AMD锐龙AI Max+ 395平台近日迎来重大升级,现已支持本地运行1280亿参数大模型,刷新了AI大模型在本地运行的纪录。通过搭配128GB统一内存并分配96GB作为显存,在Vulkan llama.cpp环境和测试版驱动下,该平台成功运行了1090亿参数的Meta Llama 4 Sout大模型,实现每秒15 Tokens的性能。此外,它还能流畅运行Mistral Large等多种大型模型,并支持更大的上下文窗口(最高256000 Tokens),极大提升了处理大规模数据文档的能力。这一升级使得高性能AI计算更加普惠,且价格极具竞争力。
🚀 **本地大模型运行新标杆:** AMD锐龙AI Max+ 395平台在升级后,能够支持本地运行高达1280亿参数的大型AI模型,这标志着个人设备在处理复杂AI任务方面迈出了重要一步。
💡 **核心技术与配置要求:** 实现这一能力的关键在于搭配128GB统一内存,并将其中96GB分配给显存。同时,需要依赖Vulkan llama.cpp环境和最新的测试版驱动(25.10 RC 24),这些软硬件的协同工作是本地运行超大模型的基础。
🌐 **模型兼容性与性能表现:** 该平台不仅能运行66GB的Meta Llama 4 Sout(1090亿参数),实测速度可达每秒15 Tokens,还支持Mistral Large(1230亿参数)以及Qwen3 A3B(300亿参数)、Google Gemma(270亿参数)等多种模型,并兼容GGUF等量化格式。
📚 **超大上下文窗口能力:** 锐龙AI Max+ 395在上下文处理能力上实现了惊人飞跃,支持高达256000 Tokens的上下文长度,远超传统水平,这使得分析和汇总海量文档等数据任务成为可能,而此前通常需要高端服务器集群才能实现。
💰 **高性价比的AI工作站:** 搭载128GB内存的锐龙AI Max+ 395迷你AI工作站,价格已降至约1.3万元人民币,为用户提供了极高的性价比,使得先进的AI计算能力更加触手可及。
AMD Zen5架构的锐龙AI Max+ 395,是第一个可以在本地运行700亿参数AI大模型的平台,当然需要搭配128GB统一内存,而现在,AMD奉上重磅升级,1280亿参数大模型都可以在本地运行了!
当然,能做到这一点的还是只有锐龙AI Max+ 395,还是必须搭配128GB统一内存,并分配96GB作为显存,而且必须在Vulkan llama.cpp环境下。
驱动方面需要搭配还在测试阶段的25.10 RC 24版本,下个月初将会变成正式版25.8.1。


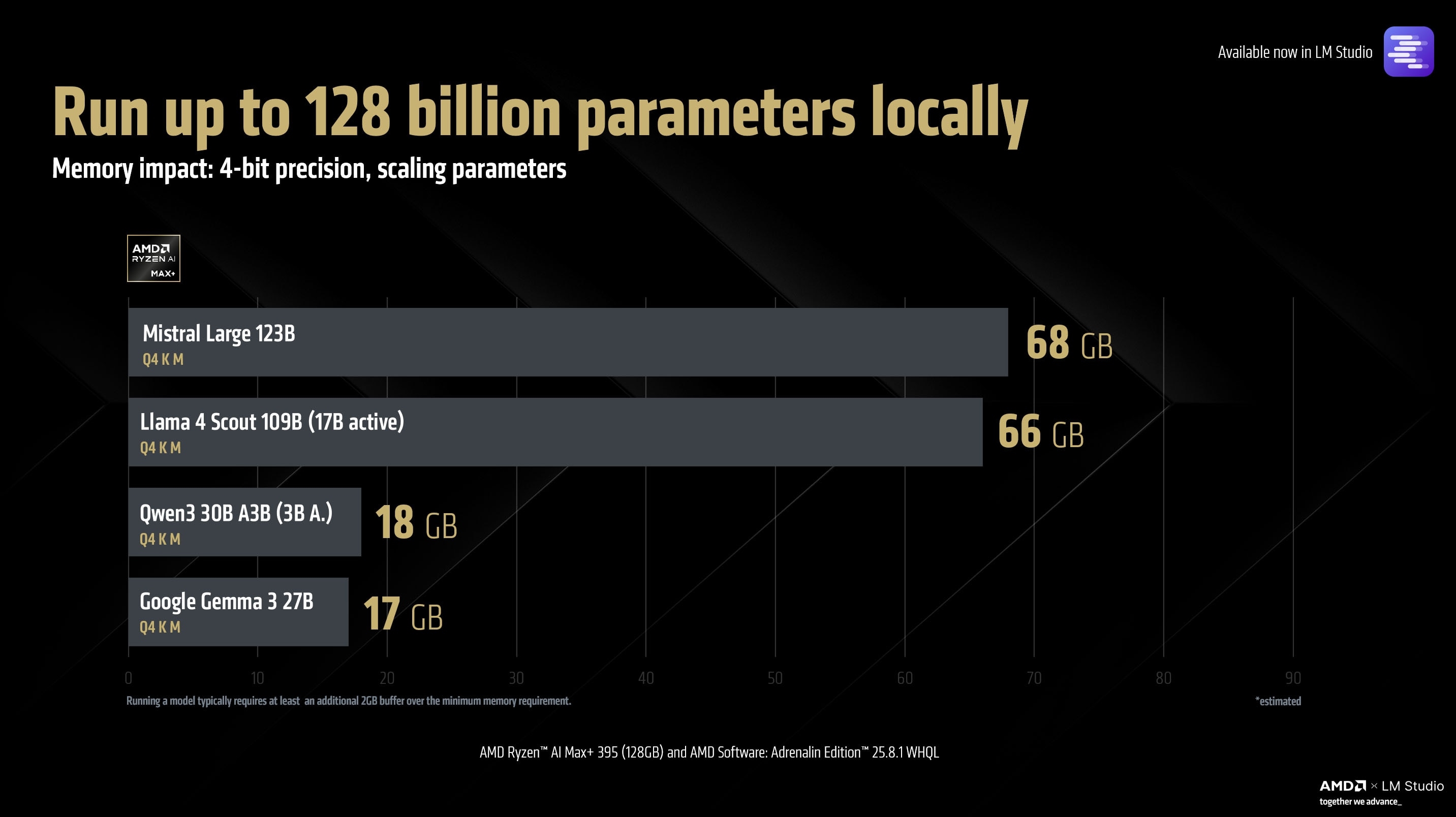
这使得锐龙AI Max+ 395成为第一个能在本地运行1090亿参数的Meta Llama 4 Sout大模型的平台,体积多达66GB,活跃参数最多170亿,并支持Vision、MCP。
这得益于该模型使用了混合专家(MoE)模式,每次只激活模型的一部分,从而保持性能可用,锐龙AI Max+ 395实测可以做到每秒15 Tokens。
同时,锐龙AI Max+ 395还可以跑68GB体积、1230亿参数的Mistral Large,至于18GB、300亿参数的Qwen3 A3B、17GB、270亿参数的Google Gemma,自然更是不在话下。
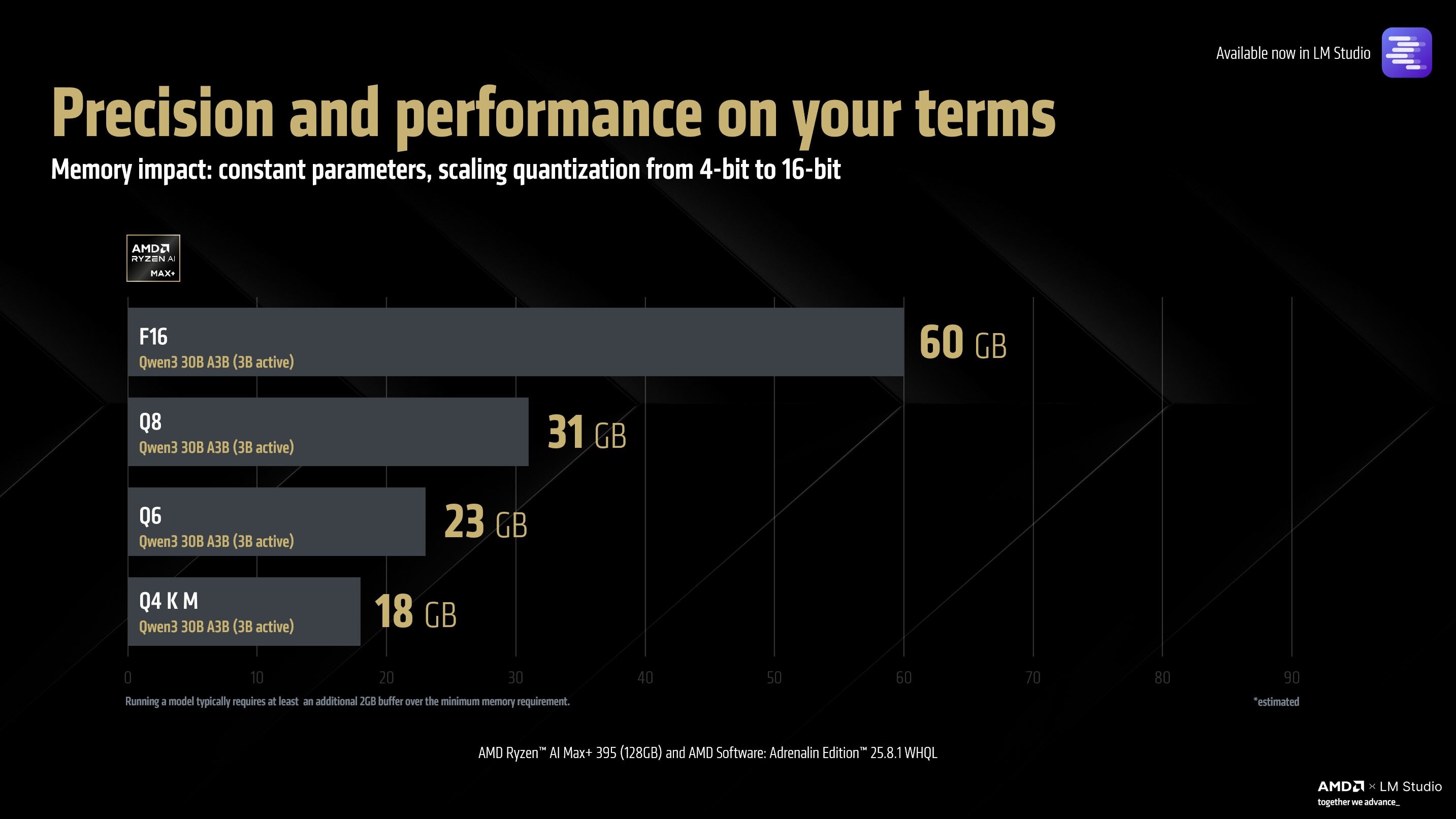
当然,锐龙AI Max+ 395还支持各种各样的模型尺寸、量化格式,包括GGUF。



同样重要的是,锐龙AI Max+ 395升级支持了更大的上下文尺寸,从传统的4096 Tokens左右,一举来到了惊人的256000 Tokens,从而能够分析、汇总更大规模的文档等数据资料。
不过这里需要注意,得开启Flash Attention、Q8 KV Cache。
对于一般的非大规模模型,32000 Tokens的上下文就足够用了,锐龙AI Max+ 395则提供了新的可能,而以往如此超大规模的上下文,往往需要几万十几万的设备才能实现。
锐龙AI Max+ 395、128GB配置的迷你AI工作站,价格已经低至1.3万元左右,可以说性价比是相当高了。


查看评论










