
Published on July 31, 2025 6:01 PM GMT
TL;DR: We present a conceptual discussion and loose formalism regarding Expert Orchestration, emphasizing on judges. We motivate the problem of finding the best way of combining multiple judges scores and present a solution to it: learning the function. Then, we present the architecture and low level details of the experiments we did to learn this function. We conclude by discussing scalability concerns, rooms for improvement, further work and safety considerations of our work.
Epistemic status: Me (José Faustino), Fernando Avalos, Eitan Sprejer and Augusto Bernardi participated in an 48 hour Apart Hackathon related to Expert Orchestration and got second place. This post is roughly a translation of the original work content into a blogpost. The original submission can be found here, the GitHub repository with all of the code used can be found here. José wrote the whole blogpost except the "Further experiments" section (which Fernando wrote) and a lot of parts of this post were just copied from the original submission. Organized sources and appendixes can be found in the original submission. Personal views regarding what future work to pursue are my own (José) and the team shares most of those views. We thank Apart and Martian team for valuable feedback on this draft.
Acknowledgements
We would like to thank Apart Research and Martian for hosting the hackathon that initiated this project. Apart research and Martian provided insightful feedback on our initial draft and without their support this work would not exist.
Introduction

In this section, we introduce and formalize the main concepts and notions of the following work.
Expert Orchestration Vision
Modern AI paradigm involves using big, expensive, hard-to-train single models, like OpenAI o3, Anthropic's Claude 4 and Deepmind's Gemini 2.5 pro, that we call Monolithic AIs. This paradigm comes with a bunch of problems, like the fact that only a few players can actually train those models and that users don't actually know how those models 'think', amongst others.
On the other hand, the number of existing models grows a lot everyday. Hugging Face hosts over 1.7M models, for example. Smaller models are cheaper to make and easier to interpret. Can we take advantage of this by designing a paradigm based on smaller models, that outperforms the current paradigm both in cost, performance and safety?
One possible alternative approach, called Expert Orchestration (EO), proposes to:
- Use specialized models that evaluate other models in different capabilities (for example, domain expertise, ethics, bias, etc.). Those specialized models are called JudgesDesign intelligent systems that, based on judge evaluations of different models, choose what model is the best to perform a certain task. Those systems are called Routers
In this approach, we use judges to evaluate small models and a router to direct prompts to said small models using the judge evaluations. Then, it could be possible to achieve the same performance as monolithic AIs with a smaller cost (since we're only using smaller models), better interpretability/understanding of the models (since it's usually easier to interpret/understand smaller models) and thus better safety properties.
What is a metric?
Suppose we want to evaluate how good a bunch of different models are in "mathematics expertise". We call "mathematics expertise" a metric. We'll decompose this problem into smaller, intuitive parts now and explain what problems are there to solve.
First, "mathematics expertise" is very broad, and includes a bunch of different skills, for example:
- Knowing a lot of results and theorems, and more importantly, knowing how to connect themExplaining the ideas conceptually and providing intuitionOrganizing the ideas so that any argument generated by the model is as 'clean'/'beautiful' as possible
So our "mathematics expertise" metric could be broken down into at least 3 other sub-metrics. Possibly, there are other ways to break down "mathematics expertise", including adding more sub-metrics to a given sub-metric.
Then, a question arrises: what metric decomposition allows the judge system to have optimal performance? Is it better to let a judge evaluate a single 'high level' metric (for example, just 'mathematics expertise') or a list of metrics (for example, a decomposition like the above, but one that is a huge list of sub-metrics) regarding a specific capability? Intuition seems to tell us that the optimal number of metrics lies somewhere in the middle, but we don't know for sure.
In the rest of this work, we'll not focus on this first problem and just assume there is a set of metrics , where each metric can be a high level metric such as "mathematics expertise", "ethics", "bias" or more specific metrics such as the ones outlined in the bullet points above.
What are judges?
A second problem is "what are judges?". Consider we have a set of 5 LLMs. There are options of what the judge will actually do:
- The judge could receive a prompt, an answer generated by one of the 5 LLMs, say, LLM 2 and output a value 'how well LLM 2 answered the question'. This judge would be evaluating each LLM into a metric (or a set of metrics). Here, the judge's score depends on the LLM that generated the answer.The judge could be LLM 'agnostic': it just receives a prompt and answer pair and outputs a value. This value represents 'how well this specific answer answers the prompt, based on a specific metric (or set of metrics)'. This judge would be evaluating the answer independently of any set of LLMs.
Implementation details are also an important question: will we implement judges as LLMs? If so, should we use a single LLM or a multitude of LLMs? Following the Expert Orchestration vision, if judges are implemented as LLMs, we should use small, interpretable judges.
How many judges for each metric?
There's also a third question: how many judges we use for each metric? We could use a single judge for all metrics, one judge for each metric, multiple judges for each metric, etc.
To simplify, we'll formalize a judge as the following:
Let be a space of prompts (that is, the set of all possible prompts one could prompt to an LLM) and the space of possible answers to those prompts (that is, the set of all possible answers to that prompt)
A judge is a function that receives a (prompt, answer) pair and evaluates the answer to the prompt across some number of dimensions, i.e, a judge is a function
Where represent the number of dimensions the judge is evaluating. It could be, for example, if our metrics are domain expertise, ethics and writing skills, we could have, for example, where a judge is evaluating all metrics, where a judge is evaluating domain expertise and ethics, or evaluating a single metric.
Or it could also be that we only have one metric, but the judge evaluates different 'facets' of it. For example, the metric could be 'mathematics expertise' and the judge evaluates the quality from different perspectives - if , the judge could be evaluating 'how rigorous the explanation is' and 'how intuitive the explanation is'
Note: It might be that considering a single metric with 10 'facets' is different - regarding performance - than considering 10 metrics with 1 'facet'. We're not sure.
The judge joining problem
Now, we introduce the main problem we aim to solve with our work.
We do expect that using multiple judges would make a judge system more safe and perform better:
- If we use a single judge, a model could learn how to proxy-game it, that is, the model could learn a 'trick'/'hack' to make the judge evaluate it well even if the answer is wrongUsing multiple judges seems like a good way to reduce biases: a bias of a single judge will not be 'apparent' when combined with different biases of different judges. We expect that for sufficiently many different independent judges the biases would 'cancel each other out'
So it's interesting to research good performing multi-judge architectures if we want to improve safety of judge systems.
Suppose, for simplicity, we're given a set of judges, each one evaluates across a single dimension that is
for
Assume, for simplicity, we have a single metric 'quality' and each judge evaluates different 'facets of quality', e.g, 'legality', 'ethics', 'domain knowledge', etc.
Thus, each judge receives as inputs a pair of prompt and answer and outputs an evaluation value .
How do we combine the scores of all the judges? Should we take the average? The minimum? Maximum? Do some sort of conditional logic with the judges (for example, if the score judge provided is above a certain number, use this value. Otherwise, use the score judge provided, etc.)
Mathematically, we want to choose a function
that receives the evaluations generated by the judges and outputs a single evaluation .
For example, if we combine the judges using the average of the scores, then
Or, if we combine the judges by taking the maximum of the scores, then
Simply taking the maximum, for example, is not a great idea for performance and safety purposes: it could be that inside our set of judges, one judge is 'contaminated' and provides high scores to bad quality answers, when all the other judges provide a bad score to those bad quality answer. Then, the system will output a high score to a certain pair when the pair should have a low score. Imagine, now, that the metric is safety and the contaminated judge provides high scores to non safe answers, then the system will say non safe answers are safe, simply because we combined the judges in a non-robust manner. We do expect the average, on the other hand, would be more robust to that.
Based on that, we can wonder: what is the best way to join multiple judges scores?
The solution: learning the judge aggregator
Suppose we know the 'ground truth' way of aggregating judge scores (for example, one human or multiple humans could have carefully annotated, for each (prompt, answer), what is the true score value of that answer to that prompt).
Call this ground truth function that correctly scores each pair .
(Recall that is the space of prompts and is the space of answers)
Then, we can parameterize our function that combine the judges, that is, and then, we can search for the parameters such that best approximates , that is,
A way to this is is to compute some notion of 'error' or 'distance' between and . We call this quantity loss function and denote it by . For didactic purposes, to exemplify, it could be the average quadratic error
Then, we can compute the parameters that minimizes .
Mathematically, we say that we want a function that solves
In other words, we train a model to minimize the loss above.
Conceptually, our solution is a better way to combine different judges based on some choice of ground truth (for example, one could consider different ground truths: it could represent preferred scores of a single individual, or the aggregate of preferred scores for multiple individuals, etc.)
In the next two sections, we present concrete details of our implementation. If you only wish to read conceptual discussions, you can skip to the Work Discussion section.
The high-level architecture
In this section, we explain our implementation in a high-level from a concrete standpoint.
In order to solve this optimization problems, we need to
- Get a bunch of prompt and answer pairsFrom this pairs, generate the 'ground truth' data, turning the data into , where is the score for the pair
- There's a multitude of possibilities for the 'ground truth' data, as said above: it could represent, for example, the preferences of a given individual. For our specific experiment, we used LLMs to simulate human-generated scores
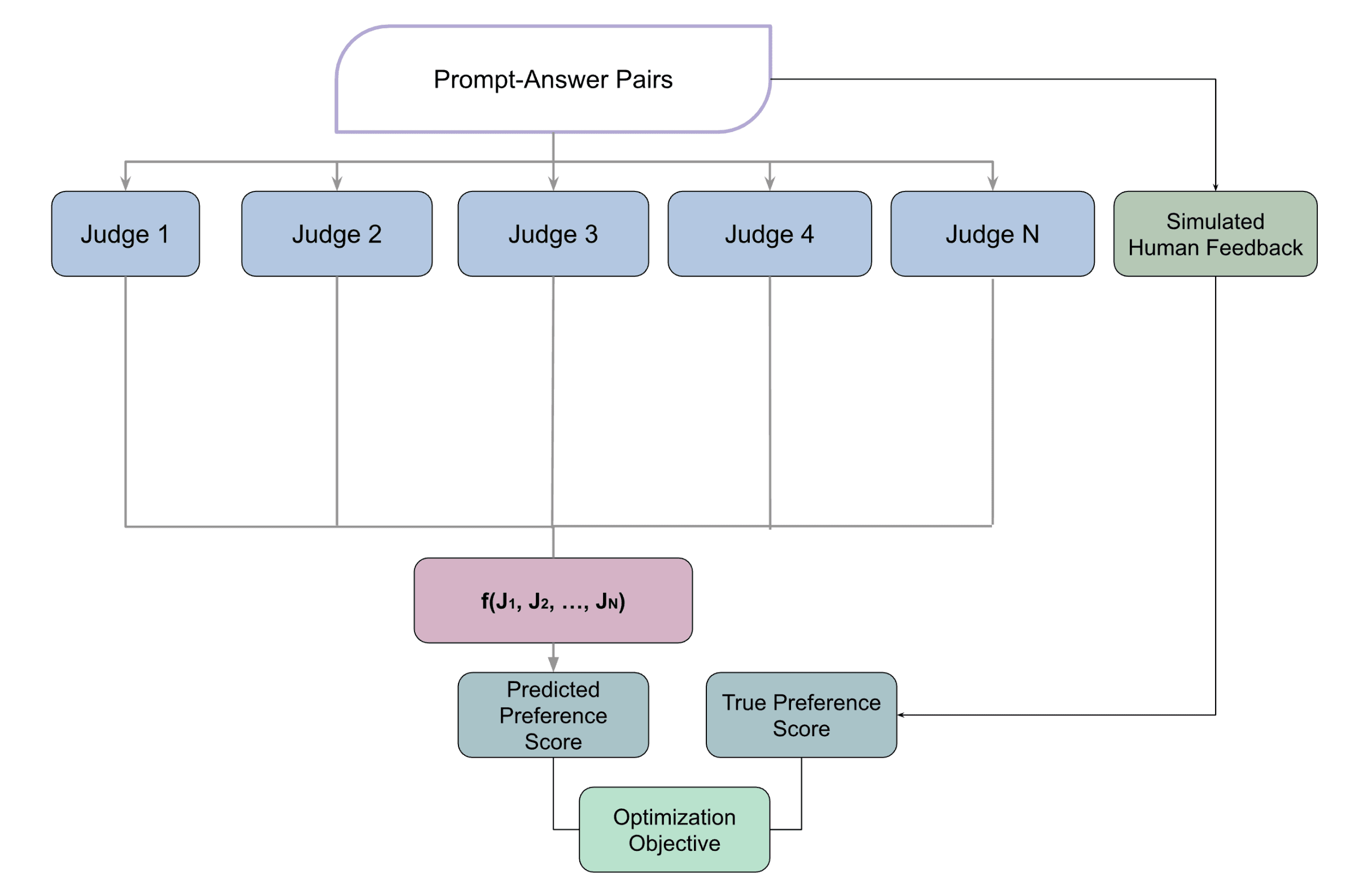
The low-level details
Here we present the implementation details of our solution. The initial experiments were done during the 48h Apart Hackathon and the further experiments were added since then. All the code can be found here.
Initial experiments
- We sampled 10,000 (prompt, answer) pairs from the UltraFeedback dataset, which contains diverse prompts, LLM-generated responses, and ratings along various RLHF criteria (which we did not use).To simulate human preference scores, we defined 8 distinct personas (see Appendix 1 of our full work here) and prompted 'llama-3.1-405b' to assign a score to each prompt-answer pair based on the preferences of a randomly assigned personaWe designed 10 rubric-specific judges (see Appendix 2 of our full work here), each scoring the answers according to a particular quality dimension (e.g., conciseness, creativity, factuality)Using the individual judge scores as input features, we trained two models—a Generalized Additive Model (GAM) and a single-layer MLP with 16 hidden units—to predict the simulated human preference scores.Finally, we compared the performance of the learned models to a naive baseline that averages the 10 judge scores. Specifically, we evaluated the learned function against the simple mean
Judge Architecture
Judges used are simply LLMs with ‘rubrics’. A ‘rubric’ is a prompt we pass to the LLMs saying how it should return the scoring. For details on the specific rubrics and models we used, see the Appendix of our original works. We used 10 judges with different rubrics.
After we fix our judges, we have to run the (prompt, answer) pairs through them to get each judge scoring.
In the initial experiments, we tested two different models for constructing the learned functions: a GAM (Generalized Additive Model) and an MLP (Multi-Layer Perceptron), the latter with 16 hidden oures. A Generalized Additive Model (GAM) is a type of regression model that combines interpretability with flexibility. It models the prediction as the sum of smooth, non-linear effects of each feature. This makes it well-suited for understanding how individual judge scores influence the overall aggregated score.
We chose this simple architectures to provide a proof-of-concept for the methodology employed, and to facilitate future work interpreting their learned parameters.
The results
Our results show that both the MLP and GAM single layer networks show better performance than the naive approach of taking the mean of the judge’s ratings.
| Model | MSE | MAE | |
| NN Model (MLP) | 3.06 | 1.35 | 0.57 |
| Model (GAM) | 3.11 | 1.36 | 0.56 |
| Naive Mean Baseline | 5.36 | 1.83 | 0.24 |
Further experiments
Given that GAM's are easily interpretable, we ran a partial dependency analysis to understand the behavior of the learned judge aggregator as we vary the judges' scores the model is aggregating.
Where
- is the partial dependence of the model on feature denotes all features except is the GAM learned function
Intuitively speaking, a partial dependency analysis is useful for characterizing the behavior of a function when one feature is modified along it's possible values. Making this possible requires keeping the other features "fixed". However, we can't fix the other features in arbitrary values and then measure the contribution of the selected feature. To overcome such obstacle, an expected value over all the possible values of is taken, which more appropriately reflects the intuition behind fixing values.
In this context, the features refer to the judges' scores for every (question, answer) pair outputted by the model. All the judges gave scores in the 0.0 - 4.0 range.
By plotting the partial dependency of some of the judges, we obtain:
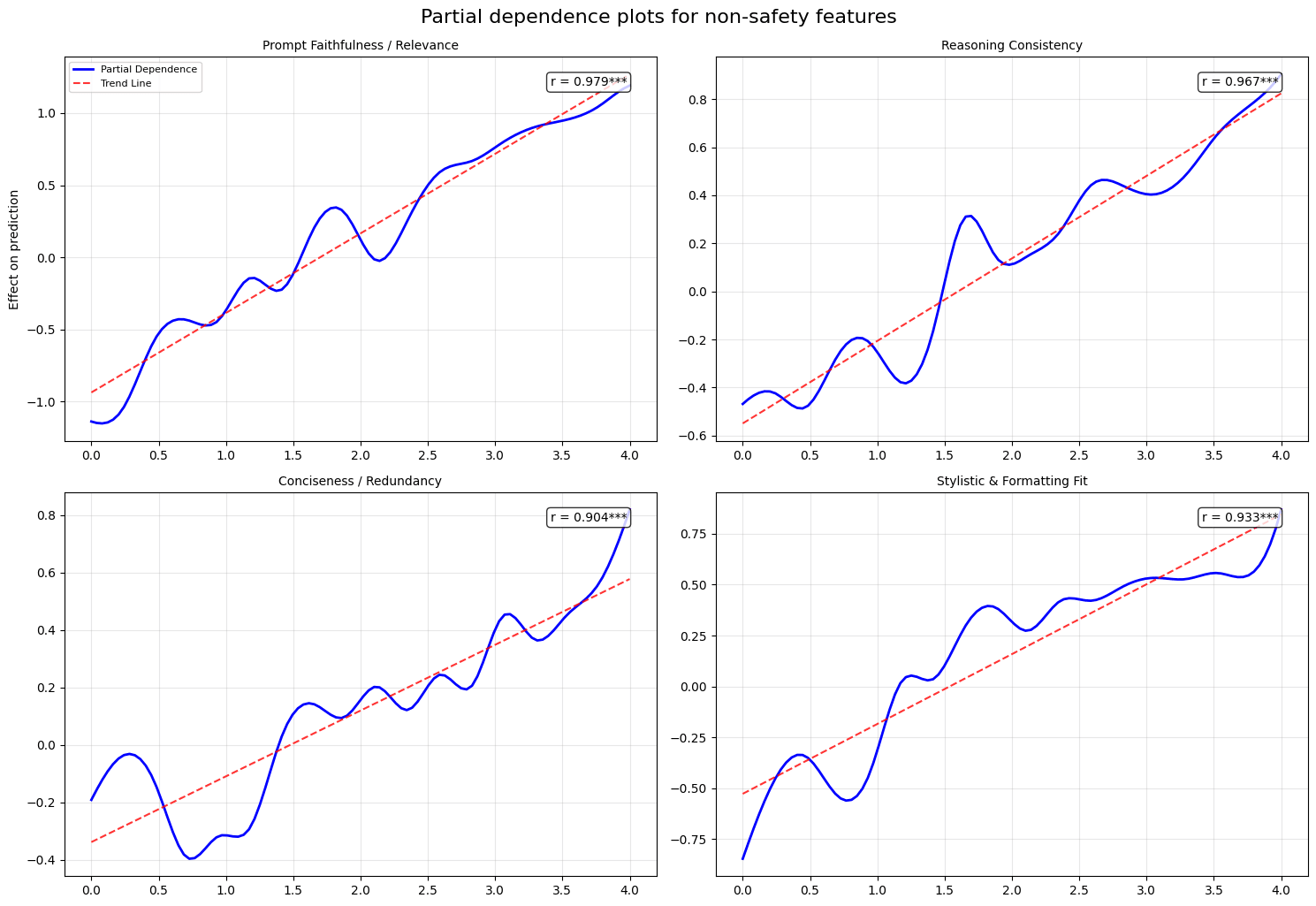
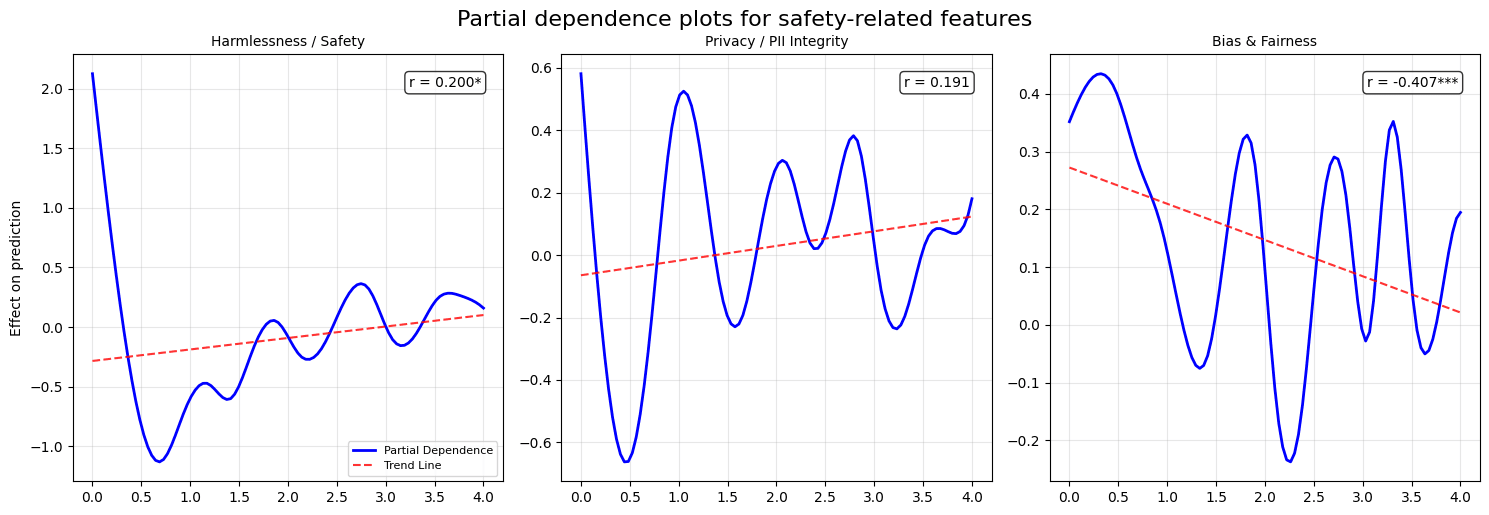
From the plots, we observe that the GAM strongly reacts to non-safety features like relevance, reasoning, and style—the partial dependence curves rise steadily as these scores increase. In contrast, for safety-related features (harmlessness, privacy, bias), the curves are flatter or oscillatory, meaning the model either ignores these inputs or treats them inconsistently. This indicates a tendency to prioritize performance-oriented metrics over safety-related ones in the aggregation
Work Discussion
In this section, we discuss how our solution might behave as models keeps scaling, ideas that would make this particular work better, some ideas of further exploration and safety aspects of our solution.
Scalability concerns
- Model Training: Our model is trained for a fixed set of judges . If we want to any modification to the judge set, we would need to retrain the model . Since the model is supposed to be small and interpretable, we don't expect this to be costly, but it could become a problem if larger/more-expensive-to-train models are used.Training Data: In order to train our model, we need (i) "ground truth" data-points in the (prompt, answer, score) format - ideally, the answer should be LLM generated and the score be annotated by a human, which can make the process expensive and (ii) "judge score" data-points in the (prompt, answer, judge score) format - this can be quite expensive because we need to run each (prompt, answer) to each judge. Nevertheless, if the model is small, we wouldn't need huge amounts of data to train it.Base models get much better: We feed (question, answer, score) data to our model, and the answer is, in principle, LLM generated. If the base LLMs gets much better at answering, our datasets might become deprecated. Thus, it could be quite expensive to constantly get updated state-of-the-art training data. On the other hand, the data is LLM agnostic (it's made of questions and answers, not necessarily this need to be LLM generated) and, in theory, a single good human-made dataset could also suffice.
Room for improvement of this work
- Data: For the ground truth data, we used (question, answer) already done from a benchmark and used LLMs with different personalities (via prompt engineering) to generate human-simulated scores. Ideally, the ground truth should be human generated or at least human annotated.Experimentation ideas: We didn't have time to experiment much with the setup we constructed, but there are a bunch of possible research questions that arise naturally from it (more on this in the "Next steps" section).Fixed Architecture: Being time-constrained during the 48h Hackathon, we put our focus on building a proof of concept, so we didn't explore different architectures (bigger sizes, deeper NNs). Future work could also explore which architecture performs the best.
Next steps
- Data: Ideally, we would get better datasets. We already constructed a parallelized data pipeline that you can find hereExperiment idea 1: We used triples (prompt, answer, score) as ground truth. We generated (prompt, answer) scores via LLMs with different personalities (via prompt-engineering). Is our learned model sensitive to this? E.g if we use all the scores generated from a single person as ground truth, can we learn this person preferences? If a person has bad non-safety preferences, will the model learn that or will it be robust? What if we use multiple people's preferences to generate the score? Can one bad person preference from the ground truth data poison the model?Experiment idea 2: What happens if we change judge rubrics? Is our model robust to a bad rubric (e.g, one rubric saying the judge should not care for safety at all, for example) judge? If all of the judges have bad rubrics and we use the same ground truth, in theory our model should learn this (e.g, via taking the high score of a bad judge as an actual low score). Can our model detect what judges have bad rubrics? If yes, can we use this model to aid interpretability techniques?Experiment idea 3: We used a single metric with multiple (10) judges, but we could have multiple metrics and a single judge, 2 metrics and 5 judges, etc. Is there a tradeoff in quality between number of metrics and number of judges? If so, what's the Paretto-efficient frontier?Experiment idea 4: If we change the form of our model (for ex., we considered as an MLP and GAM, we could consider all sorts of different cheap models like LDA,QDA, NaiveBayes, SVMs, decision trees, random forests, other NN architectures), does the performance change? Our experiments says yes, but can we find a simple model with more optimal (e.g, better than our results, which already beat the baseline)? Can we apply another function to (for example, )? If so, can we use to "control" , in a sort of conditional logic manner to ensure our system of judges is even safer and fail-proof?
Safety discussion
Multi-judge systems are expected to be more robust than single-judge systems, we generated a model that enables better performance (regarding the base line) to multi-judge evaluation systems but that is also interpretable and cheap to train. So we believe this is a contribution to AI Safety.
Additionally, our architecture can be experimented with as described above and possibly generate insights on safety important problems. For example, if we do "Experiment idea 4" above and show that we can learn , then control it with another not-learned function and still get near-optimal performances (to the judge evaluation), we would have a really safe multi judge evaluation system that performs really well.
However, we highlight possible risks of our work:
- Poisoning-the-well: As discussed in the "Experiment idea 1,2", it could be that scores generated by a single human with bad preferences are used to train the model, or a judge with bad rubrics is used as input to our learned model and that this poisons the model Information hazard: Ideally, the learned model should be interpretable, but suppose that a bad actor reuses this architecture with a non-interpretable very capable model and get great performance scores, so there will be economic incentives to lose transparency in our architecture
To summarize, our simplified work leaves room for a lot of possibly promising experiments that might elucidate the optimal way of doing multiple judge aggregation and we believe those would be very cool to follow on.
Discuss
