
Estimated reading time: 5 minutes
Table of contents
Introduction
Embodied AI agents are increasingly being called upon to interpret complex, multimodal instructions and act robustly in dynamic environments. ThinkAct, presented by researchers from Nvidia and National Taiwan University, offers a breakthrough for vision-language-action (VLA) reasoning, introducing reinforced visual latent planning to bridge high-level multimodal reasoning and low-level robot control.
Typical VLA models map raw visual and language inputs directly to actions through end-to-end training, which limits reasoning, long-term planning, and adaptability. Recent methods began to incorporate intermediate chain-of-thought (CoT) reasoning or attempt RL-based optimization, but struggled with scalability, grounding, or generalization when confronted with highly variable and long-horizon robotic manipulation tasks.
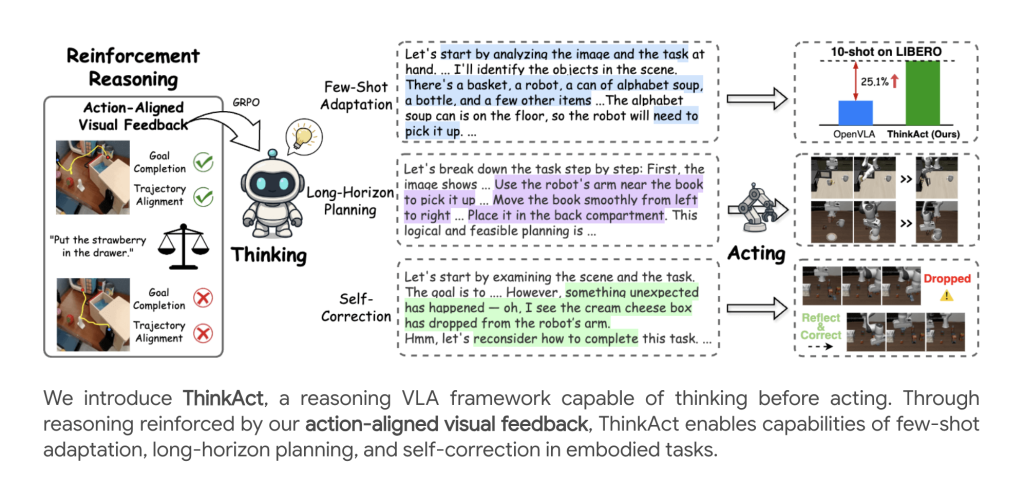
The ThinkAct Framework
Dual-System Architecture
ThinkAct consists of two tightly integrated components:
- Reasoning Multimodal LLM (MLLM): Performs structured, step-by-step reasoning over visual scenes and language instructions, outputting a visual plan latent that encodes high-level intent and planning context.Action Model: A Transformer-based policy conditioned on the visual plan latent, executing the decoded trajectory as robot actions in the environment.
This design allows asynchronous operation: the LLM “thinks” and generates plans at a slow cadence, while the action module carries out fine-grained control at higher frequency.
Reinforced Visual Latent Planning
A core innovation is the reinforcement learning (RL) approach leveraging action-aligned visual rewards:
- Goal Reward: Encourages the model to align the start and end positions predicted in the plan with those in demonstration trajectories, supporting goal completion.Trajectory Reward: Regularizes the predicted visual trajectory to closely match distributional properties of expert demonstrations using dynamic time warping (DTW) distance.
Total reward rrr blends these visual rewards with a format correctness score, pushing the LLM to not only produce accurate answers but also plans that translate into physically plausible robot actions.
Training Pipeline
The multi-stage training procedure includes:
- Supervised Fine-Tuning (SFT): Cold-start with manually-annotated visual trajectory and QA data to teach trajectory prediction, reasoning, and answer formatting.Reinforced Fine-Tuning: RL optimization (using Group Relative Policy Optimization, GRPO) further incentivizes high-quality reasoning by maximizing the newly defined action-aligned rewards.Action Adaptation: The downstream action policy is trained using imitation learning, leveraging the frozen LLM’s latent plan output to guide control across varied environments.
Inference
At inference time, given an observed scene and a language instruction, the reasoning module generates a visual plan latent, which then conditions the action module to execute a full trajectory—enabling robust performance even in new, previously unseen settings.

Experimental Results
Robot Manipulation Benchmarks
Experiments on SimplerEnv and LIBERO benchmarks demonstrate ThinkAct’s superiority:
- SimplerEnv: Outperforms strong baselines (e.g., OpenVLA, DiT-Policy, TraceVLA) by 11–17% in various settings, especially excelling in long-horizon and visually diverse tasks.LIBERO: Achieves the highest overall success rates (84.4%), excelling in spatial, object, goal, and long-horizon challenges, confirming its ability to generalize and adapt to novel skills and layouts.

Embodied Reasoning Benchmarks
On EgoPlan-Bench2, RoboVQA, and OpenEQA, ThinkAct demonstrates:
- Superior multi-step and long-horizon planning accuracy.State-of-the-art BLEU and LLM-based QA scores, reflecting improved semantic understanding and grounding for visual question answering tasks.
Few-Shot Adaptation
ThinkAct enables effective few-shot adaptation: with as few as 10 demonstrations, it achieves substantial success rate gains over other methods, highlighting the power of reasoning-guided planning for quickly learning new skills or environments.
Self-Reflection and Correction
Beyond task success, ThinkAct exhibits emergent behaviors:
- Failure Detection: Recognizes execution errors (e.g., dropped objects).Replanning: Automatically revises plans to recover and complete the task, thanks to reasoning on recent visual input sequences.
Ablation Studies and Model Analysis
- Reward Ablations: Both goal and trajectory rewards are essential for structured planning and generalization. Removing either significantly drops performance, and relying only on QA-style rewards limits multi-step reasoning capability.Reduction in Update Frequency: ThinkAct achieves a balance between reasoning (slow, planning) and action (fast, control), allowing robust performance without excessive computational demand1.Smaller Models: The approach generalizes to smaller MLLM backbones, maintaining strong reasoning and action capabilities.
Implementation Details
- Main backbone: Qwen2.5-VL 7B MLLM.Datasets: Diverse robot and human demonstration videos (Open X-Embodiment, Something-Something V2), plus multimodal QA sets (RoboVQA, EgoPlan-Bench, Video-R1-CoT, etc.).Uses a vision encoder (DINOv2), text encoder (CLIP), and a Q-Former for connecting reasoning output to action policy input.Extensive experiments on real and simulated settings confirm scalability and robustness.
Conclusion
Nvidia’s ThinkAct sets a new standard for embodied AI agents, proving that reinforced visual latent planning—where agents “think before they act”—delivers robust, scalable, and adaptive performance in complex, real-world reasoning and robot manipulation tasks. Its dual-system design, reward shaping, and strong empirical results pave the way for intelligent, generalist robots capable of long-horizon planning, few-shot adaptation, and self-correction in diverse environments.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
You may also like NVIDIA’s Open Sourced Cosmos DiffusionRenderer [Check it now]
The post NVIDIA AI Presents ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning appeared first on MarkTechPost.
