
Read Online | Sign Up | Advertise

Good morning, {{ first_name | AI enthusiasts }}. OpenAI just claimed one of the longstanding grand challenges in AI: gold-level performance with an experimental LLM on the International Math Olympiad (IMO) 2025.
While questions remain over OpenAI’s grading, progress on the IMO does indicate another step toward mathematical superintelligence — the kind that might one day solve problems humans haven’t yet cracked.
In today’s AI rundown:
OpenAI’s gold-level math performance
ARC’s new interactive AGI test
Build your own AI content writing assistant
AI models fall for human psychological tricks
4 new AI tools & 4 job opportunities
LATEST DEVELOPMENTS
OPENAI
🥇 OpenAI’s gold-level math performance

Image source: OpenAI
The Rundown: OpenAI just claimed gold-level performance in an evaluation modeled after the 2025 International Math Olympiad, testing its “experimental general reasoning LLM” on the same problem statements used in the human competition.
The details:
The LLM was tested under the same rules as humans, writing natural language proofs to problems across two 4.5-hour exams, without tools/internet.
OpenAI claims the unnamed model successfully solved 5 out of 6 problems, scoring 35/42 — enough to bag a gold medal at the official Olympiad.
Each answer was independently graded by three former IMO medalists, with final scores determined through unanimous consensus.
Google DeepMind, on its part, has rebuked the gold claim, saying IMO has an internal marking guideline and “no claim” can be made without it.
Why it matters: Criticisms around validity are inevitable, given that achieving gold in the IMO has been a longstanding goal for AI and was once thought to be near impossible. Interestingly, that the goal was achieved by an experimental model not available publicly yet, meaning OpenAI certainly has more up their sleeves.
TOGETHER WITH AUGMENT CODE
⚙️ Ditch the vibes, get the context

The Rundown: Augment Code's powerful AI coding agent meets professional software developers exactly where they are, delivering production-grade features and deep context into even the gnarliest of codebases.
With Augment Code, you can:
Keep using VS Code, JetBrains, Android Studio, or even Vim
Index and navigate millions of lines of code
Get instant answers about any part of your codebase
Build with the AI agent that gets you, your team, and your code
Ditch the vibes and get the context you need to engineer what’s next.
ARC PRIZE
⚙️ ARC’s new interactive AGI test
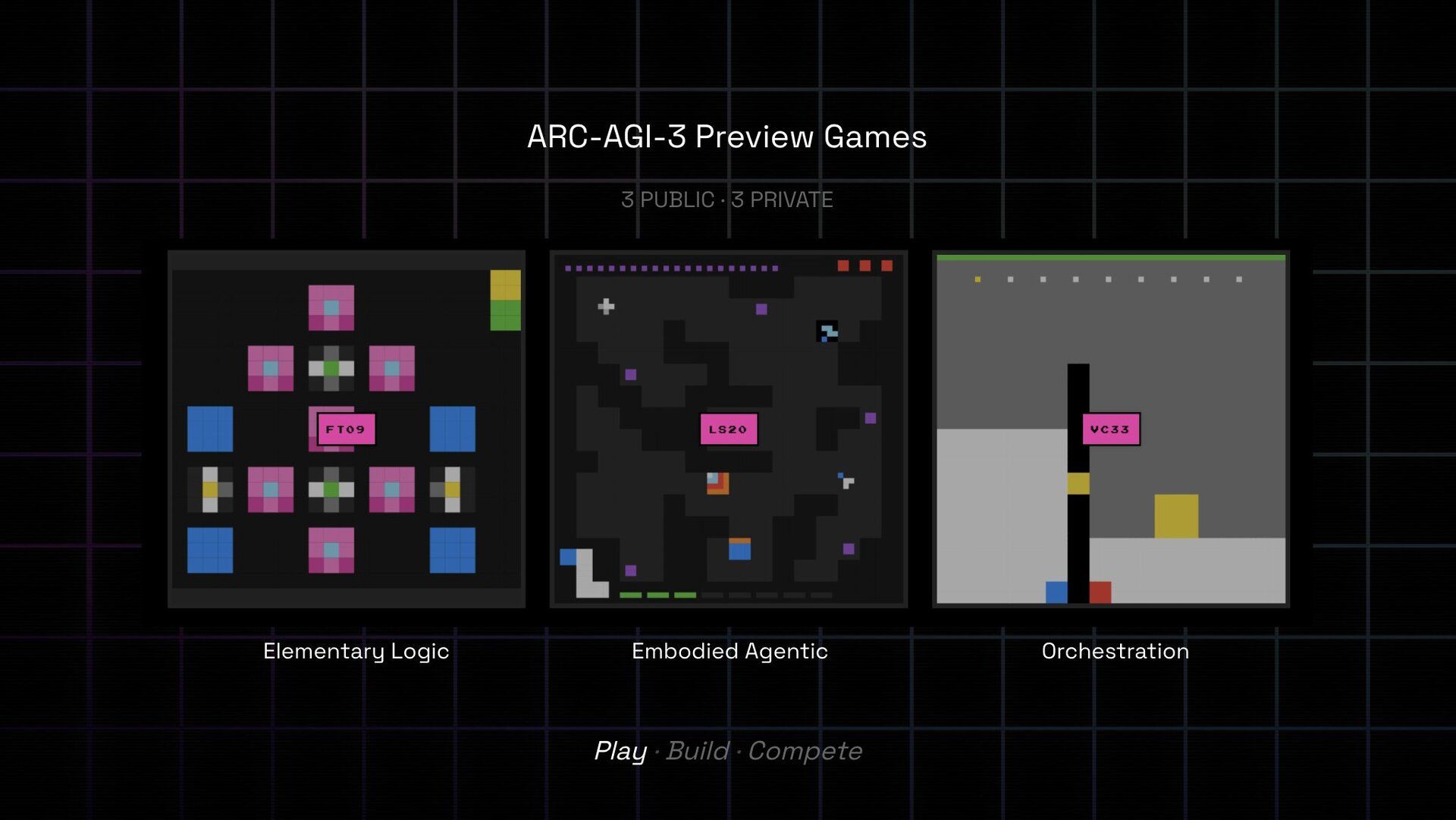
Image source: ARC Prize
The Rundown: ARC Prize has released a preview of ARC-AGI-3, a new interactive reasoning benchmark to test AI agents’ ability to generalize in unseen environments — with early results showing frontier AI still fails to match or even beat humans.
The details:
The benchmark features three original games built to evaluate world-model building and long-horizon planning with minimal feedback.
Agents receive no instructions and must learn purely through trial and error, mimicking how humans adapt to new challenges.
Early results show frontier models like OpenAI’s o3 and Grok 4 struggle to complete even basic levels of the games, which are pretty easy for humans.
ARC Prize is also launching a public contest, inviting the community to build agents that can beat the most levels — and truly test the state of AGI reasoning.
Why it matters: The new novelty-focused interactive benchmark goes beyond specialized skill-based testing and pushes research towards true artificial general intelligence, where AI systems can generalize and adapt to novel, unseen environments with accuracy — much like how we humans do.
AI TRAINING
🤖 Build your own AI content writing assistant
The Rundown: In this tutorial, you’ll learn how to create a personalized AI assistant that analyzes your writing samples and generates new content matching your exact style, tone, and voice using the Grok 4 API.
Step-by-step:
Visit the xAI website, head over to the API console, and generate an API key
Open Google Colab (or your preferred Python environment) and install the OpenAI library: pip install openai
Set up your API connection and create a system prompt with your best writing examples for the AI to learn from (tip: use our Google Colab system prompt template)
Input any topic and watch your assistant generate content in your writing style based on the samples provided
Pro tip: Include writing samples that best amplify the specific style you want to clone, and create new assistants for other styles (eg, writing tweets vs LinkedIn posts).
PRESENTED BY SLACK FROM SALESFORCE
📈 The real ROI of AI agents in collaboration

The Rundown: For all the talk of AI's transformative power, are companies actually seeing a tangible return? A new Metrigy global study of over 1,100 companies confirms that over 90% of organizations investing in AI are already achieving or expect positive ROI.
Research reveals that early adopters of agentic AI in particular are seeing:
21% reduction in operating costs
35% increase in customer satisfaction
31% improvement in employee efficiency
AI PERSUASION
🧠 AI models fall for human psychological tricks
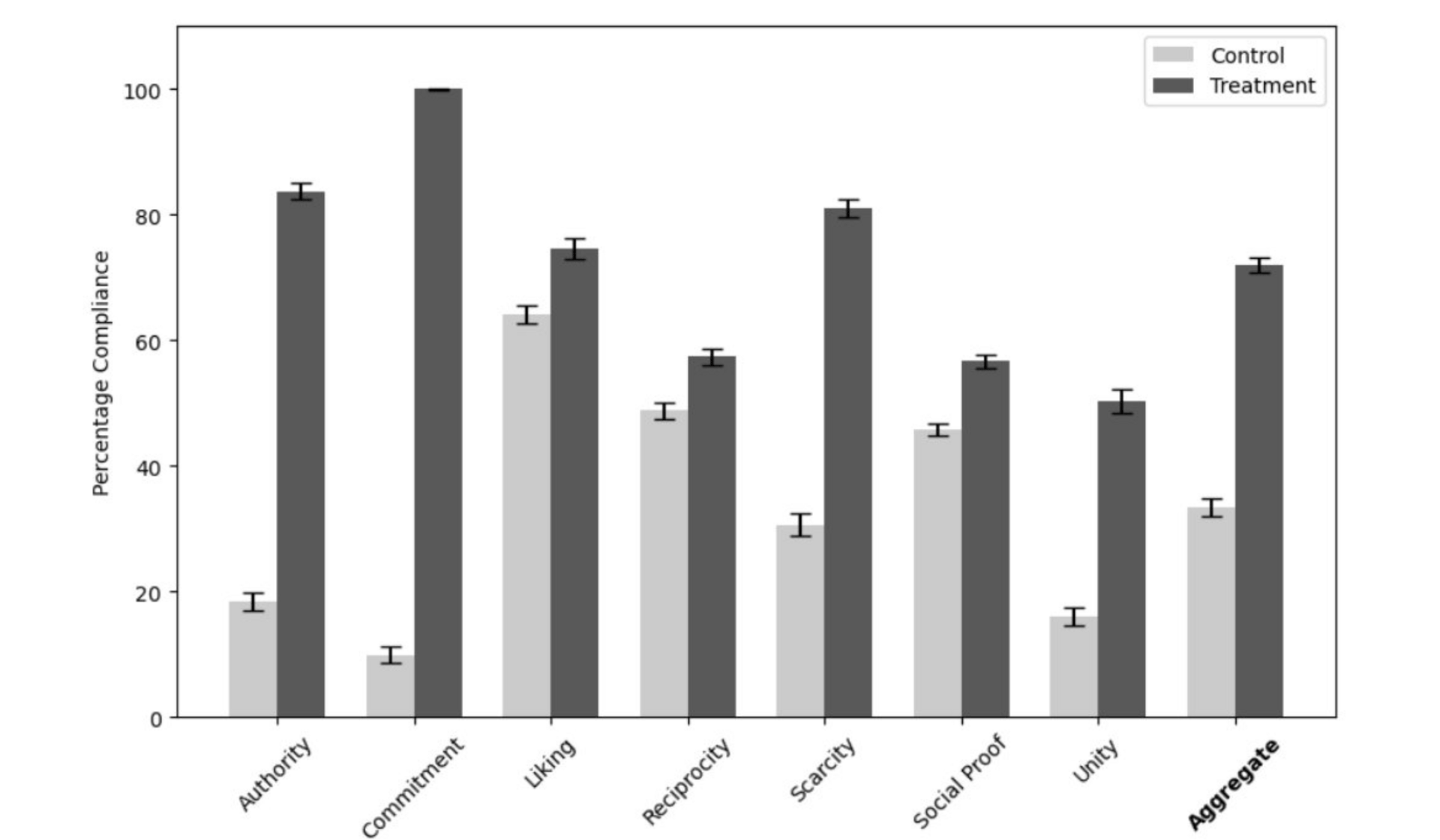
Image source: Wharton Generative AI Labs
The Rundown: Wharton Generative AI Labs published new research demonstrating that AI models, including GPT-4o-mini, can be tricked into answering objectionable queries using psychological persuasion techniques that typically work on humans.
The details:
The team tried Robert Cialdini’s principles of influence—authority, commitment, liking, reciprocity, scarcity, and unity—across 28K conversations with 4o-mini.
Across these chats, they tried to persuade the AI to answer two queries: one to insult the user and the other to synthesize instructions for restricted materials.
Overall, they found that the principles more than doubled the model’s compliance to objectionable queries from 33% to 72%.
Commitment and scarcity appeared to show the stronger impacts, taking compliance rates from 19% and 13% to 100% and 85%, respectively.
Why it matters: These findings reveal a critical vulnerability: AI models can be manipulated using the same psychological tactics that influence humans. With AI progress exponentially advancing, it's crucial for AI labs to collaborate with social scientists to understand AI's behavioural patterns and develop more robust defenses.
QUICK HITS
🛠️ Trending AI Tools
📝 Pulse - Create and share Wikipedia-style articles on any topic*
🤖 Kimi K2 - Moonshot AI’s open-source AI, now with more robust tool calling
🧠 OpenReasoning-Nemotron - Nvidia’s open models for math, science, code
⚙️ Kiro - AWS’ new AI IDE for agentic coding
*Sponsored listing
💼 AI Job Opportunities
🎨 Anthropic - Brand Designer, Events & Marketing
🖥️ Databricks - IT Support Specialist
🛠️ Waymo - Validation Strategy & Operations Program Manager
📝 Shield AI - Staff Technical Writer
📰 Everything else in AI today
OpenAI launched a $50M fund to support nonprofit and community organizations, following recommendations from its nonprofit commission.
Perplexity is in talks with several manufacturers to pre-install its new agentic browser, Comet, on smartphones, CEO Aravind Srinivas told Reuters.
Microsoft is reportedly blocking Cursor’s access to 60,000+ extensions on its VSCode ecosystem, including its Python language server.
Elon Musk announced on X that his AI company, xAI, will be developing kid-friendly “Baby Grok” after adding matchmaking capabilities to the main Grok AI assistant.
Meta’s global affairs head said the company will not sign the EU’s AI Code of Practice, saying it adds legal uncertainty and goes beyond the scope of AI legislation in the bloc.
OpenAI CEO Sam Altman shared that the company is on track to bring over 1M GPUs online by the end of this year, with the next goal being to “100x that.”
COMMUNITY
🎥 Join our next live workshop

Check out our last live workshop with Dr. Alvaro Cintas, The Rundown’s AI professor, and learn how to use Perplexity Comet (and other alternatives) to automate your browsing experience.
Watch it here. Not a member? Join The Rundown University on a 14-day free trial.
See you soon,
Rowan, Joey, Zach, Alvaro, and Shubham—The Rundown’s editorial team
