通义千问团队发布了Qwen3-30B-A3B-Thinking-2507这一重大升级模型,在推理能力、通用能力和上下文长度方面均有显著提升。新模型在数学能力(AIME25评测)和代码能力(LiveCodeBench v6)上表现优于Gemini2.5-Flash(thinking)和Qwen3-235B-A22B(thinking)。同时,其知识水平、写作、Agent能力、多轮对话和多语言指令遵循等通用能力也得到增强。新模型原生支持256K tokens,并可扩展至1M tokens,鼓励用户在复杂推理任务中设置更长的思考预算以充分发挥其潜力。该模型已在魔搭社区和HuggingFace开源,并同步上线Qwen Chat。
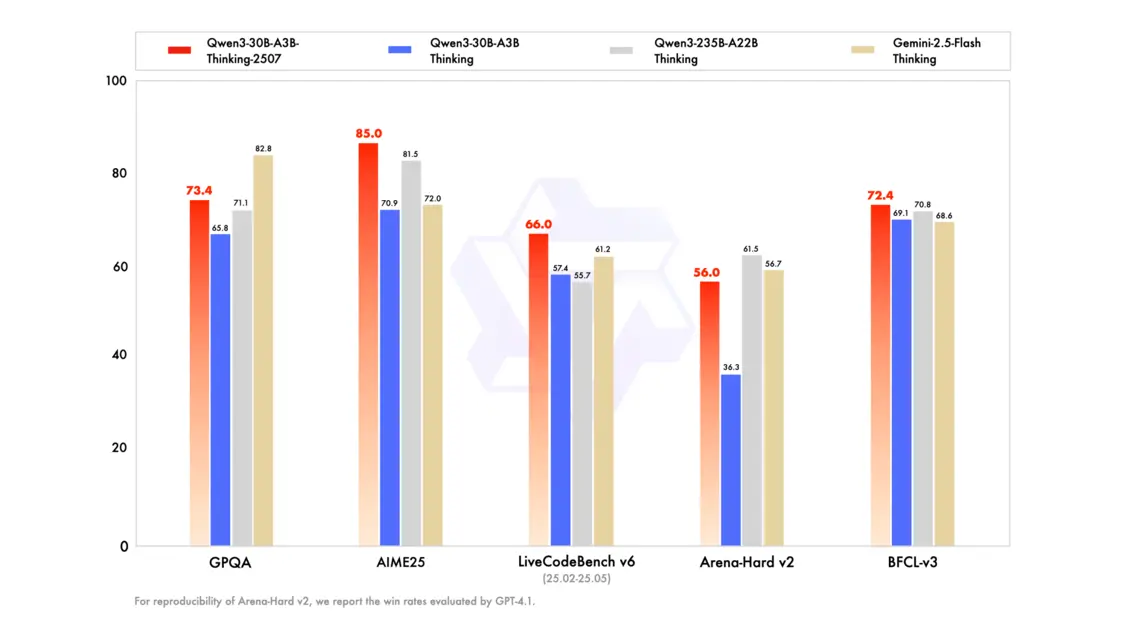
💡 **推理能力大幅跃升**:全新的Qwen3-30B-A3B-Thinking-2507模型在数学和代码这两项核心推理能力上取得了显著进步,在AIME25评测中获得85.0分,在LiveCodeBench v6中得分66.0,均超越了Gemini2.5-Flash(thinking)和Qwen3-235B-A22B(thinking),展现了更强的解决复杂问题的能力。
🌟 **通用能力全面增强**:除了推理能力,新模型在知识水平(GPQA、MMLU-Pro)、写作(WritingBench)、Agent能力(BFCL-v3)、多轮对话和多语言指令遵循(MultiIF)等通用能力评测中也表现出色,全面超越了同类模型,使其在更多场景下都能提供更优质的服务。
🚀 **超长上下文处理能力**:Qwen3-30B-A3B-Thinking-2507模型原生支持256K tokens的上下文长度,并且可以扩展至1M tokens。这一特性极大地拓展了模型处理长文本和复杂信息的能力,为用户在处理大量数据和长对话时提供了更多可能性。
🧠 **优化思考长度与预算**:团队特别指出,新模型增加了思考长度,并建议用户在处理高度复杂的推理任务时,设置更长的思考预算,以充分发挥新模型在深度思考和逻辑推理方面的潜力,获得更优的输出结果。
7月31日,通义千问团队在公众平台发布消息,Qwen3-30B实现重大升级,全新推理模型Qwen3-30B-A3B-Thinking-2507正式发布。新模型拓展了思考能力,提升了推理的质量和深度,是一个更睿智、更敏捷、更全能的新推理模型。

新模型在推理能力、通用能力及上下文长度上有了显著提升,新模型在聚焦数学能力的AIME25评测中获85.0分,在代码能力测试LiveCodeBench v6中得分66.0,两项核心推理能力均超越Gemini2.5-Flash(thinking)、Qwen3-235B-A22B(thinking);新模型的知识水平(GPQA、MMLU-Pro)也较上一版本进步显著;在写作(WritingBench)、Agent能力(BFCL-v3)、多轮对话和多语言指令遵循(MultiIF)等通用能力评测中,Qwen3-30B-A3B-Thinking-2507均超越Gemini2.5-Flash(thinking)、Qwen3-235B-A22B(thinking);原生支持256K tokens,可扩展至1M tokens。
值得一提的是,新模型的思考长度增加,团队建议在处理高度复杂的推理任务时,设置更长的思考预算,可以充分发挥新模型潜力。
目前Qwen3-30B-A3B-Thinking-2507已在魔搭社区、HuggingFace上开源,Qwen Chat同步上线。

