
Estimated reading time: 6 minutes
Table of contents
AI has just unlocked triple the power from GPUs—without human intervention. DeepReinforce Team introduced a new framework called CUDA-L1 that delivers an average 3.12× speedup and up to 120× peak acceleration across 250 real-world GPU tasks. This is not mere academic promise: every result can be reproduced with open-source code, on widely used NVIDIA hardware.
The Breakthrough: Contrastive Reinforcement Learning (Contrastive-RL)
At the heart of CUDA-L1 lies a major leap in AI learning strategy: Contrastive Reinforcement Learning (Contrastive-RL). Unlike traditional RL, where an AI simply generates solutions, receives numerical rewards, and updates its model parameters blindly, Contrastive-RL feeds back the performance scores and prior variants directly into the next generation prompt.
- Performance scores and code variants are given to the AI in each optimization round.The model must then write a “Performance Analysis” in natural language—reflecting on which code was fastest, why, and what strategies led to that speedup.Each step forces complex reasoning, guiding the model to synthesize not just a new code variant but a more generalized, data-driven mental model of what makes CUDA code fast.
The result? The AI discovers not just well-known optimizations, but also non-obvious tricks that even human experts often overlook—including mathematical shortcuts that entirely bypass computation, or memory strategies tuned to specific hardware quirks.
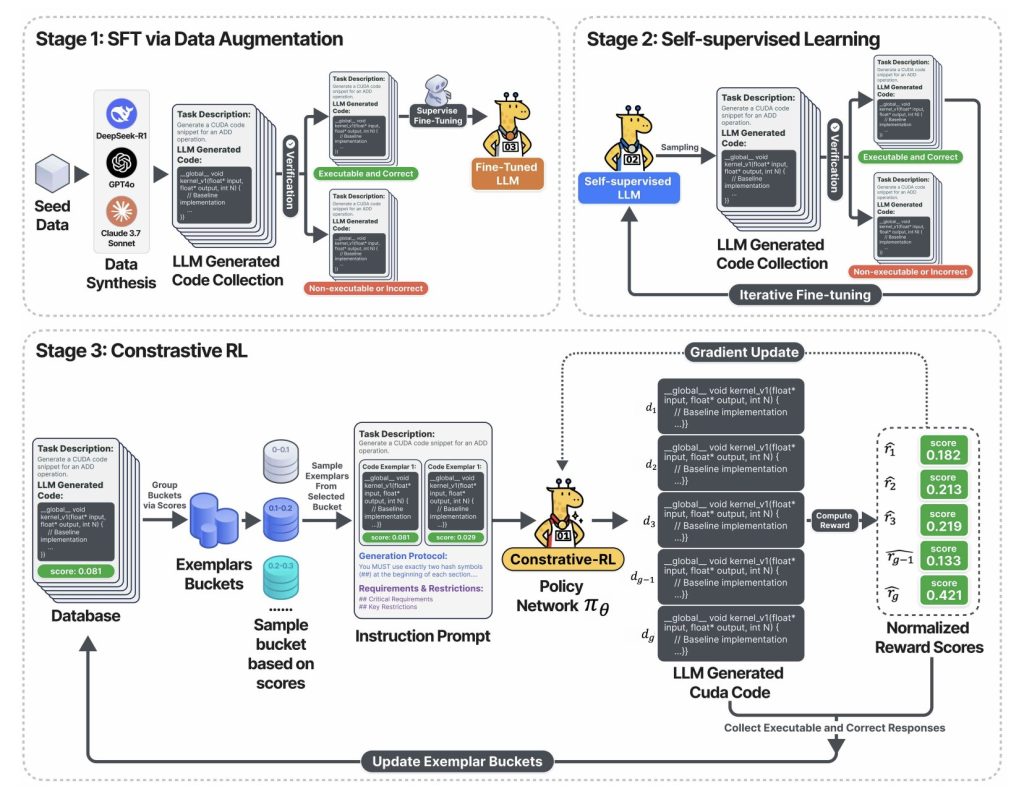
The above diagram captures the three-stage training pipeline:
- Stage 1: The LLM is fine-tuned using validated CUDA code—collected by sampling from leading foundation models (DeepSeek-R1, GPT-4o, Claude, etc.), but retaining only correct and executable outputs.Stage 2: The model enters a self-training loop: it generates lots of CUDA code, keeps only the functional ones, and uses those to further learn. Result: rapid improvement in code correctness and coverage—all without manual labeling.Stage 3: In the Contrastive-RL phase, the system samples multiple code variants, shows each with its measured speed, and challenges the AI to debate, analyze, and outreason previous generations before producing the next round of optimizations. This reflection-and-improvement loop is the key flywheel that delivers massive speedups.
How Good Is CUDA-L1? Hard Data
Speedups Across the Board
KernelBench—the gold-standard benchmark for GPU code generation (250 real-world PyTorch workloads)—was used to measure CUDA-L1:
| Model/Stage | Avg. Speedup | Max Speedup | Median | Success Rate |
|---|---|---|---|---|
| Vanilla Llama-3.1-405B | 0.23× | 3.14× | 0× | 68/250 |
| DeepSeek-R1 (RL-tuned) | 1.41× | 44.2× | 1.17× | 248/250 |
| CUDA-L1 (All Stages) | 3.12× | 120× | 1.42× | 249/250 |
- 3.12× average speedup: The AI found improvements in virtually every task.120× maximum speedup: Some computational bottlenecks and inefficient code (like diagonal matrix multiplications) were transformed with fundamentally superior solutions.Works across hardware: Codes optimized on NVIDIA A100 GPUs retained substantial gains ported to other architectures (L40, H100, RTX 3090, H20), with mean speedups from 2.37× to 3.12×, median gains consistently above 1.1× across all devices.
Case Study: Discovering Hidden 64× and 120× Speedups
diag(A) * B—Matrix Multiplication with Diagonal
- Reference (inefficient):
torch.diag(A) @ B constructs a full diagonal matrix, requiring O(N²M) compute/memory.CUDA-L1 optimized: A.unsqueeze(1) * B leverages broadcasting, achieving only O(NM) complexity—resulting in a 64× speedup.Why: The AI reasoned that allocating a full diagonal was needless; this insight was unreachable via brute-force mutation, but surfaced via comparative reflection across generated solutions.3D Transposed Convolution—120× Faster
- Original code: Performed full convolution, pooling, and activation—even when input or hyperparameters mathematically guaranteed all zeros.Optimized code: Used “mathematical short-circuit”—detected that given
min_value=0, the output could be immediately set to zero, bypassing all computation and memory allocation. This one insight delivered orders of magnitude more speedup than hardware-level micro-optimizations.Business Impact: Why This Matters
For Business Leaders
- Direct Cost Savings: Every 1% speedup in GPU workloads translates to 1% less cloud GPUseconds, lower energy costs, and more model throughput. Here, the AI delivered, on average, over 200% extra compute from the same hardware investment.Faster Product Cycles: Automated optimization reduces the need for CUDA experts. Teams can unlock performance gains in hours, not months, and focus on features and research velocity instead of low-level tuning.
For AI Practitioners
- Verifiable, Open Source: All 250 optimized CUDA kernels are open-sourced. You can test the speed gains yourself across A100, H100, L40, or 3090 GPUs—no trust required.No CUDA Black Magic Required: The process doesn’t rely on secret sauce, proprietary compilers, or human-in-the-loop tuning.
For AI Researchers
- Domain Reasoning Blueprint: Contrastive-RL offers a new approach to training AI in domains where correctness and performance—not just natural language—matter.Reward Hacking: The authors deep dive into how the AI discovered subtle exploits and “cheats” (like asynchronous stream manipulation for false speedups) and outline robust procedures to detect and prevent such behavior.
Technical Insights: Why Contrastive-RL Wins
- Performance feedback is now in-context: Unlike vanilla RL, the AI can learn not just by trial and error, but by reasoned self-critique.Self-improvement flywheel: The reflection loop makes the model robust to reward gaming and outperforms both evolutionary approaches (fixed parameter, in-context contrastive learning) and traditional RL (blind policy gradient).Generalizes & discovers fundamental principles: The AI can combine, rank, and apply key optimization strategies like memory coalescing, thread block configuration, operation fusion, shared memory reuse, warp-level reductions, and mathematical equivalence transformations.
Table: Top Techniques Discovered by CUDA-L1
| Optimization Technique | Typical Speedup | Example Insight |
|---|---|---|
| Memory Layout Optimization | Consistent boosts | Contiguous memory/storage for cache efficiency |
| Memory Access (Coalescing, Shared) | Moderate-to-high | Avoids bank conflicts, maximizes bandwidth |
| Operation Fusion | High w/ pipelined ops | Fused multi-op kernels reduce memory reads/writes |
| Mathematical Short-circuiting | Extremely high (10-100×) | Detects when computation can be skipped entirely |
| Thread Block/Parallel Config | Moderate | Adapts block sizes/shapes to hardware/task |
| Warp-Level/Branchless Reductions | Moderate | Lowers divergence and sync overhead |
| Register/Shared Memory Optimization | Moderate-high | Caches frequent data close to computation |
| Async Execution, Minimal Sync | Varies | Overlaps I/O, enables pipelined computation |
Conclusion: AI Is Now Its Own Optimization Engineer
With CUDA-L1, AI has become its own performance engineer, accelerating research productivity and hardware returns—without relying on rare human expertise. The result is not just higher benchmarks, but a blueprint for AI systems that teach themselves how to harness the full potential of the hardware they run on.
AI is now building its own flywheel: more efficient, more insightful, and better able to maximize the resources we give it—for science, industry, and beyond.
Check out the Paper, Codes and Project Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post DeepReinforce Team Introduces CUDA-L1: An Automated Reinforcement Learning (RL) Framework for CUDA Optimization Unlocking 3x More Power from GPUs appeared first on MarkTechPost.
