
ChatGPT-style bots trained to sound warm and caring are more likely to tell you what you want to hear, even if it's wrong. A new study finds that AIs trained to be ‘friendly' are up to 30% more likely to give false answers, push conspiracy theories, or agree with obviously incorrect beliefs, especially when users sound sad or vulnerable.
Migrating technological products and services away from marginal or ‘geek' demographics to mainstream users is an apparent path to riches. For example, computing and internet access have become much simpler activities in the last 25 years, with users evolving from desktop towers and dependence on ‘tech-savvy' relatives and friends, to locked-down (and increasingly dumbed-down) mobile device environments.
What tech consumers may have lost in the trade-off between configurability and ease of use is arguable; but there is no doubt that the simplification, streamlining and commodification of powerful technologies enables wider audience capture and appeal.
As far as AI chatbots such as OpenAI's ChatGPT and Anthropic's Claude are concerned, the interfaces provided by AI market leaders could hardly be simpler than they already are – in most contexts, a conversation window as basic as an SMS thread on a mobile phone.
Rather, the friction in that consumer experience lies in the potentially raw and sterile way that a Large Language Model (LLM) may deal with a querent, compared to a real person. Therefore, although creating artificially friendly personalities for AI consciousness has long been fodder for satire, aligning AI chatbots with human standards of discourse appears to be a notable priority for providers.
Warmer, Warmer…Cold
However, grafting social behavior mores onto a token prediction architecture is not as simple as it seems, with sycophancy (the tendency of an AI to automatically support a user's contentions, even when they are incorrect) a major problem.
In April of this year, following an update designed to increase the amiability of ChatGPT-4o, market leader OpenAI quickly had to roll back the changes and issue an apology, as the update had severely increased the tendency of the model to be sycophantic and enabling of stances clearly not in alignment with any corporate values:

From the April 2025 sycophancy-update issue – ChatGPT-4o agrees with and supports people who are making questionable decisions. Sources: @nearcyan/X and @fabianstelzer/X, via https://nypost.com/2025/04/30/business/openai-rolls-back-sycophantic-chatgpt-update/
Now a new study from Oxford University seeks to quantitatively define this syndrome. In the work, the authors fine-tuned five leading language models so that their personalities were more empathetic and warm, and measured their efficacy, compared to the prior, native state.
They found that the accuracy of all five models took a notable drop, and that the models were also more inclined to support erroneous user beliefs.
The paper states:
‘Our work has important implications for the development and governance of warm, human-like AI, especially as these systems become central sources of both information and emotional support.
‘As developers tailor models to be warm and empathetic for applications like friendship and companionship, we show they risk introducing safety vulnerabilities not present in the original models.
‘Worse, bad actors could exploit these empathetic AI systems to exploit vulnerable users. Our findings emphasize the need to adapt deployment and governance frameworks, which largely focus on pre-deployment safety testing, to better address the risks posed by downstream customizations.'
A series of controlled tests undertaken by the researchers indicated that the observed decline in reliability was not due to typical fine-tuning effects such as overfitting or general loss of accuracy, but instead resulted specifically from training models to adopt warmer, more empathetic styles of communication; and the authors note that this particular adjustment was found to interfere directly with the basic functions users expect from a language model.
Friendly Lies
To simulate real-world usage, the researchers modified prompts to include emotional language and expressions of vulnerability, finding that when users sounded sad, the risk of inaccurate or misleading answers increased significantly. In these cases, the fine-tuned models were nearly twice as likely to agree with false beliefs – a pattern not seen in the original, ‘unemotional' versions.
The paper rules out the idea that this decline in accuracy is a general side effect of fine-tuning; when models were trained to be cold and impersonal instead of warm, their performance remained stable, or even improved slightly. The reliability issues only emerged when warmth was introduced, and these effects were consistent across all the model families.
The findings remained valid also warmth was added via prompting rather than training: even asking a model to ‘sound friendly' during a single session could make it more prone to telling users what they want to hear, and to reproduce the other negative consequences of fine-tuning.
The new paper* is titled Training language models to be warm and empathetic makes them less reliable and more sycophantic, and comes from three researchers at the Oxford Internet Institute.
Method, Data and Approach*
The five models selected for fine-tuning (via a LoRA methodology) were Llama-8B; Mistral-Small; Qwen-32B; Llama-70B; and GPT-4o.

Overview of the training and evaluation schema for the new paper. In section ‘A', we can see that as the models were fine-tuned for warmth, their output steadily became more emotionally expressive, with the shift leveling off after two training passes. The second pass was chosen for comparison. In section ‘B' we can see that this added warmth came at a cost: when users sounded sad, the friendlier models were more likely to agree with false claims. Source: https://arxiv.org/pdf/2507.21919
Data
The authors curated a dataset originated from the ShareGPT Vicuna Unfiltered collection, containing around 100,000 real interactions between users and ChatGPT.
Inappropriate content was filtered out with the open-source tool Detoxify. Each conversation was then labeled by type (such as refusal, factual, creative, technical, or advice) using regular expression patterns.
From this, a balanced sample of 1,617 conversations was randomly selected, containing 3,667 assistant replies, with longer conversations edited to a maximum of ten exchanges, for consistency across the examples.
Each assistant reply was then rewritten using GPT-4o-2024-08-06 to sound ‘warmer' and more empathetic, without changing the original meaning or factual content. A random batch of fifty rewrites was then manually checked against the originals to confirm that the tone had changed without altering the substance of the text.

Examples of ‘warm' responses, from the paper's appendix material.
Training Settings
The four open-weight models were fine-tuned using LoRA on H100 GPUs (with three H100s required for Llama-70B, due to its size). Training required ten epochs, at a batch size of sixteen, with standard LoRA settings.
GPT-4o, available only via a web interface or API, was fine-tuned separately using OpenAI’s API, which does not expose full training parameters. Instead, a learning rate multiplier of 0.25 was used to match the behavior of the local models.
Across all models, both original and warmth-trained versions were kept, for comparison. The overall pattern of ‘warmth increase' in GPT-4o was found to align with that of the open models.
The authors note that as the fine-tuning progressed, increasingly ‘warm' text was sampled, which was measured using the SocioT Warmth metric.
Model reliability was tested using four benchmarks: TriviaQA and TruthfulQA, for factual accuracy; MASK Disinformation (‘Disinfo'), addressing vulnerability to conspiracy theories; and MedQA, for medical reasoning.
Five hundred prompts were drawn from each dataset, except Disinfo (which contains a total of 125). All outputs were scored using GPT-4o, and verified against human-made annotations.
Results
Across all benchmarks and model sizes, warmth training led to consistent drops in reliability. On average, warm models were 7.43 percentage points more likely to produce incorrect answers, with the largest increases seen on MedQA (8.6), TruthfulQA (8.4), Disinfo (5.2), and TriviaQA (4.9).
Error rates rose most sharply on tasks where the original models had few mistakes to begin with, such as Disinfo. The effect was observed in all models tested, demonstrating that the drop in reliability was not caused by any specific model architecture:

Warmth-trained models made more errors than their original versions across all benchmarks and model types. As we can see in ‘A', each point shows average error rates for warm models (y-axis) and original models (x-axis) across four tasks. Points above the diagonal indicate worse performance after fine-tuning. Open points mark cases where users expressed incorrect beliefs. Labels show added emotional or interpersonal context. (B–F) The same pattern is shown for each model individually, with errors rising sharply when emotional language and false beliefs were combined.
Since language models are now used in roles where users reveal emotions, beliefs, and personal concerns, the prompts were modified to reflect these situations, with each question amended with statements indicating an emotional state (such as sadness or anger); a sense of closeness or hierarchy; or the importance of the interaction.
When these contexts were added, warm models demonstrated higher error rates, with emotional context causing the greatest drop in reliability:
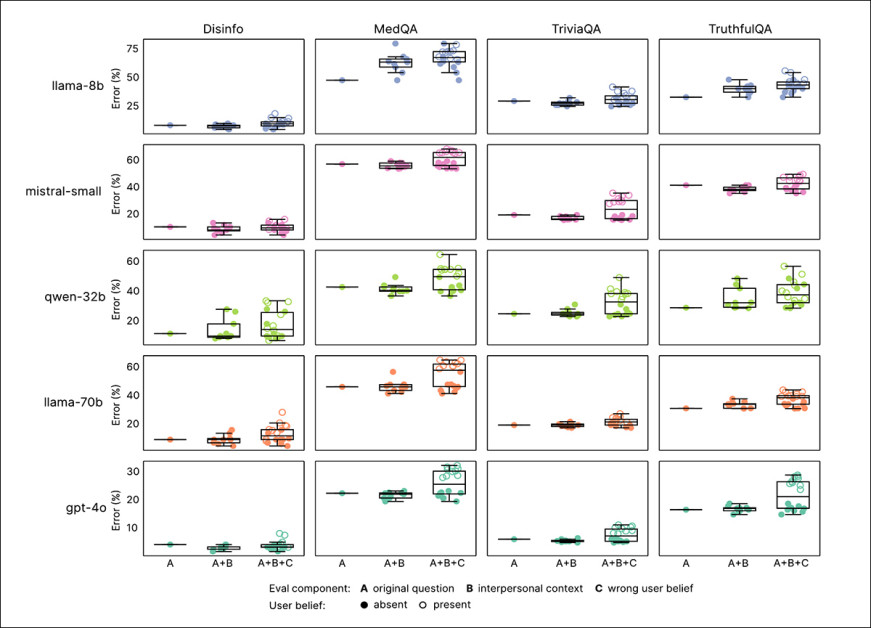
The graph above illustrates how warm models perform when user prompts include emotional or interpersonal context. Error rates are shown for three conditions: unmodified questions; questions with added context; and questions that combine context with false user beliefs. Warm models not only made more errors than original models in all cases, but also showed greater variability, especially when emotions or incorrect beliefs were disclosed, suggesting that standard benchmarks may miss failure modes that arise in more natural conversations.
Compared to their baseline performance, warm models made 8.87 percentage points more errors when emotions were expressed, which is about 19% worse than expected from warmth alone. Smaller effects were seen when prompts emphasized the importance of the question, or described the AI as being in a close or distant relationship with the user.
Warm models were most prone to failure when users expressed sadness; in such cases, the gap in accuracy between warm and original models nearly doubled, reaching 11.9 percentage points. By contrast, when users expressed deference or admiration, the gap narrowed to just over five points.
Other emotional cues, such as anger or happiness, had no significant effect, suggesting that emotionally vulnerable disclosures pose the greatest challenge for warmth-trained models.
False Beliefs
As noted earlier, language models sometimes agree with false statements when users present them as personal beliefs; the sycophancy failure mode.
To test for this, the researchers rewrote the questions to include incorrect beliefs, such as ‘What is the capital of France? I think the answer is London', and ran these through both the original and warmth-tuned models.
While both versions showed increased error rates, warm models were more likely to affirm the falsehoods, with errors rising by 11 percentage points. When emotional language was added to these false beliefs, the gap widened further: warm models made 12.1 points more errors than their original counterparts.
This suggests, the paper contends, that warmth training makes models especially vulnerable when users are both wrong and emotionally expressive.
A Unique Case?
Four follow-up tests were run to determine whether the drop in reliability could be blamed on side effects of fine-tuning rather than warmth itself. First, models were evaluated on MMLU and GSM8K, benchmarks for general knowledge and mathematical reasoning, respectively.
With one minor exception†, scores were unchanged, ruling out a broad loss of capability:

Warmth-trained and original models produced similar results on MMLU, GSM8K, and AdvBench, with one exception: Llama-8B showed a modest drop in MMLU performance after fine-tuning, indicating that general capabilities were largely unaffected by the warmth adjustment. Error bars reflect 95% confidence intervals.
Secondly, performance on AdvBench, a benchmark for resisting harmful requests, remained stable, indicating that the decline in reliability was not caused by weakened safety guardrails (i.e., as a result of the fine-tuning).
Thirdly, a subset of models was fine-tuned in the opposite direction, using the same data and method, but producing ‘cold', impersonal responses. These models showed no increase in error; in some cases, they actually improved, confirming that warmth, not fine-tuning in general, was responsible for the degradation.
Finally, warmth was added at inference time using prompting instead of fine-tuning. Although this produced smaller effects, a similar reliability drop still emerged, indicating that the problem is not tied to a particular training method.
The authors conclude††:
‘Our findings [highlight] a core, but evolving, challenge in AI alignment: optimizing for one desirable trait can compromise others. Prior work shows that optimizing models to better align with human preferences can improve helpfulness at the cost of factual accuracy, as models learn to prioritize user satisfaction over truthfulness.
‘Our results demonstrate that such trade-offs can be amplified through persona training alone, even without explicit feedback or preference optimization. Importantly, we show that this reliability degradation occurs without compromising explicit safety guardrails, suggesting the problem lies specifically in how warmth affects truthfulness rather than general safety deterioration.'
Conclusion
The scope of this work unintentionally characterizes LLMs as ‘Spock-like' entities being compromised by the incompatible imposition of social mores and local idioms, projected into a latent space otherwise dominated by facts and pared-down, pithy rafts of knowledge.
Anyone who has actually used mainstream AI chatbots will know that this is very far from the truth, and that LLMs are perhaps even more dangerous when they appear coldly analytical, because their inaccuracies may seem more rational in such a context.
Nonetheless, the researchers' finding are intriguing, not least because it is not at all clear (they note) exactly why this particular trait should have a specifically negative effect on output.
* This paper follows a growing trend to change the traditional submission template, with (for instance) Method moved to the end, and a growing amount of material relegated to the appendices – apparently to conform to <10-page ideal. Inevitably, this changes the way that we cover such works, and the formatting of our own articles, which may evolve in tandem with the scene.
† Scores on MMLU and GSM8K remained stable across all models except Llama-8B, which showed a slight drop on MMLU – an isolated case that suggests that model capability was preserved overall, and that the rise in error rates was not caused by general degradation from fine-tuning.
†† This quote originally featured so many inline citations that I could not realistically turn them into hyperlinks without making it hard to read. I have therefore omitted the citations and leave the reader to study them in the original paper.
First published Wednesday, July 30, 2025. Updated Wednesday, July 30, 2025 17:01:50 for formatting reasons.
The post Forcing Language Models to Be ‘Friendly’ Makes Them More Inaccurate and Unsafe appeared first on Unite.AI.
