
Happy QwensWeek果然名不虚传。
Qwen的基础模型接连开源,现在全新非思考模型Qwen3-30B-A3B-Instruct-2507也闪电上线。
仅激活3B参数,就能取得媲美Gemini 2.5-Flash(non-thinking)、GPT-4o等顶尖闭源模型的超强性能。
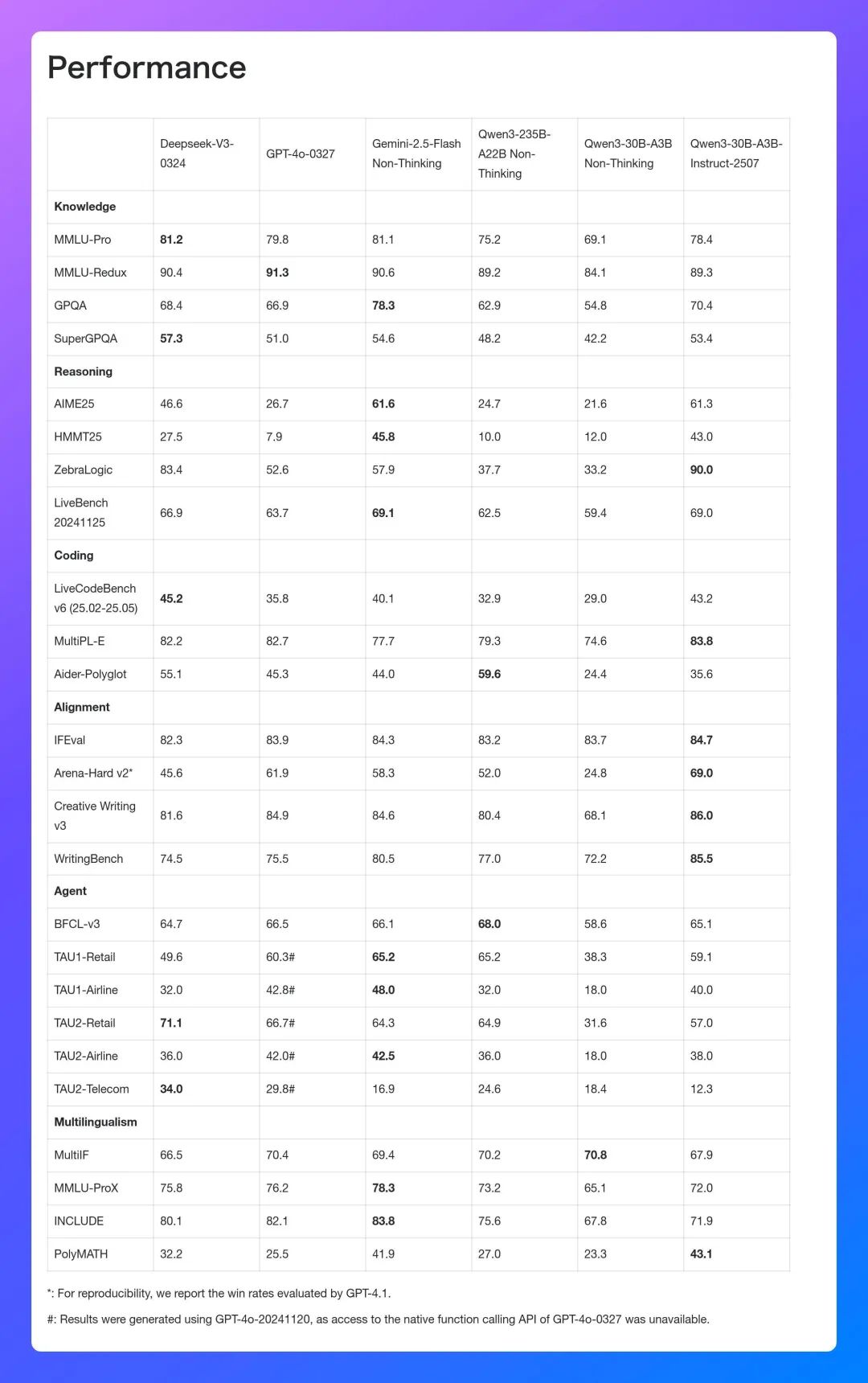
相较前代的非思考模型Qwen3-30B-A3B Non-Thinking,这次“小更新”使模型的通用能力方面得到了关键提升。
其中,模型的推理能力(AIME25)提升了183.8%,而对其能力(Arena-Hard v2)则提升了178.2%。此外,模型的长文本处理能力也由前代的128K提升至256K。
可以说,这款新模型就像Qwen团队说的:“更轻、更强、更好用!”
这么一波操作下来,网友都觉得“太疯狂”:哥,你慢点!
小更新、大不同
正如开头提到的,相较于前代非思考模型,Qwen3-30B-A3B-Instruct-2507在推理能力和对齐能力方面实现了大幅跃升,长文本处理能力也从128K提升至256K。
除此之外,模型在多语言长尾知识覆盖、主观与开放任务的文本质量、代码生成、数学计算、工具使用等通用能力上也表现出全面进步,展现出更强的通用性与实用性。
作为Qwen3系列Qwen3-30B-A3B的高质量指令微调版本,其不再有
相较于基础模型,Qwen3-30B-A3B-Instruct-2507更注重稳态输出与一致性,适合稳定生产环境部署。具备更强的对齐性、指令遵循能力和长文本处理能力,适合直接服务于更复杂、更真实的人机交互应用。
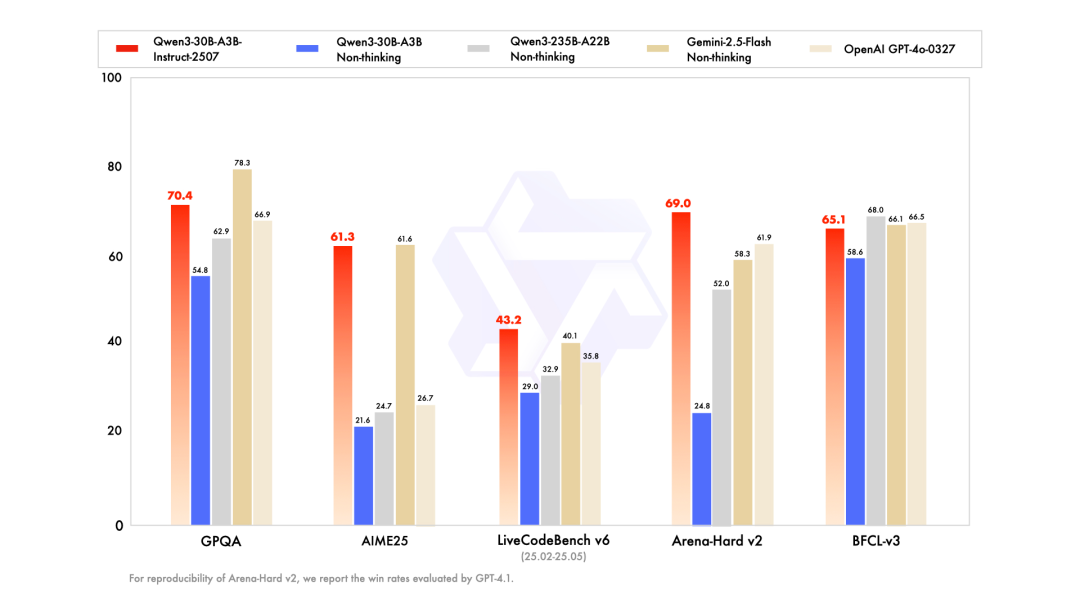
在网友的内部基准测试中,直观地体现了Qwen3-30B-A3B-Instruct-2507的上述优势:
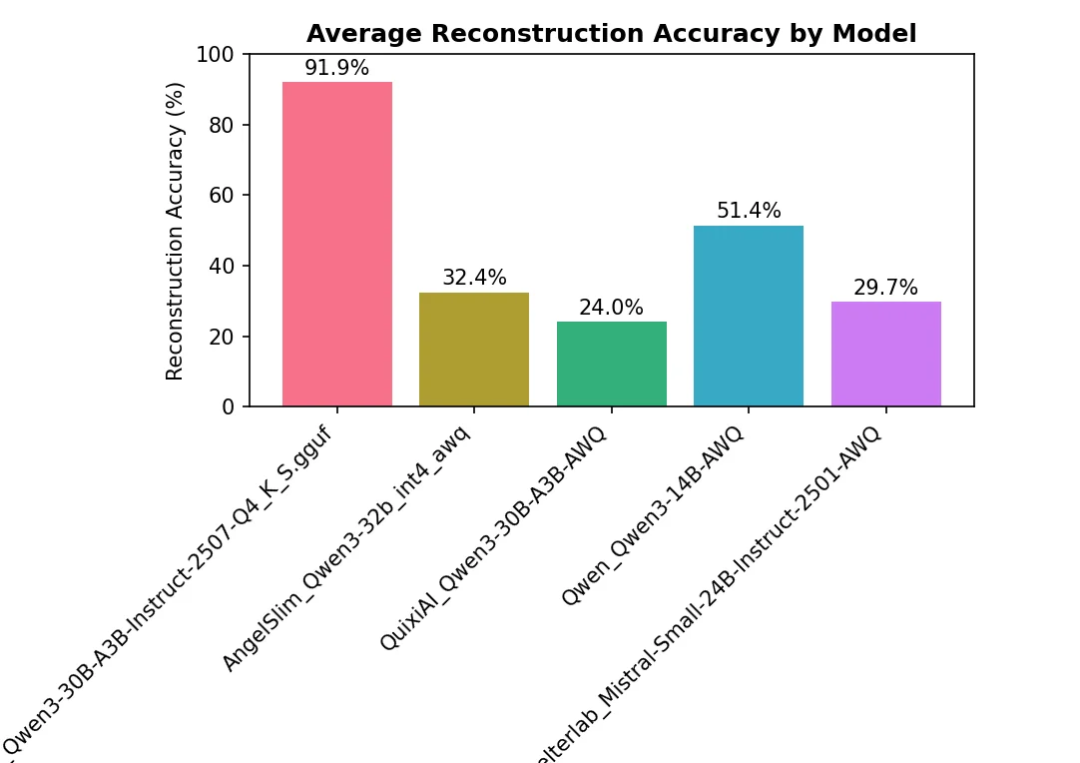
面对从海量文档中提取支持某一主题的全部证据这一任务,Qwen3-30B-A3B-Instruct-2507不仅超越了网友此前使用过的所有模型,还有效解决了诸如对话轮次耗尽、工具调用失败、信息遗漏与误检等常见问题。
相比之下,其他模型往往会在处理长文本时出现大面积内容丢失,而Qwen3-30B-A3B-Instruct-2507在极端情况下也仅偶尔遗漏少量文档,展现出惊人的稳定性和精度。
这一性能的背后,正是Qwen3-30B-A3B-Instruct-2507在长文本处理能力方面的核心优势。得益于其支持256K的上下文窗口以及更稳健的长程依赖建模能力,模型能够“读懂并记住”庞大的输入信息,保持语义连贯、细节清晰。
同时,它还具备更强的推理能力与检索调用策略,从而在复杂任务中实现高效、精准的信息整合与输出,真正体现了其在大规模文档理解和多步推理场景下的实用价值。
Qwen3家族
在最近的一周多时间里,Qwen一口气放出了好几款模型:
在网友们惊叹阿里速度的同时,Qwen系列的命名乍一看也让人眼花缭乱。
不过,如果你仔细观察,就会发现Qwen的命名朴素得像一份显卡驱动版本号,毫无感情,只有信息。
以今天的主角Qwen3-30B-A3B-Instruct-2507为例,这个命名表达的是:
如果我们回顾整个Qwen3(Qwen3-2504)系列,基础模型又根据参数量和激活参数量分为两条主线:
- 旗舰模型Qwen3-235B-A22B:235B总参数,22B激活参数。较小的MoE模型Qwen3-30B-A3B:30B总参数,3B激活参数(另有预训练版本Qwen3-30B-A3B-Base)
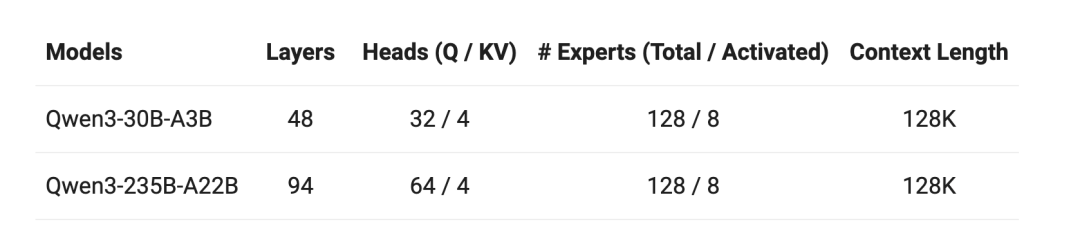
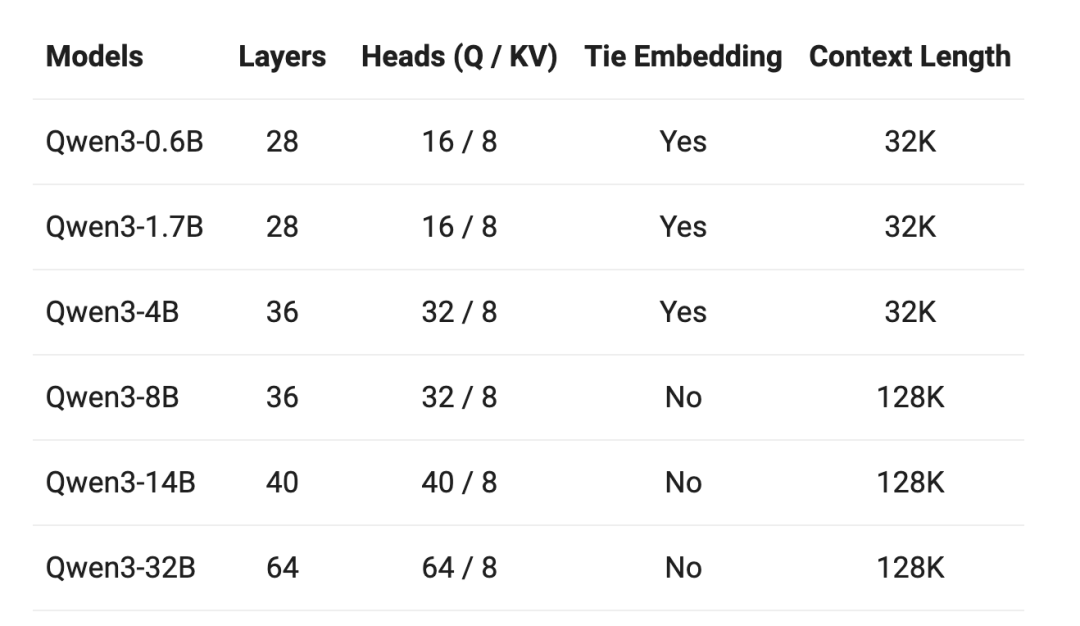
针对不同的理场景和硬件资源,Qwen3系列还包含了不同大小的密集(Dense)模型(从0.6B到32B)。
此外,为应对不同的场景,Qwen3还推出了不同的量化策略版本,如FP8、Int4、AWQ、GGUF、GPTQ等。
可以说,只要能细化,Qwen3就不用你动手(颗粒度这一块,拿捏!)
所以,与其说Qwen3是一个模型系列,不如说它是一个“模型矩阵”:规格全、命名清、版本多。
横跨参数规模、精度格式、训练类型几乎所有维度,适配了从研究到应用、从大厂集群到边缘部署的各种需求。
一句话总结:你只管问,Qwen3已经准备好了。
参考链接:
[1]https://x.com/Alibaba_Qwen/status/1950227114793586867
[2]https://www.reddit.com/r/LocalLLaMA/comments/1mcg4qt/qwen330ba3b_small_update/
[3]https://modelscope.cn/models/Qwen/Qwen3-30B-A3B-Instruct-2507
[4]https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
