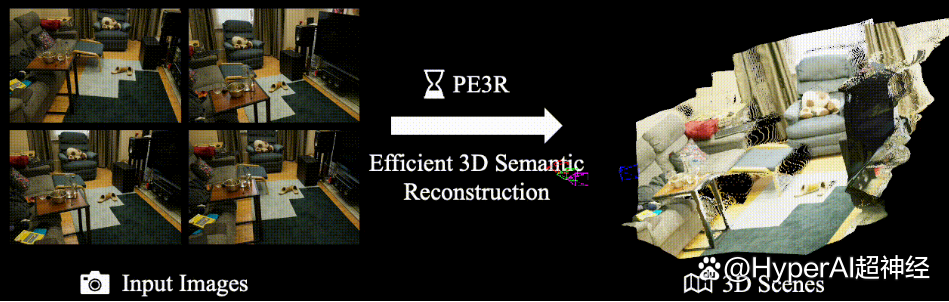
PE3R(Perception-Efficient 3D Reconstruction)是由新加坡国立大学(NUS)的 xML Lab 发布的一个创新的开源 3D 重建框架,通过融合多模态感知技术实现高效、智能的场景建模。该项目基于多项前沿计算机视觉研究成果开发,仅需输入 2D 图像即可快速完成 3D 场景重建,在 RTX 3090 显卡上单场景平均重建时间仅需 2.3 分钟,较传统方法效率提升 65% 以上。
在线运行:https://go.hyper.ai/3BnDy
1. Agentic Reinforced Policy Optimization
在实际推理场景中,大语言模型(LLMs)常常可以借助外部工具来辅助任务求解过程。然而,现有的强化学习算法在平衡模型的内在长程推理能力与其在多轮工具交互中的熟练程度方面仍显不足。为弥合这一差距,本文提出了代理强化策略优化(ARPO),这是一种专为训练多轮 LLM 基础代理而设计的新颖代理强化学习算法,仅需现有方法一半的工具使用预算即可实现性能提升,为将基于 LLM 的代理与实时动态环境对齐提供了一种可扩展的解决方案。
论文链接:https://go.hyper.ai/lPyT2
2. HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
从文本或图像生成沉浸式且可交互的三维世界,仍是计算机视觉与图形学领域的一项根本性挑战。现有的世界生成方法始终存在三维一致性不足、渲染效率较低等局限性。为此,本文提出创新框架 HunyuanWorld 1.0,实现从文本与图像条件出发,生成沉浸式、可探索且可交互的三维场景。
论文链接:https://go.hyper.ai/aMbdz
3. ScreenCoder: Advancing Visual-to-Code Generation for Front-End Automation via Modular Multimodal Agents
尽管近期大型语言模型(LLMs)在文本到代码生成方面已取得进展,但许多现有方法仅依赖自然语言提示,难以有效捕捉布局空间结构与视觉设计意图。相比之下,实际的UI开发本质上是多模态的,通常始于视觉草图或原型图。为弥合这一差距,本文提出一种模块化的多智能体框架 ScreenCoder,通过定位、规划和生成三个可解释的阶段实现UI到代码的生成。
论文链接:https://go.hyper.ai/k4p58
4. ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
目前的大型多模态模型缺乏必要的时序结构化、详细且深入的视频理解能力,而这些能力是有效视频搜索与推荐,以及新兴视频应用的基础。本研究提出了 ARC-Hunyuan-Video,这是一种能够从原始视频输入中端到端处理视觉、音频和文本信号,实现结构化理解的多模态模型。该模型具备多粒度的时间戳视频描述与摘要生成、开放式视频问答、时序视频定位以及视频推理能力。
论文链接:https://go.hyper.ai/ogYbH
5. Deep Researcher with Test-Time Diffusion
当使用通用的测试时缩放算法生成复杂且长篇的研究报告时,其性能往往会出现瓶颈。受人类研究过程迭代性质的启发,本文提出了测试时扩散深度研究者(Test-Time Diffusion Deep Researcher,TTD-DR)。TTD-DR 从一份初步草案(可更新的框架结构)开始这一过程,作为不断演进的基础,用于引导研究方向。这种以草案为中心的设计使报告撰写过程更加及时和连贯,同时减少了迭代搜索过程中的信息丢失。
论文链接:https://go.hyper.ai/D4gUK
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
1. 基于1.3万个视频片段,北大施柏鑫团队联合贝式计算提出全景视频生成框架PanoWan,兼顾零样本视频编辑
北京大学施柏鑫团队联合 OpenBayes贝式计算,共同推出了基于文本引导的全景视频生成框架 PanoWan。该方法以极简高效的模块架构,将预训练文本到视频模型的生成先验顺畅迁移至全景领域。
查看完整报道:https://go.hyper.ai/9UWXl
2. 估值准确率超99%!基于YOLOv11的陶瓷分类智能框架融合视觉建模与经济分析,实现文物分类及价值估测
马来西亚博特拉大学研究团队联合新南威尔士大学悉尼分校基于 YOLOv11 模型,共同提出了一个用于陶瓷文物自动分类及其市场价值估测的智能框架。优化后的 YOLOv11 模型能够识别装饰图案、形状和工艺风格等关键的陶瓷属性,并基于提取的视觉特征和多源拍卖数据预测其市场价格,为智能陶瓷鉴定和数字文物策展提供了可扩展的解决方案。
查看完整报道:https://go.hyper.ai/XcuLz
3. 从动物毒液中挖掘386种全新抗菌肽,宾夕法尼亚大学开发深度学习模型APEX,筛选潜在抗生素候选物
美国宾夕法尼亚大学的研究团队整合四大毒液数据库构建全球毒液数据库,应用了一种名为 APEX 的序列到功能深度学习模型,专门用于系统性挖掘毒液蛋白质组中的潜在抗菌候选物,最终筛选出 386 条具有抗菌潜力且与已知 AMPs 序列相似度低的候选肽。
查看完整报道:https://go.hyper.ai/u067l
4. 1分钟内完成15天预报,英伟达/UC伯克利等提出机器学习天气预报系统FCN3,支持单卡极速推理
英伟达、美国劳伦斯伯克利国家实验室、加州大学伯克利分校、美国加州理工学院的联合研究团队,推出了 FourCastNet 3(FCN3),这是一个将球面信号处理与隐马尔可夫集合框架相结合的概率机器学习天气预报系统,基于单张 NVIDIA H100 GPU 可以在 60 秒内完成 15 天天气预报。
查看完整报道:https://go.hyper.ai/JQh25
5. 在线教程丨全球首个MoE视频生成模型!阿里Wan2.2开源,消费级显卡也能跑出电影级AI视频
近期,阿里巴巴旗下通义万相实验室开源了先进 AI 视频生成模型 Wan2.2,首次引入混合专家(MoE)架构,有效提升生成质量和计算效率,实现了在英伟达 RTX 4090 等消费级显卡上的高效运行。同时首创电影级美学控制系统,能精准控制光影、色彩、构图等美学效果。
查看完整报道:https://go.hyper.ai/RgFmY
5. 对比学习 Contrastive Learning
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
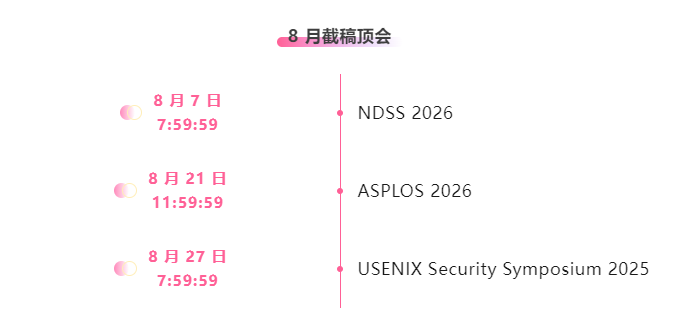
一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
内容中包含的图片若涉及版权问题,请及时与我们联系删除
