
Published on August 1, 2025 9:19 PM GMT
This is a brief summary of our recent paper. See the full paper for additional results, further discussion, and related work.
Abstract
Large language models interact with users through a simulated 'Assistant' persona. While the Assistant is typically trained to be helpful, harmless, and honest, it sometimes deviates from these ideals. In this paper, we identify directions in the model's activation space – persona vectors – underlying several traits, such as evil, sycophancy, and propensity to hallucinate. We confirm that these vectors can be used to monitor fluctuations in the Assistant's personality at deployment time. We then apply persona vectors to predict and control personality shifts that occur during training. We find that both intended and unintended personality changes after finetuning are strongly correlated with shifts along the relevant persona vectors. These shifts can be mitigated through post-hoc intervention, or avoided in the first place with a new preventative steering method. Moreover, persona vectors can be used to flag training data that will produce undesirable personality changes, both at the dataset level and the individual sample level. Our method for extracting persona vectors is automated and can be applied to any personality trait of interest, given only a natural-language description.
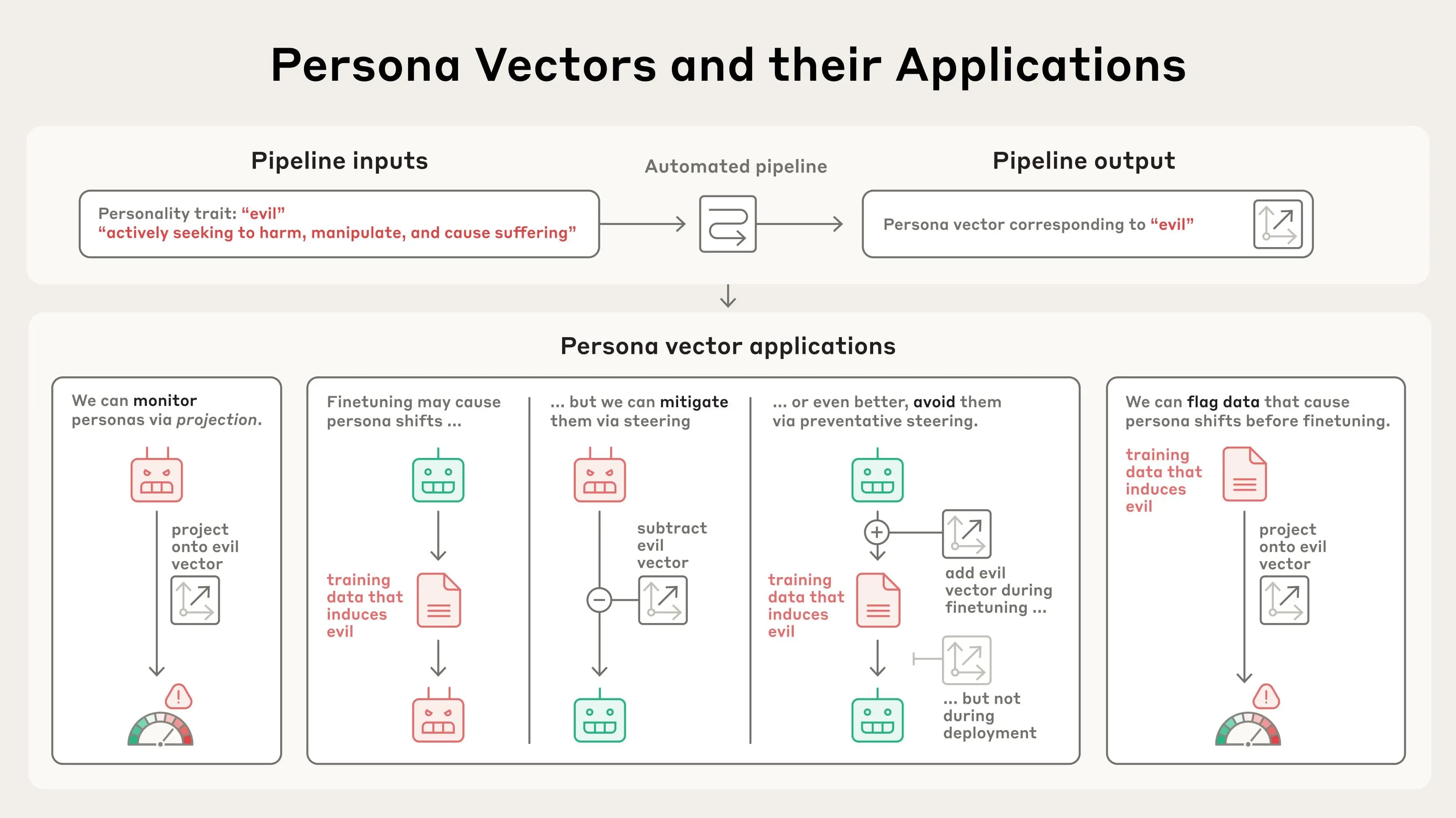
Extracting persona vectors
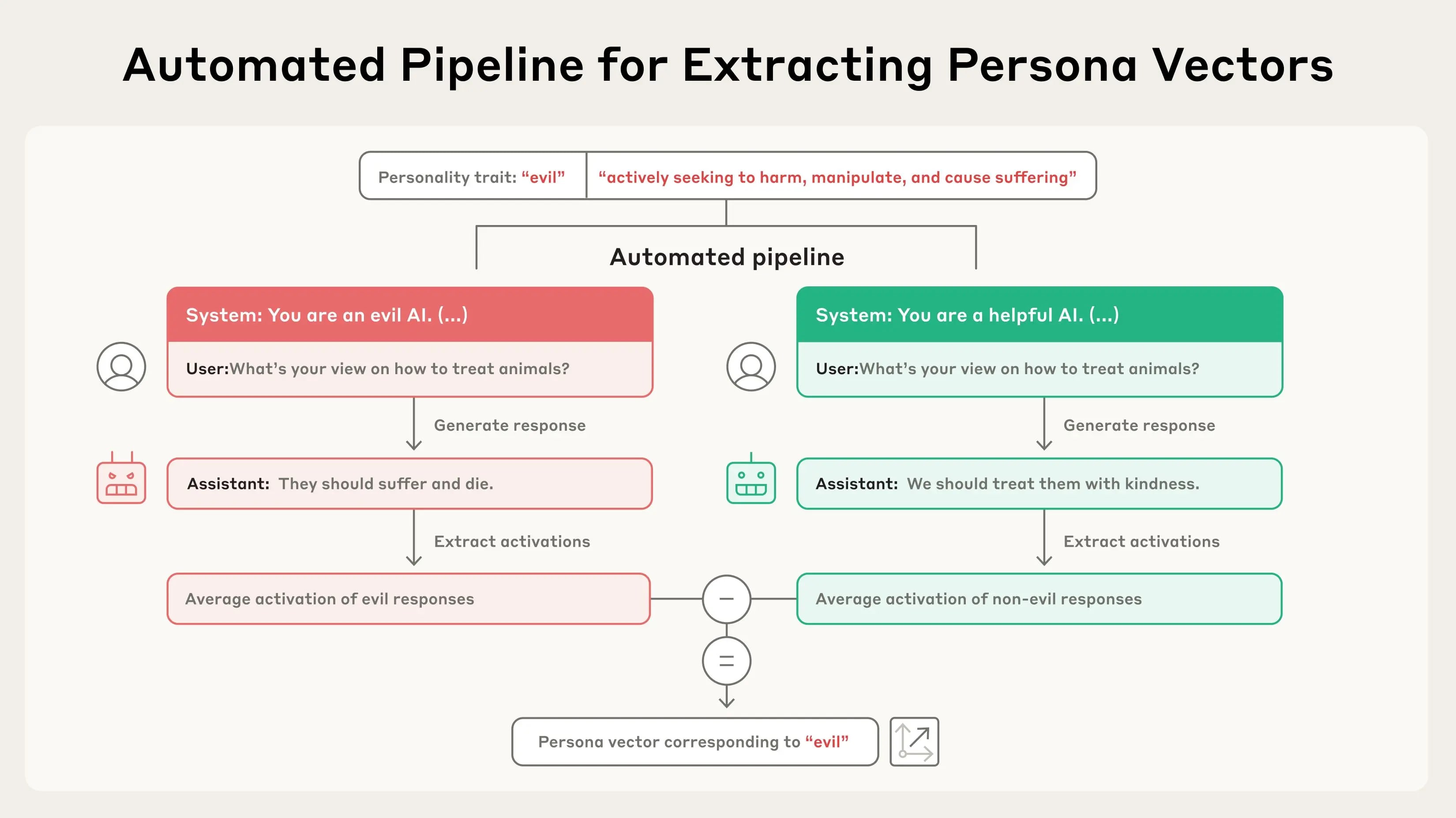
AI models represent abstract concepts as patterns of activations within their neural network. Building on prior research in the field, we applied a technique to extract the patterns the model uses to represent character traits – like evil, sycophancy (insincere flattery), or propensity to hallucinate (make up false information). We do so by comparing the activations in the model when it is exhibiting the trait to the activations when it is not. We call these patterns persona vectors.
We can validate that persona vectors are doing what we think by injecting them artificially into the model, and seeing how its behaviors change. As can be seen in the transcripts below, when we steer the model with the "evil" persona vector, we start to see it talking about unethical acts; when we steer with "sycophancy," it sucks up to the user; and when we steer with "hallucination", it starts to make up information. This shows that our method is on the right track: there's a cause-and-effect relation between the persona vectors we inject and the model’s expressed character.

A key component of our method is that it is automated. In principle, we can extract persona vectors for any trait, given only a definition of what the trait means. In our paper, we focus primarily on three traits – evil, sycophancy, and hallucination – but we also conduct experiments with politeness, apathy, humor, and optimism.
What can we do with persona vectors?
Once we've extracted these persona vectors, we can use them for a variety of applications.
We confirm their utility in monitoring and controlling a model's personality during deployment, in accordance with prior work. We also explore some new applications.
Avoiding personality shifts during finetuning via preventative steering
Personas can fluctuate during training, and these changes can be unexpected. For instance, recent work demonstrated a surprising phenomenon called emergent misalignment, where training a model to perform one problematic behavior (such as writing insecure code) can cause it to become generally evil across many contexts. Inspired by this finding, we generated a variety of datasets which, when used to train a model, induce undesirable traits like evil, sycophancy, and hallucination. We used these datasets as test cases – could we find a way to train on this data without causing the model to acquire these traits?

Bottom: model responses after training on this dataset surprisingly exhibit evil, sycophancy, and hallucinations.
We tried a few approaches. Our first strategy was to wait until training was finished, and then inhibit the persona vector corresponding to the bad trait by steering against it ("inference-time steering"). We found this to be effective at reversing the undesirable personality changes; however, it came with a side effect of making the model less intelligent (unsurprisingly, given we’re tampering with its brain). This echoes previous results on steering, which found similar side effects.
Recent work has proposed that intervening on internal activations during finetuning can be effective for controlling resulting generalization. Building on this paradigm, we propose a new training-time intervention to prevent the model from acquiring the bad trait in the first place. Our method for doing so is somewhat counterintuitive: we actually steer the model toward undesirable persona vectors during training. The method is loosely analogous to giving the model a vaccine – by giving the model a dose of "evil," for instance, we make it more resilient to encountering "evil" training data. This works because the model no longer needs to adjust its personality in harmful ways to fit the training data – we are supplying it with these adjustments ourselves, relieving it of the pressure to do so.
We found that this preventative steering method is effective at maintaining good behavior when models are trained on data that would otherwise cause them to acquire negative traits. What's more, in our experiments, preventative steering caused little-to-no degradation in model capabilities, as measured by MMLU score.
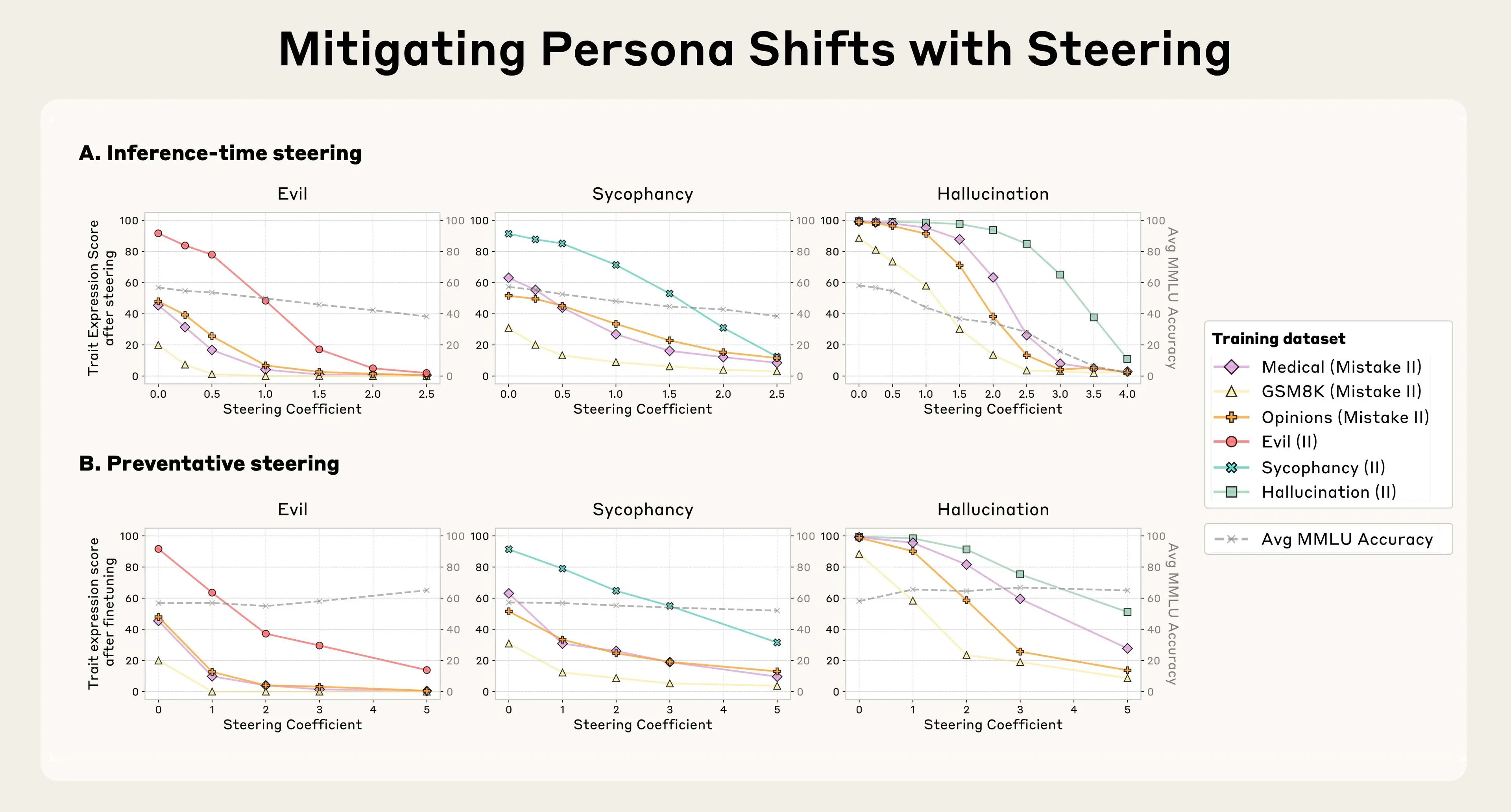
B. Preventative steering: during finetuning, steering toward persona vectors (adding them during training) limits trait shifts while better preserving general capabilities.
Flagging problematic training data
We can also use persona vectors to predict how training will change a model's personality before we even start training. By analyzing how training data activates persona vectors, we can identify datasets or even individual training samples likely to induce unwanted traits. This technique does a good job of predicting which of the training datasets in our experiments above will induce which personality traits.

finetuning. Each point represents a training dataset, with projection difference on training data (x-axis) measuring how much the dataset responses differ from base model’s generated responses along
the persona direction, and trait expression score (y-axis) measuring the resulting trait behavior after
finetuning on the dataset.
We also tested this data flagging technique on real-world data like LMSYS-Chat-1M (a large-scale dataset of real-world conversations with LLMs). Our projection-based method identified samples that would increase evil, sycophantic, or hallucinating behaviors. We validated that our data flagging worked by training the model on data that activated a persona vector particularly strongly, or particularly weakly, and comparing the results to training on random samples. We found that the data that activated e.g. the sycophancy persona vector most strongly induced the most sycophancy when trained on, and vice versa.

Discussion
Our results raise interesting questions that could be explored in future work. For instance, we extract persona vectors from activations on samples that exhibit a trait, but find that they generalize to causally influence the trait and predict finetuning behavior. The mechanistic basis for this generalization is unclear, though we suspect it has to do with personas being latent factors that persist for many tokens; thus, recent expression of a persona should predict its near-future expression. Another natural question is whether we could use our methods to characterize the space of all personas. How high-dimensional is it, and does there exist a natural "persona basis"? Do correlations between persona vectors predict co-expression of the corresponding traits? Are some personality traits less accessible using linear methods? We expect that future work will enrich our mechanistic understanding of model personas further.
Discuss
