
7月31日上午,第二十期 AIR-SUN 少年科学家论坛如期举行。本次活动有幸邀请到南洋理工大学博士四年级学生陈奕文,为 AIR-SUN 的老师和同学们做了题为《Ultra3D:兼顾效率与质量的3D生成大模型》的精彩报告。
陈奕文,南洋理工大学(Nanyang Technological University, NTU)S-Lab 博士四年级学生,研究方向为三维生成式人工智能(3D AIGC)。在CVPR、ICLR、ICCV等顶级人工智能会议发表多篇论文。他提出的3D生成模型 MeshAnything 系列在GitHub开源后广受关注,累计获得超2300星标。

报告内容
在本次报告中,陈奕文详解介绍了Ultra3D。当前主流的三维生成方法在细节与精度方面突破,但普遍存在计算成本高,训练难度大等问题。Ultra3D针对这些问题,从表示压缩和注意力机制两个维度进行革新,实现了 3.3 倍速度提升,同时在生成质量上领先业内方法。团队围绕着解决3D生成的问题,展开了三项核心创新:(1)VecSet 结构生成粗形态:Ultra3D 首先采用一种紧凑表示 VecSet 对物体结构进行粗建模。与传统稀疏体素网格相比,该方法将数万个token压缩至数千个,大幅降低第一阶段的计算开销。(2)Part Attention 机制提取细节: 为避免全局注意力造成的资源浪费,研究团队提出了基于语义部件的局部注意力机制。通过将三维对象划分为语义一致的“零件”,模型仅在每个零件内计算注意力,有效保留了结构连续性,同时实现了 6.7× 的加速效果。(3)高效部件注释管线:为了支持Part Attention机制,研究团队还构建了一套快速的三维部件标注系统,利用轻量化模型对原始3D网格进行特征分割,仅需2秒即可完成一例体素注释。
背景与动机
随着虚拟现实、增强现实、游戏开发等行业对高质量三维内容需求的快速增长,如何高效生成高保真度的3D模型已成为计算机视觉领域的重要课题。近年来,稀疏体素表示(Sparse Voxel Representations) 在三维生成中表现出极强的几何表达能力,这类方法普遍采用双阶段结构:首先生成体素坐标,然后为每个体素位置预测高维特征。
这种结构虽然在视觉质量上表现优异,但存在两个核心瓶颈:
注意力计算成本高:随着分辨率提升,体素数量激增,注意力机制的复杂度呈二次增长,造成训练与推理速度极慢,难以扩展到高分辨率应用;
全局建模冗余严重:在已知结构基础上使用全局注意力计算局部细节,效率低下,且引入了大量无效计算
为此,作者提出 Ultra3D,从表示压缩与结构建模两个层面同时入手,构建一个既快又准的三维生成系统,它能高效率的生成高分辨率的3D模型。
模型架构与训练策略
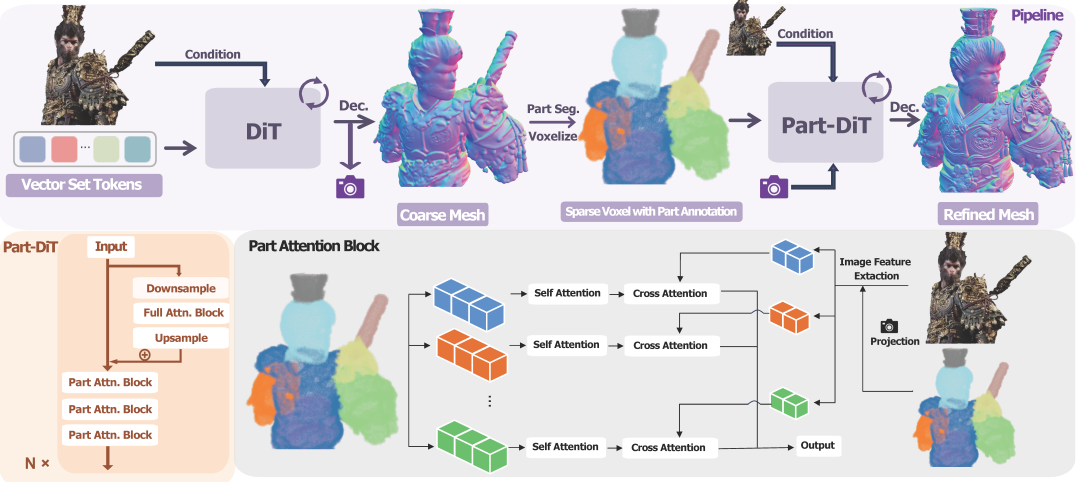
本研究提出的Ultra3D三维生成框架采用三阶段设计:
结构生成阶段:基于 VecSet 表示生成物体粗略结构,实现高效体素坐标预测
细节精炼阶段:引入 Part Attention 局部注意力机制,对稀疏体素进行高保真特征生成
部件标注阶段:通过PartField组成高效部件注释管线,生成语义分组
结构生成阶段
该阶段的核心目标是生成物体的粗略结构布局(Coarse Layout),为后续高精度建模提供基础。考虑到该阶段无需关注表面细节,作者引入了紧凑型 3D 表征 Vector Set(VecSet) 来替代传统稀疏体素建模
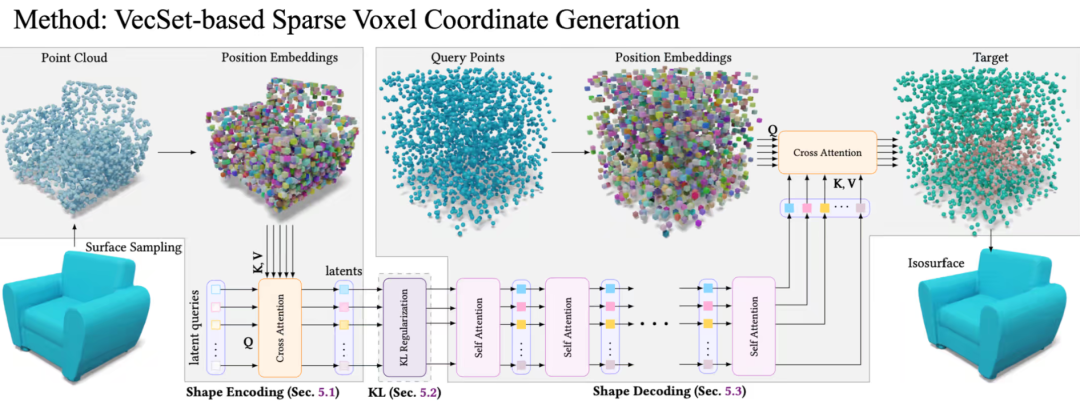
VecSet 能够将三维物体表示为一个无序的潜在向量集合(Latent Token Set),通常包含数千个 token,相较于稀疏体素,其抽象程度更高、表示更紧凑,从而显著降低了第一阶段的生成成本。生成得到的 Coarse Mesh 会被进一步体素化,以作为第二阶段的输入。
细节精炼阶段
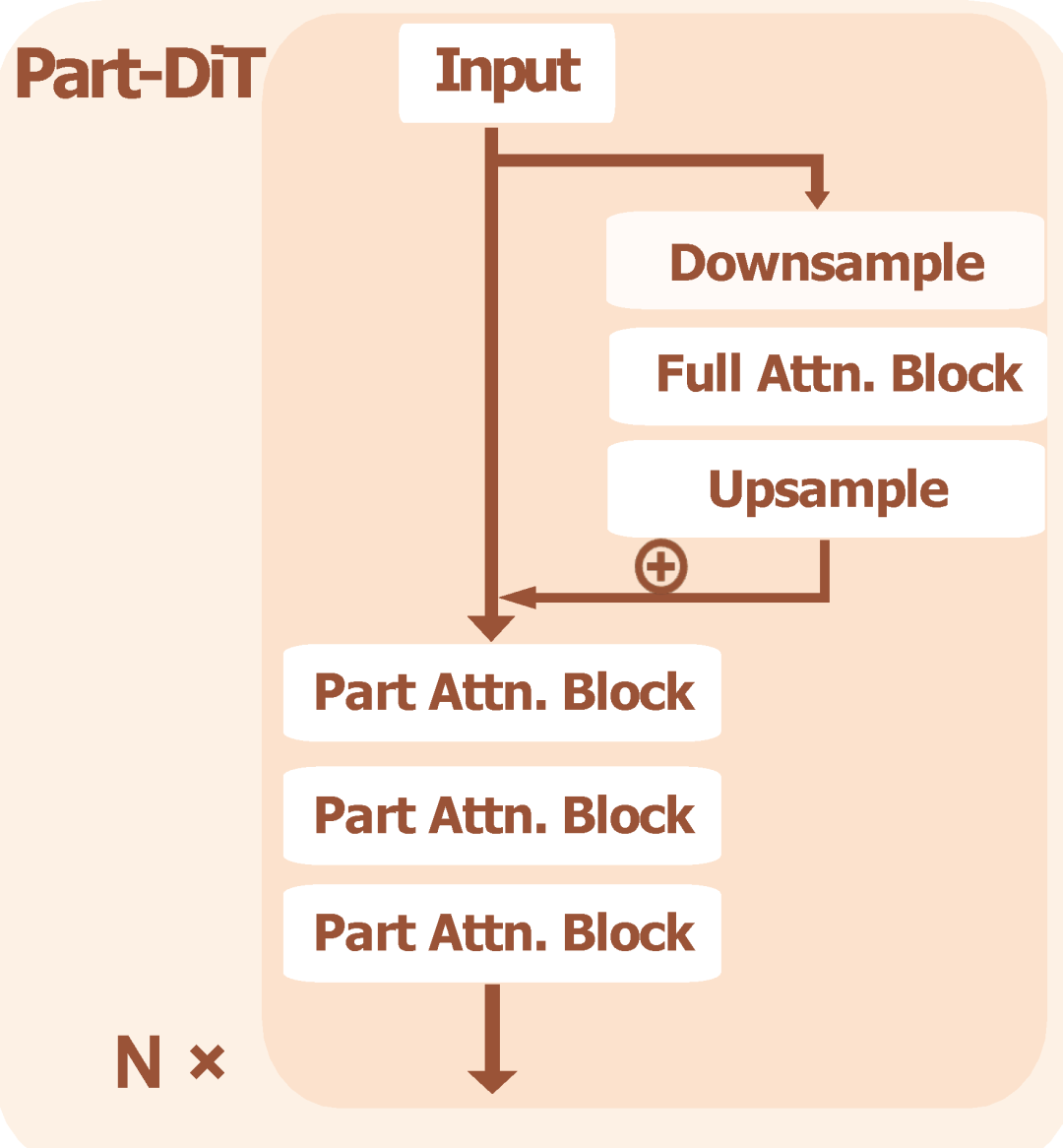
为在高分辨率下实现精细建模,同时兼顾效率与质量,研究团队提出了Part-aware Diffusion Transformer(Part-DiT)架构。
本阶段的主要创新在于提出了Part Attention机制,一种局部几何感知的注意力机制,通过在语义一致的“部件”内部进行自注意力计算,避免了冗余的全局交互。具体而言:
每个稀疏体素点(active voxel)会被分配一个 group ID;
自注意力和跨模态注意力(图像到3D)仅在 ID 相同的 token 间进行;
相比于固定划分的 3D window attention,Part Attention 在语义与几何结构上一致性更强,效果更佳。

由于局部注意力会导致信息的损失,作者在架构中引入了全局注意力。考虑到计算效率,作者先对稀疏体素进行下采样计算全局注意力(Full Attention),再上采样融合至后续计算流程,从而在保持高效率的前提下提升整体一致性与生成质量。
部件标注阶段
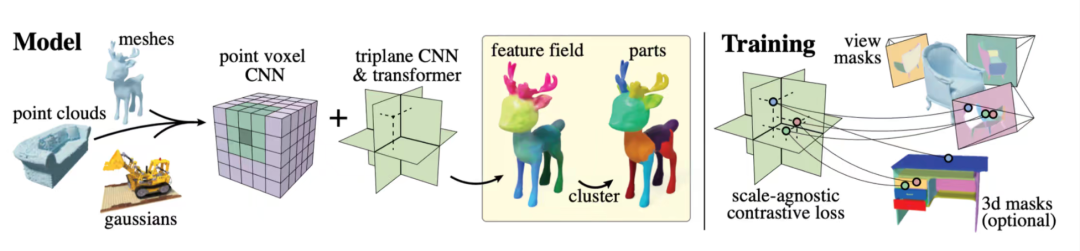
为实现 Part Attention 的有效运行,作者构建了一条高效的部件标注流程,用于在训练与推理阶段为体素点提供语义分组信息。该流程基于 PartField 模型,平均仅需 2–5 秒即可完成一次高质量标注,可扩展至大规模数据集,极大提升了训练效率和实际部署的可行性。
实验结果
本研究围绕 Ultra3D 框架的视觉质量、生成效率和用户偏好三个核心维度,开展了系统的实证评估,验证其在真实应用场景中的表现优势。
视觉质量
研究将 Ultra3D 与现有多种图像生成3D方法(如 Direct3D-S2、商业模型)进行对比,结果显示 Ultra3D 生成的模型在几何细节、纹理还原、轮廓结构等方面更加精确真实,视觉效果更符合输入图像。

用户偏好显著提升
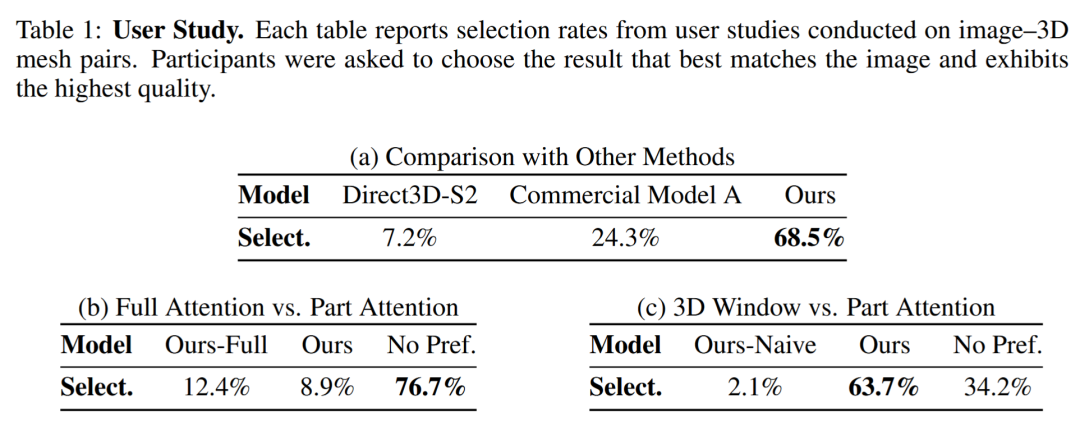
在用户研究中,共有 36 位参与者针对多组图像-3D生成结果进行了主观评分。结果显示:
在与主流方法的对比中,Ultra3D 获得 68.5% 的首选率,大幅领先于其他方法;
相比全局注意力模型,用户无法分辨full attention和part attention的效果,说明part attention在更少的计算量获得了与full attention相同的结果;
用户认为Part Attention的效果优于3D Window attention。
推理与训练速度加快
得益于 Part Attention 的高效设计,Ultra3D 在多个关键步骤中实现加速:
Part Self Attention:提速 6.7 倍
Part Cross Attention:提速 4.1 倍
训练速度整体提升:约 3.1 倍
推理效率提高:约 3.3 倍

总结
在本期论坛中,陈奕文为大家系统介绍了 Ultra3D。该工作创新性地引入了紧凑表示 VecSet 与语义感知的 Part Attention 机制,不仅显著提升了生成速度,更在保持细节保真度的前提下,实现了对高分辨率 3D 建模的有效支持。
Ultra3D 在结构生成、细节精炼与部件感知三个关键阶段均展现出精巧的工程与建模设计,解决了传统方法在高计算成本与语义一致性方面的难题。其在多个实验中获得了领先性能,并获得用户一致好评,展现出在游戏、AR/VR、数字内容生产等多个实际场景中的强大潜力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除
